Kafka是一个能够支持高并发以及流式消息处理的消息中间件,并且Kafka天生就是支持集群的,今天就主要来介绍一下如何搭建Kafka集群。
Kafka目前支持使用Zookeeper模式搭建集群以及KRaft模式(即无Zookeeper)模式这两种模式搭建集群,这两种模式各有各的好处,今天就来分别介绍一下这两种方式。
1,Kafka集群中的节点类型
我们首先需要了解一下,在一个Kafka集群中是由两种类型的节点构成的,即Controller和Broker,这两类节点充当着不同的作用:
Broker 即代理节点,是Kafka中的工作节点,充当消息队列的角色,负责储存和处理消息,每个Broker都是一个独立的Kafka服务器,可以在不同的机器上运行,除此之外Broker还负责分区(partition)的管理,将主题(topic)划分为多个分区,并分布在集群的不同Broker上
Controller 即控制器节点,是集群中的特殊节点,负责储存和管理整个集群元数据和状态,它能够监控整个集群中的Broker,在需要时还能够进行平衡操作
大家只需了解集群中的两类节点作用即可。
2,两种模式集群的搭建方式
接下来,我就来介绍一下两种模式的集群架构和搭建方式,即Zookeeper模式集群和KRaft模式集群。
(1) Zookeeper模式集群
这是一种比较简单,相对“传统”的搭建方式了!在这种模式下,每个Kafka节点都是依赖于Zookeeper的,使用Zookeeper存储集群中所有节点的元数据。
只要所有的Kafka节点连接到同一个Zookeeper上面(或者同一个Zookeeper集群),这些Kafka节点就构成了一个集群。所以说就算是只有一个Kafka节点在运行,这一个节点也可以称作一个集群。
在Zookeeper模式集群中,Zookeeper节点(或者集群)就充当了Controller的角色,而所有的Kafka节点就充当着Broker的角色。
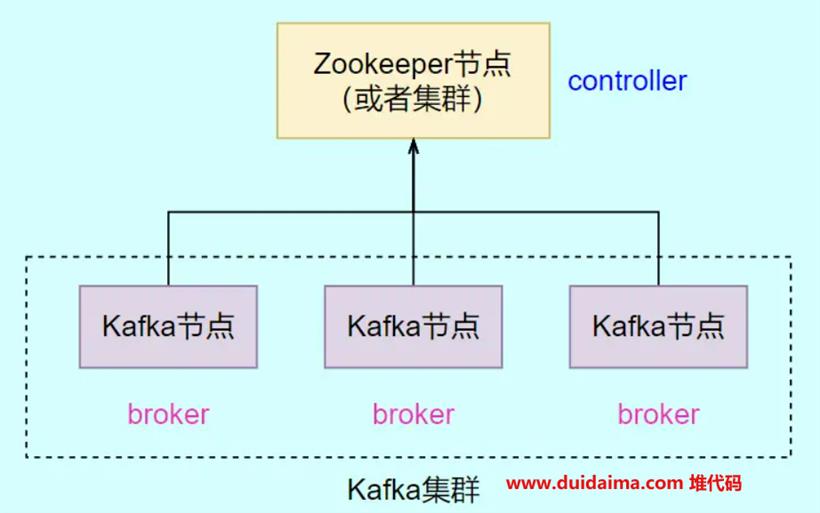
下面就来介绍一下搭建过程,这里我在4台Linux虚拟机上分别运行Zookeeper和Kafka来模拟一个集群,一共一个Zookeeper节点和三个Kafka节点构成,如下:
|
节点名
|
地址和端口
|
|
Zookeeper节点
|
zookeeper:2181
|
|
Kafka节点1
|
kafka1:9092
|
|
Kafka节点2
|
kafka2:9092
|
|
Kafka节点3
|
kafka3:9092
|
上述地址例如kafka1等等,是通过修改虚拟机的主机名(hostname)实现的,这样虚拟机之间可以直接通过这些主机名相互访问,这个主机名我们就可以视作实际在服务器上面搭建时,服务器的外网地址或者域名,这里就不再赘述如何修改虚拟机的主机名了,需要保证上述所有虚拟机在一个虚拟机网段中并且能够互相ping通,即上述所有虚拟机需要两两之间可以通过网络互相访问。
运行Kafka和Zookeeper都需要Java 8及其以上运行环境,大家要首先在虚拟机中安装并配置好。
① 搭建Zookeeper
首先我们要运行起一个Zookeeper节点,这里就不再赘述Zookeeper节点如何搭建了!搭建可以查看官方文档,或者使用Docker的方式搭建。
搭建完成并运行Zookeeper之后,我们会把所有的Kafka节点都配置到这一个Zookeeper节点上。
② 配置并运行所有Kafka节点
首先去Kafka官网下载最新版并解压,然后将解压出来的Kafka分别复制到三台虚拟机中。
