

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

我,心里默默立下决心:“……”
MPFR主要用于处理高精度小数,功能更为丰富,提供超过300个MPFR库函数。
sudo apt-get install libmpfr-dev最后,所有的Windows动态库包都是由我自己使用vcpkg编译的,而Linux动态库包则来自Ubuntu 22.04。因此,如果你使用我的动态库包,可能主要只支持Ubuntu 22.04和Debian。
// 堆代码 duidaima.com
Stopwatch sw = Stopwatch.StartNew();
int count = 10;
BigInteger b = new BigInteger();
for (int c = 0; c < count; ++c)
{
b = 1;
for (int i = 1; i <= 65536; ++i)
{
b *= 2;
}
}
Console.WriteLine($"耗时:{sw.Elapsed.TotalMilliseconds / count:F2}ms");
Console.WriteLine($"2^65536最后20位数字:{b.ToString()[^20..]}");
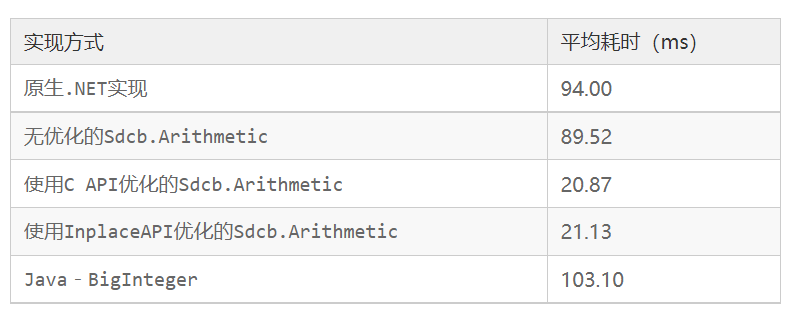
在我的i9-9880h电脑上,这个程序的运行结果如下:耗时:94.00ms 2^65536最后20位数字:45587895905719156736
Stopwatch sw = Stopwatch.StartNew();
int count = 10;
GmpInteger b = new GmpInteger();
for (int c = 0; c < count; ++c)
{
b = 1;
for (int i = 1; i <= 65536; ++i)
{
b *= 2;
}
}
Console.WriteLine($"耗时:{sw.Elapsed.TotalMilliseconds / count:F2}ms");
Console.WriteLine($"2^65536最后20位数字:{b.ToString()[^20..]}");
运行结果如下:耗时:89.52ms 2^65536最后20位数字:45587895905719156736可以看到,Sdcb.Arithmetic.Gmp的结果与.NET原生实现相匹配,并且计算速度相近。
// 安装NuGet包:Sdcb.Arithmetic.Gmp
// 安装NuGet包:Sdcb.Arithmetic.Gmp.runtime.win64 (或其它对应环境包)
// 函数需要标注unsafe
// 项目需要启用unsafe编译选项
Stopwatch sw = Stopwatch.StartNew();
int count = 10;
Mpz_t mpz;
GmpLib.__gmpz_init((IntPtr)(&mpz));
for (int c = 0; c < count; ++c)
{
GmpLib.__gmpz_set_si((IntPtr)(&mpz), 1);
for (int i = 1; i <= 65536; ++i)
{
GmpLib.__gmpz_mul_si((IntPtr)(&mpz), (IntPtr)(&mpz), 2);
}
}
sw.Stop();
IntPtr ret = GmpLib.__gmpz_get_str(IntPtr.Zero, 10, (IntPtr)(&mpz));
string wholeStr = Marshal.PtrToStringUTF8(ret)!;
GmpMemory.Free(ret);
Console.WriteLine($"耗时:{sw.Elapsed.TotalMilliseconds / count:F2}ms");
Console.WriteLine($"2^65536最后20位数字:{wholeStr[^20..]}");
GmpLib.__gmpz_clear((IntPtr)(&mpz));
在同一台电脑上,输出结果如下:耗时:20.87ms 2^65536最后20位数字:45587895905719156736你可以参考下面的源代码了解我是如何封装PInvoke API的:
// 安装NuGet包:Sdcb.Arithmetic.Gmp
// 安装NuGet包:Sdcb.Arithmetic.Gmp.runtime.win64 (或其它对应环境包)
Stopwatch sw = Stopwatch.StartNew();
int count = 10;
using GmpInteger b = new GmpInteger();
for (int c = 0; c < count; ++c)
{
b.Assign(1);
for (int i = 1; i <= 65536; ++i)
{
GmpInteger.MultiplyInplace(b, b, 2);
}
}
Console.WriteLine($"耗时:{sw.Elapsed.TotalMilliseconds / count:F2}ms");
Console.WriteLine($"2^65536最后20位数字:{b.ToString()[^20..]}");
运行结果如下:耗时:21.13ms 2^65536最后20位数字:45587895905719156736可见代码相比最开始的和如下变化:
import java.math.BigInteger;
import java.time.Duration;
import java.time.Instant;
public class Main {
public static void main(String[] args) {
Instant start = Instant.now();
int count = 10;
BigInteger b = BigInteger.ONE;
for (int c = 0; c < count; ++c) {
b = BigInteger.ONE;
for (int i = 1; i <= 65536; ++i) {
b = b.multiply(BigInteger.valueOf(2));
}
}
Instant finish = Instant.now();
long timeElapsed = Duration.between(start, finish).toMillis();
String str = b.toString();
String last20Digits = str.substring(str.length() - 20);
System.out.printf("耗时:%f ms\n", (double) timeElapsed / count);
System.out.println("2^65536最后20位数字:" + last20Digits);
}
}
