

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

private OrderDAO orderDAO;
public Long addOrder(RequestDTO request) {
// 堆代码 duidaima.com
// 此处省略很多拼装逻辑
OrderDO orderDO = new OrderDO();
orderDAO.insertOrder(orderDO);
return orderDO.getId();
}
public void updateOrder(OrderDO orderDO, RequestDTO updateRequest) {
orderDO.setXXX(XXX); // 省略很多
orderDAO.updateOrder(orderDO);
}
public void doSomeBusiness(Long id) {
OrderDO orderDO = orderDAO.getOrderById(id);
// 此处省略很多业务逻辑
}
上面的代码片段看似无可厚非,但假设在未来我们需要加入缓存逻辑,代码则需要改为如下:private OrderDAO orderDAO;
private Cache cache;
public Long addOrder(RequestDTO request) {
// 此处省略很多拼装逻辑
OrderDO orderDO = new OrderDO();
orderDAO.insertOrder(orderDO);
cache.put(orderDO.getId(), orderDO);
return orderDO.getId();
}
public void updateOrder(OrderDO orderDO, RequestDTO updateRequest) {
orderDO.setXXX(XXX); // 省略很多
orderDAO.updateOrder(orderDO);
cache.put(orderDO.getId(), orderDO);
}
public void doSomeBusiness(Long id) {
OrderDO orderDO = cache.get(id);
if (orderDO == null) {
orderDO = orderDAO.getOrderById(id);
}
// 此处省略很多业务逻辑
}
可以看到,插入缓存逻辑后,原本简单的代码变得复杂。原本一行代码现在至少需要三行。随着代码量的增加,如果你在某处忘记查看缓存或忘记更新缓存,可能会导致轻微的性能下降或者更糟糕的是,缓存和数据库的数据不一致,从而导致bug。这种问题随着代码量和复杂度的增长会变得更加严重,这就是软件被“固化”的后果。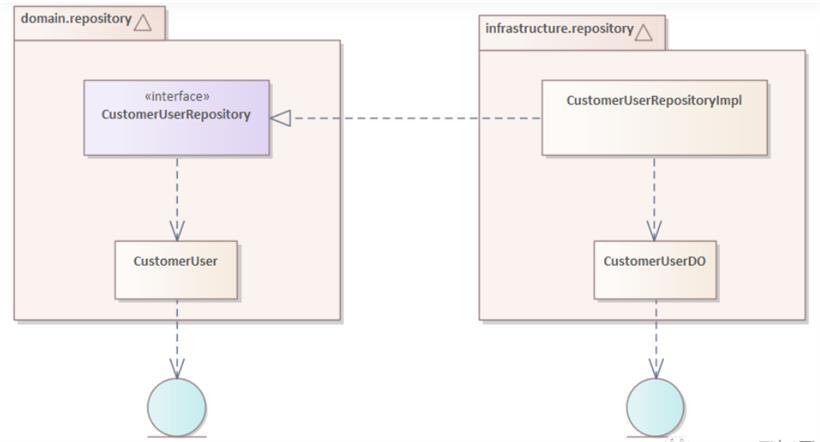
避免使用底层实现语法命名接口方法:仓储接口应该与底层数据存储实现保持解耦。使用像insert, select, update, delete这样的词语,这些都是SQL语法,等于是将接口与数据库实现绑定。相反,应该视仓储为一个类似集合的抽象,使用更通用的词汇,如 **find、save、remove**。特别注意,区分insert/add 和 update 本身就是与底层实现绑定的逻辑,有时候存储方式(如缓存)并不区分这两者。在这种情况下,使用一个中立的save接口,然后在具体的实现中根据需要调用insert或update。
使用领域对象作为参数和返回值:仓储接口位于领域层,因此它不应该暴露底层数据存储的细节。当底层存储技术发生变化时,领域模型应保持不变。因此,仓储接口应以领域对象,特别是聚合根(Aggregate Root)对象,作为参数和返回值。
避免过度通用化的仓储模式:虽然一些ORM框架(如Spring Data和Entity Framework)提供了高度通用的仓储接口,通过注解自动实现接口,但这种做法在简单场景下虽然方便,但通常缺乏扩展性(例如,添加自定义缓存逻辑)。使用这种通用接口可能导致在未来的开发中遇到限制,甚至需要进行大的重构。但请注意,避免过度通用化并不意味着不能有基本的接口或通用的辅助类。

public interface Identifiable<ID extends Identifier<?>> extends Serializable {
ID getId();
}
public interface Identifier<T> extends Serializable {
T getValue();
}
public interface Entity<ID extends Identifier<?>> extends Identifiable<ID> { }
public interface Aggregate<ID extends Identifier<?>> extends Entity<ID> { }
这里,聚合会实现Aggregate接口,而实体会实现Entity接口。聚合本质上是一种特殊的实体,这种结构使逻辑更加清晰。另外,我们引入了Identifier接口来表示实体的唯一标识符,它将唯一标识符视为值对象,这是DDD中常见的做法。如下面所示的案例public class OrderId implements Identifier<Long> {
@Serial
private static final long serialVersionUID = -8658575067669691021L;
public Long id;
public OrderId(Long id){
this.id = id;
}
@Override
public Long getValue() {
return id;
}
}