然后修改每台虚拟机的Kafka目录中的配置文件,配置文件位于解压的Kafka文件夹中的config/server.properties,使用文本编辑器打开,并找到下列配置项进行配置:
broker.id 表示每个节点的id,每个节点需要设置为不一样的整数,我这里分别设置为1,2和3
zookeeper.connect 表示要使用的Zookeeper的地址和端口,我这里都配置为zookeeper:2181
advertised.listeners 表示这个Kafka节点的外网地址,这里分别配置为PLAINTEXT://kafka1:9092,PLAINTEXT://kafka2:9092和PLAINTEXT://kafka3:9092,需要注意的是这个配置项必须要配置为其所在服务器的外网地址,如果说你是在一台服务器上面配置Kafka并要通过外网访问,这个配置就需要配置为服务器外网地址(域名),并且都以PLAINTEXT://开头
注意上述advertised.listeners这个配置项默认情况下是被注释掉了的,大家需要去仔细找一下并去掉注释(开头的#)然后再进行配置。
三台虚拟机配置完成后,分别使用终端进入到Kafka目录下并启动,执行下列命令:
bin/kafka-server-start.sh config/server.properties
在上述三台虚拟机上面都通过这个命令启动Kafka,如图则启动成功:
到此,整个集群就搭建完成了!大家需要保证上述三台虚拟机中的终端不被关闭。
③ 创建话题测试
我们先在kafka1的虚拟机上面再开一个终端并进入Kafka目录,执行下列命令创建Topic:
bin/kafka-topics.sh --create --topic my-topic --bootstrap-server localhost:9092
然后去kafka2的虚拟机上面再开一个终端并进入Kafka目录,执行下列命令列出Topic:
bin/kafka-topics.sh --list --bootstrap-server localhost:9092
可见我们在第一个节点上创建了话题,但是在第二个节点上仍然可以获取这个话题,说明集群创建成功,数据在集群之间可以共享。
(2) KRaft模式集群
在上述传统方案中,Kafka需要依赖Zookeeper完成元数据存放和共享,这样也就暴露出了一些问题:
.搭建Kafka集群时还需要额外搭建Zookeeper,增加了运维成本
.Zookeeper是强一致性的组件(符合CP理论),如果集群中数据发生变化,那么必须要等到其它节点都同步,至少超过一半同步完成,这样节点数多性能差
那么KRaft模式是新版本Kafka中推出的集群模式,这种模式下就完全不需要Zookeeper了!只需要数个Kafka节点就可以直接构成集群,在这时集群中的Kafka节点既有可能是Controller节点也可能是Broker节点,我们可以让Kafka节点自动选取,也可以在配置文件手动配置。
同样地,就算是你只是搭建了一个Kafka节点,这一个节点也仍然被视为一个Kafka集群。
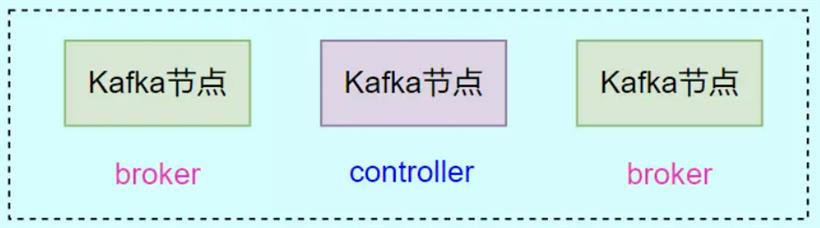
下面同样是开启三台虚拟机,搭建三个Kafka节点构成的KRaft模式集群如下:
|
节点名
|
地址和端口
|
|
Kafka节点1
|
kafka1:9092
|
|
Kafka节点2
|
kafka2:9092
|
|
Kafka节点3
|
kafka3:9092
|
这里就不再赘述下载Kafka的过程了!