我使用的Java版本是OpenJDK version "11.0.16.1" 2022-08-12 LTS,使用相同的电脑,输出结果如下:耗时:103.100000 ms 2^65536最后20位数字:45587895905719156736可见速度比.NET原生的BigInteger稍慢。
// Install NuGet package: Sdcb.Arithmetic.Gmp
// Install NuGet package: Sdcb.Arithmetic.Gmp.runtime.win-x64(for windows)
using Sdcb.Arithmetic.Gmp;
Stopwatch sw = Stopwatch.StartNew();
using GmpFloat pi = CalcPI();
double elapsed = sw.Elapsed.TotalMilliseconds;
Console.WriteLine($"耗时:{elapsed:F2}ms");
Console.WriteLine($"结果:{pi:N1000000}");
GmpFloat CalcPI(int inputDigits = 1_000_000)
{
const double DIGITS_PER_TERM = 14.1816474627254776555; // = log(53360^3) / log(10)
int DIGITS = (int)Math.Max(inputDigits, Math.Ceiling(DIGITS_PER_TERM));
uint PREC = (uint)(DIGITS * Math.Log2(10));
int N = (int)(DIGITS / DIGITS_PER_TERM);
const int A = 13591409;
const int B = 545140134;
const int C = 640320;
const int D = 426880;
const int E = 10005;
const double E3_24 = (double)C * C * C / 24;
using PQT pqt = ComputePQT(0, N);
GmpFloat pi = new(precision: PREC);
// pi = D * sqrt((mpf_class)E) * PQT.Q;
pi.Assign(GmpFloat.From(D, PREC) * GmpFloat.Sqrt((GmpFloat)E, PREC) * (GmpFloat)pqt.Q);
// pi /= (A * PQT.Q + PQT.T);
GmpFloat.DivideInplace(pi, pi, GmpFloat.From(A * pqt.Q + pqt.T, PREC));
return pi;
PQT ComputePQT(int n1, int n2)
{
int m;
if (n1 + 1 == n2)
{
PQT res = new()
{
P = GmpInteger.From(2 * n2 - 1)
};
GmpInteger.MultiplyInplace(res.P, res.P, 6 * n2 - 1);
GmpInteger.MultiplyInplace(res.P, res.P, 6 * n2 - 5);
GmpInteger q = GmpInteger.From(E3_24);
GmpInteger.MultiplyInplace(q, q, n2);
GmpInteger.MultiplyInplace(q, q, n2);
GmpInteger.MultiplyInplace(q, q, n2);
res.Q = q;
GmpInteger t = GmpInteger.From(B);
GmpInteger.MultiplyInplace(t, t, n2);
GmpInteger.AddInplace(t, t, A);
GmpInteger.MultiplyInplace(t, t, res.P);
// res.T = (A + B * n2) * res.P;
if ((n2 & 1) == 1) GmpInteger.NegateInplace(t, t);
res.T = t;
return res;
}
else
{
m = (n1 + n2) / 2;
PQT res1 = ComputePQT(n1, m);
using PQT res2 = ComputePQT(m, n2);
GmpInteger p = res1.P * res2.P;
GmpInteger q = res1.Q * res2.Q;
// t = res1.T * res2.Q + res1.P * res2.T
GmpInteger.MultiplyInplace(res1.T, res1.T, res2.Q);
GmpInteger.MultiplyInplace(res1.P, res1.P, res2.T);
GmpInteger.AddInplace(res1.T, res1.T, res1.P);
res1.P.Dispose();
res1.Q.Dispose();
return new PQT
{
P = p,
Q = q,
T = res1.T,
};
}
}
}
public ref struct PQT
{
public GmpInteger P;
public GmpInteger Q;
public GmpInteger T;
public readonly void Dispose()
{
P?.Dispose();
Q?.Dispose();
T?.Dispose();
}
}
在我的i9-9880h电脑中,输出如下(100万位中间有...省略):耗时:435.35ms 结果:3.141592653589793238462643383...83996346460422090106105779458151可见速度是非常快的,100万位π的值可以在这个链接进行参考。
**** PI Computation ( 1000000 digits ) TIME (COMPUTE): 0.425 seconds. TIME (WRITE) : 0.103 seconds.我也参考了Github上另一段用C写的同样计算100万位π的代码:https://github.com/natmchugh/pi/blob/master/gmp-chudnovsky.c
#terms=70513, depth=18 sieve time = 0.003 .................................................. bs time = 0.265 gcd time = 0.000 div time = 0.037 sqrt time = 0.022 mul time = 0.014 total time = 0.343 P size=1455608 digits (1.455608) Q size=1455601 digits (1.455601)这是3种编程语言计算100万位π耗时的比较表格:
|
|
耗时(ms) |
|---|---|
| C# | 435.35 |
| C++ | 425 |
| C | 343 |