4.2 创建通用Repository接口public interface Repository <T extends Aggregate<ID>, ID extends Identifier<?>> {
T find(ID id);
void remove(T aggregate);
void save(T aggregate);
}
业务特定的接口可以在此基础上进行扩展。例如,对于订单,我们可以添加计数和分页查询。public interface OrderRepository extends Repository<Order, OrderId> {
// 自定义Count接口,在这里OrderQuery是一个自定义的DTO
Long count(OrderQuery query);
// 自定义分页查询接口
Page<Order> query(OrderQuery query);
}
请注意,Repository的接口定义位于Domain层,而具体的实现则位于Infrastructure层。@Repository
@RequiredArgsConstructor(onConstructor = @__(@Autowired))
@Slf4j
public class OrderRepositoryNativeImpl implements OrderRepository {
private final OrderMapper orderMapper;
private final OrderItemMapper orderItemMapper;
private final OrderConverter orderConverter;
private final OrderItemConverter orderItemConverter;
@Override
public Order find(OrderId orderId) {
OrderDO orderDO = orderMapper.selectById(orderId.getValue());
return orderConverter.fromData(orderDO);
}
@Override
public void save(Order aggregate) {
if(aggregate.getId() != null && aggregate.getId().getValue() > 0){
// update
OrderDO orderDO = orderConverter.toData(aggregate);
orderMapper.updateById(orderDO);
}else{
// insert
OrderDO orderDO = orderConverter.toData(aggregate);
orderMapper.insert(orderDO);
aggregate.setId(orderConverter.fromData(orderDO).getId());
}
}
...
}
这段代码展示了一个常见的模式:Entity/Aggregate转换为Data Object(DO),然后使用Data Access Object(DAO)根据业务逻辑执行相应操作。在操作完成后,如果需要,还可以将DO转换回Entity。代码很简单,唯一需要注意的是save方法,需要根据Aggregate的ID是否存在且大于0来判断一个Aggregate是否需要更新还是插入。
@Repository
@RequiredArgsConstructor(onConstructor = @__(@Autowired))
@Slf4j
public class OrderRepositoryNativeImpl implements OrderRepository {
//省略其他逻辑
@Override
public void save(Order aggregate) {
if(aggregate.getId() != null && aggregate.getId().getValue() > 0){
// 每次都将Order和所有LineItem全量更新
OrderDO orderDO = orderConverter.toData(aggregate);
orderMapper.updateById(orderDO);
for(OrderItem orderItem : aggregate.getOrderItems()){
save(orderItem);
}
}else{
//省略插入逻辑
}
}
private void save(OrderItem orderItem) {
if (orderItem.getId() != null && orderItem.getId().getValue() > 0) {
OrderItemDO orderItemDO = orderItemConverter.toData(orderItem);
orderItemMapper.updateById(orderItemDO);
} else {
OrderItemDO orderItemDO = orderItemConverter.toData(orderItem);
orderItemMapper.insert(orderItemDO);
orderItem.setItemId(orderItemConverter.fromData(orderItemDO).getId());
}
}
}
在此示例中,会执行4个UPDATE操作,而实际上只需2个。通常情况下,这个额外的开销并不严重,但如果非Aggregate Root的实体数量很大,这会导致大量不必要的写操作。public class DiffUtilsTest {
@Test
public void diffObject() throws IllegalAccessException, IOException, ClassNotFoundException {