① 修改配置文件
在KRaft模式下,配置文件位于Kafka目录中的config/kraft/server.properties,使用文本编辑器打开并找到下列配置以修改:
node.id 表示这个节点的id,一个集群中每个节点id不能重复,需要是不小于1的整数,这里三台虚拟机的配置分别为1,2和3(类似上述Zookeeper的broker.id配置)
controller.quorum.voters 设定投票者列表,即需要配置所有的节点id和Controller地址端口,配置格式为节点1的id@节点1地址:节点1端口,节点2的id@节点2地址:节点2端口,节点3的id@节点3地址:节点3端口,多个节点之间用英文逗号,隔开,Controller端口默认都是9093,是节点之间自动投票选取Controller的通信端口,默认不需要修改,这里了解即可,我这里三台虚拟机的都配置为1@kafka1:9093,2@kafka2:9093,3@kafka3:9093(实际在服务器上搭建时替换为服务器的外网地址或者域名)
advertised.listeners 表示这个Kafka节点的外网地址,这里分别配置为PLAINTEXT://kafka1:9092,PLAINTEXT://kafka2:9092和PLAINTEXT://kafka3:9092(和上述Zookeeper模式中的一样,实际在服务器上搭建时替换为服务器的外网地址或者域名)
上述是必须要进行配置的,还有下面配置是可以选择性配置的:
process.roles 表示设定这个节点的类型,设定为broker表示设定这个节点为Broker节点,同样地设定controller表示设定为Controller节点,默认是broker,controller表示这个节点会自动切换节点类型,这里就保持默认不变
② 生成集群ID并使用集群ID格式化数据目录
在KRaft模式下,一个集群需要设定一个id,我们可以使用自带的命令生成,先进入上述任意一台虚拟机并使用终端进入Kafka目录中,执行下列命令生成一个UUID:
bin/kafka-storage.sh random-uuid

我们这里记录下这个ID以备用。
备注:这个集群ID事实上是一个长度16位的字符串通过Base64编码后得来的,因此你也可以不使用上述命令,直接自定义一个16位长度的纯英文和数字组成的字符串,然后将这个字符串编码为Base64格式作为这个集群ID也可以。可以使用菜鸟工具中的在线Base64编码工具。
然后在上述三台虚拟机中,都使用终端进入Kafka目录后,执行下列命令:
bin/kafka-storage.sh format -t 生成的集群ID -c config/kraft/server.properties
这样,三个Kafka节点都使用了这一个ID完成了集群元数据配置,表示这三个Kafka节点构成一个集群。
③ 启动Kafka
同样地,在三台虚拟机中,都使用终端进入Kafka目录后,执行下列命令:
bin/kafka-server-start.sh config/kraft/server.properties
三台虚拟机全部启动后,这个集群才启动完毕。
④ 创建话题测试
同样地,现在第一个虚拟机的Kafka目录下执行下列命令:
bin/kafka-topics.sh --create --topic my-topic-kraft --bootstrap-server localhost:9092
然后在第二个虚拟机的Kafka目录下查看话题:
bin/kafka-topics.sh --list --bootstrap-server localhost:9092
可见集群节点之间可以互相通信。
3,常用配置介绍
除了上述我们涉及到的一些配置之外,还有下列配置大家可以进行修改:
socket.send.buffer.bytes 每次发送的数据包的最大大小(单位:字节)
socket.receive.buffer.bytes 每次接收的数据包的最大大小(单位:字节)
socket.request.max.bytes 接收的最大请求大小(单位:字节)
num.partitions 每个Topic的默认分区数
上述无论是哪个模式的集群,都可以在配置文件中找到这些配置,如果找不到可手动加入。除了修改配置文件之外,我们还可以在启动Kafka的命令中指定配置和值,例如:
bin/kafka-server-start.sh config/server.properties --override zookeeper.connect=127.0.0.1:2181 --override broker.id=1
上述命令在启动时通过命令指定了zookeeper.connect配置值为127.0.0.1:2181,以及broker.id为1,可见在后面追加--override 配置名=值即可,注意命令行中指定的配置值会覆盖掉配置文件中的配置值!


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






