
-
4.8 可靠性指标
-
可靠性(Availability),或者说可用性,是描述系统可以提供服务能力的重要指标。高可靠的分布式系统,往往需要各种复杂的机制来进行保障。
通常情况下,服务的可用性可以用服务承诺(Service Level Agreement,SLA SLA)、服务指标(Service Level Indicator,SLI)、服务目标(Service Level Objective,SLO)等方面进行衡量。
几个 9 的指标
完美的可靠性是不存在的。很多领域里谈到服务的高可靠性,通常都会用“几个 9”的指标来进行衡量。
“几个 9”的指标,其实是概率意义上粗略反映了系统能提供服务的可靠性指标,最初是电信领域提出的概念。
下表给出不同指标下,每年允许服务出现不可用时间的参考值。
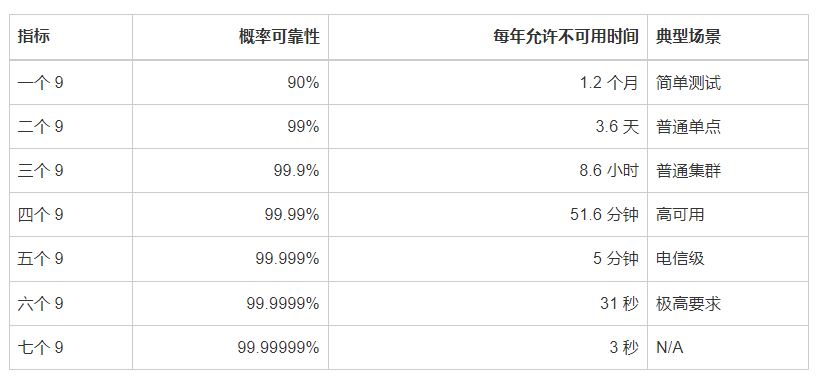
一般来说,单点的服务器系统至少应能满足两个 9;普通企业信息系统三个 9 就肯定足够了(大家可以统计下自己企业内因系统维护每年要停多少时间),系统能达到四个 9 已经是领先水平了(参考 AWS 等云计算平台)。电信级的应用一般需要能达到五个 9,这已经很厉害了,一年里面最多允许出现五分钟左右的服务不可用。六个 9 以及以上的系统,就更加少见了,要实现往往意味着极高的代价。
两个核心时间
一般地,描述系统出现故障的可能性和故障出现后的恢复能力,有两个基础的指标:MTBF 和 MTTR。
MTBF:Mean Time Between Failures,平均故障间隔时间,即系统可以无故障运行的预期时间。
MTTR:Mean Time To Repair,平均修复时间,即发生故障后,系统可以恢复到正常运行的预期时间。
MTBF 衡量了系统发生故障的频率,如果一个系统的 MTBF 很短,则往往意味着该系统可用性低;而 MTTR 则反映了系统碰到故障后服务的恢复能力,如果系统的 MTTR 过长,则说明系统一旦发生故障,需要较长时间才能恢复服务。
一个高可用的系统应该是具有尽量长的 MTBF 和尽量短的 MTTR。
提高可靠性
那么,该如何提升可靠性呢?有两个基本思路:一是让系统中的单个组件都变得更可靠;二是干脆消灭单点。
IT 从业人员大都有类似的经验,普通笔记本电脑,基本上是过一阵可能就要重启下;而运行 Linux/Unix 系统的专用服务器,则可能连续运行几个月甚至几年时间都不出问题。另外,普通的家用路由器,跟生产级别路由器相比,更容易出现运行故障。这些都是单个组件可靠性不同导致的例子,可以通过简单升级单点的软硬件来改善可靠性。
然而,依靠单点实现的可靠性毕竟是有限的。要想进一步的提升,那就只好消灭单点,通过主从、多活等模式让多个节点集体完成原先单点的工作。这可以从概率意义上改善服务对外整体的可靠性,这也是分布式系统的一个重要用途。
- 留下你的读书笔记
- 你还没登录,点击这里
-
用户笔记留言