// 堆代码 duidaima.com
//实时对象
Order realObj = Order.builder()
.id(new OrderId(31L))
.customerId(100L)
.totalAmount(new BigDecimal(100))
.recipientInfo(new RecipientInfo("zhangsan","安徽省合肥市","123456"))
.build();
// 快照对象
Order snapshotObj = SnapshotUtils.snapshot(realObj);
snapshotObj.setId(new OrderId(2L));
snapshotObj.setTotalAmount(new BigDecimal(200));
EntityDiff diff = DiffUtils.diff(realObj, snapshotObj);
assertTrue(diff.isSelfModified());
assertEquals(2, diff.getDiffs().size());
}
}
通过变更追踪的引入,我们能够使聚合的Repository实现更加高效和智能。这允许开发人员将注意力集中在业务逻辑上,而不必担心不必要的数据库操作。
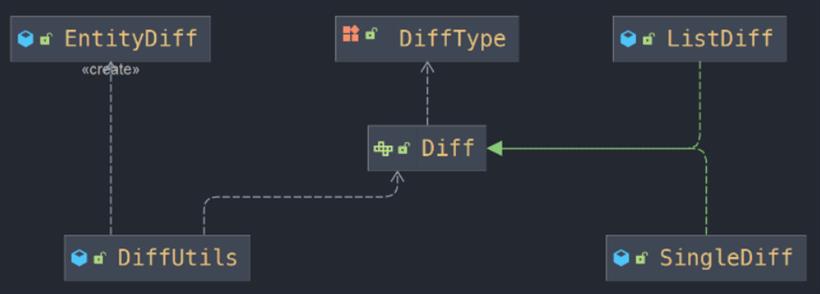
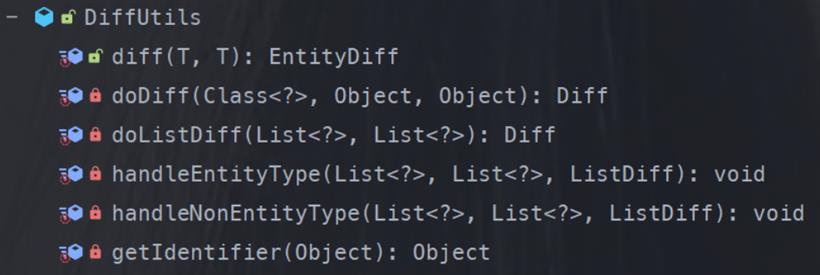
@Slf4j
public abstract class AggregateRepositorySupport<T extends Aggregate<ID>, ID extends Identifier<?>> implements Repository<T, ID> {
@Getter
private final Class<T> targetClass;
// 让 AggregateManager 去维护 Snapshot
@Getter(AccessLevel.PROTECTED)
private AggregateManager<T, ID> aggregateManager;
protected AggregateRepositorySupport(Class<T> targetClass) {
this.targetClass = targetClass;
this.aggregateManager = AggregateManagerFactory.newInstance(targetClass);
}
/** Attach的操作就是让Aggregate可以被追踪 */
@Override
public void attach(@NotNull T aggregate) {
this.aggregateManager.attach(aggregate);
}
/** Detach的操作就是让Aggregate停止追踪 */
@Override
public void detach(@NotNull T aggregate) {
this.aggregateManager.detach(aggregate);
}
@Override
public T find(@NotNull ID id) {
T aggregate = this.onSelect(id);
if (aggregate != null) {
// 这里的就是让查询出来的对象能够被追踪。
// 如果自己实现了一个定制查询接口,要记得单独调用attach。
this.attach(aggregate);
}
return aggregate;
}
@Override
public void remove(@NotNull T aggregate) {
this.onDelete(aggregate);
// 删除停止追踪
this.detach(aggregate);
}
@Override
public void save(@NotNull T aggregate) {
// 如果没有 ID,直接插入
if (aggregate.getId() == null) {
this.onInsert(aggregate);
this.attach(aggregate);
return;
}
// 做 Diff
EntityDiff diff = null;
try {
//aggregate = this.onSelect(aggregate.getId());
find(aggregate.getId());
diff = aggregateManager.detectChanges(aggregate);
} catch (IllegalAccessException e) {
//throw new RuntimeException("Failed to detect changes", e);
e.printStackTrace();
}
if (diff.isEmpty()) {
return;
}
// 调用 UPDATE
this.onUpdate(aggregate, diff);
// 最终将 DB 带来的变化更新回 AggregateManager
aggregateManager.merge(aggregate);
}
/** 这几个方法是继承的子类应该去实现的 */
protected abstract void onInsert(T aggregate);
protected abstract T onSelect(ID id);
protected abstract void onUpdate(T aggregate, EntityDiff diff);
protected abstract void onDelete(T aggregate);
}
OrderRepositoryDiffImpl 类@Repository
@Slf4j
@Primary
public class OrderRepositoryDiffImpl extends AggregateRepositorySupport<Order, OrderId> implements OrderRepository {
//省略其他逻辑
@Override
protected void onUpdate(Order aggregate, EntityDiff diff) {
if (diff.isSelfModified()) {
OrderDO orderDO = orderConverter.toData(aggregate);
orderMapper.updateById(orderDO);
}
Diff orderItemsDiffs = diff.getDiff("orderItems");
if ( orderItemsDiffs instanceof ListDiff diffList) {
for (Diff itemDiff : diffList) {
if(itemDiff.getType() == DiffType.REMOVED){
OrderItem orderItem = (OrderItem) itemDiff.getOldValue();
orderItemMapper.deleteById(orderItem.getItemId().getValue());
}
if (itemDiff.getType() == DiffType.ADDED) {
OrderItem orderItem = (OrderItem) itemDiff.getNewValue();
orderItem.setOrderId(aggregate.getId());
OrderItemDO orderItemDO = orderItemConverter.toData(orderItem);
orderItemMapper.insert(orderItemDO);
}
if (itemDiff.getType() == DiffType.MODIFIED) {
OrderItem line = (OrderItem) itemDiff.getNewValue();
OrderItemDO orderItemDO = orderItemConverter.toData(line);
orderItemMapper.updateById(orderItemDO);
}
}
}
}
}
ThreadLocalAggregateManager 类public class ThreadLocalAggregateManager<T extends Aggregate<ID>, ID extends Identifier<?>> implements AggregateManager<T, ID> {
private final ThreadLocal<DbContext<T, ID>> context;
private Class<? extends T> targetClass;
public ThreadLocalAggregateManager(Class<? extends T> targetClass) {
this.targetClass = targetClass;
this.context = ThreadLocal.withInitial(() -> new DbContext<>(targetClass));
}
@Override
public void attach(T aggregate) {
context.get().attach(aggregate);
}
@Override
public void attach(T aggregate, ID id) {
context.get().setId(aggregate, id);
context.get().attach(aggregate);
}
@Override
public void detach(T aggregate) {
context.get().detach(aggregate);
}
@Override
public T find(ID id) {
return context.get().find(id);
}
@Override
public EntityDiff detectChanges(T aggregate) throws IllegalAccessException {
return context.get().detectChanges(aggregate);
}
@Override
public void merge(T aggregate) {
context.get().merge(aggregate);
}
}
SnapshotUtils 类public class SnapshotUtils {
@SuppressWarnings("unchecked")
public static <T extends Aggregate<?>> T snapshot(T aggregate)
throws IOException, ClassNotFoundException {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(aggregate);
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bis);
return (T) ois.readObject();
}
}
这个类中的 snapshot 方法采用序列化和反序列化的方式来实现对象的深拷贝,从而为给定的对象创建一个独立的副本。注意,为了使此方法工作,需要确保 Aggregate 类及其包含的所有对象都是可序列化的。



