- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

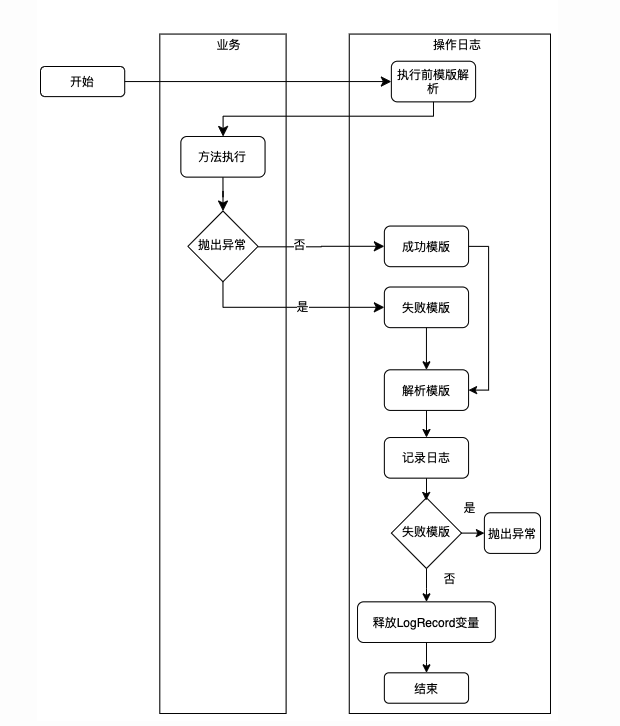
记录的日志可以分为两类:操作流转日志和系统日志,这两类日志面向的群体和定位也有一定的区别。其中系统日志主要面向研发层面,为研发定位问题提供依据和执行链路回溯,一般可读性要求比较低,检索也需要一定的技巧和条件。
而操作日志主要面向用户和保障人员,具备较强的可读性,主要针对用户对某一场景做出操作后进行留痕,比如用户的审批流程,可以从操作日志列表直观看到,经过了哪些流程,哪些人员审批和审批的结果。


@LogRecord(
success = "执行签到操作,修改 tag 为:#{#model.getTag()};ids 为:#{T(java.lang.String).join(',',#model.getIds())}",
bizId = "#{#model.getBizId()}",
childBizId = "#{#_resource.getChildBizId()}",
context = "#{@demoService.getContext(#_resource.getContextIndex())}",
identityType = "#{#model.getIdentity()}"
)
@PostMapping("full")
public ResponseModel fullDemo(@RequestBody RequestModel model) {
// 堆代码 duidaima.com
// 执行业务逻辑...
ResponseModel responseModel = new ResponseModel();
responseModel.setCode("200");
responseModel.setRequestModel(model);
responseModel.setChildBizId("biz_001");
responseModel.setContextIndex("stash");
return responseModel;
}
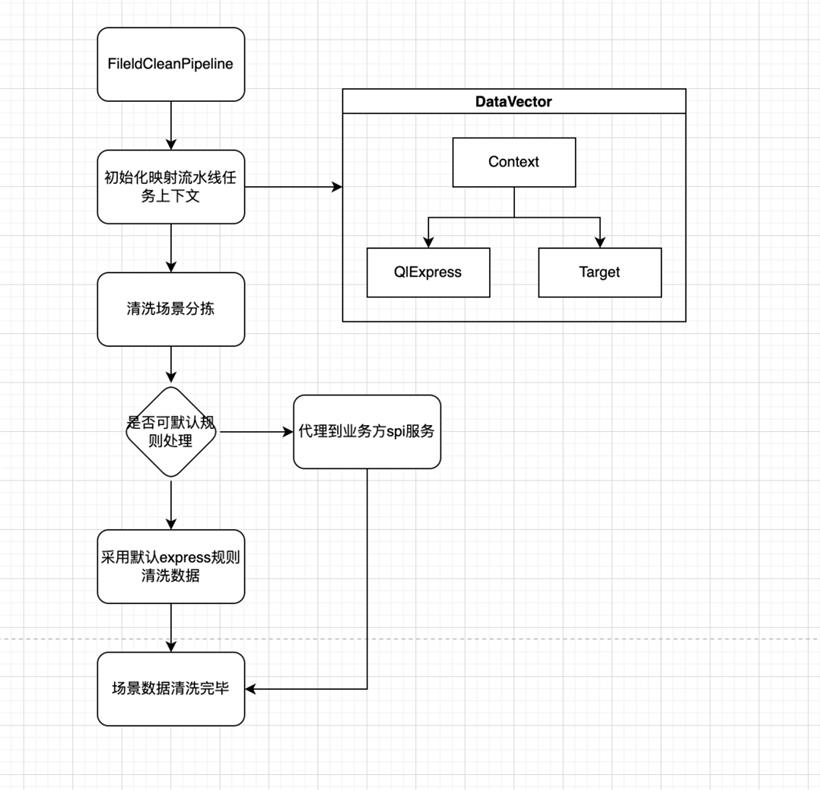
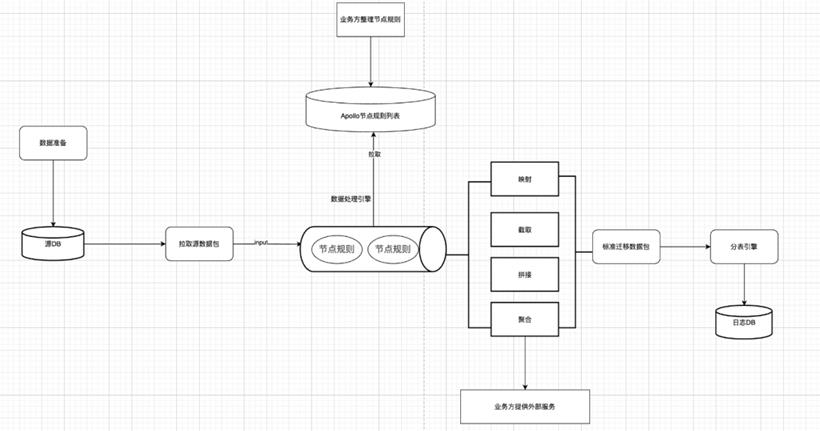
我们按照日志的场景 ID 为维度进行数据迁移,业务方自行梳理和归类场景,并提供场景的字段映射和处理表达式规则。单场景迁移清洗流程如下:
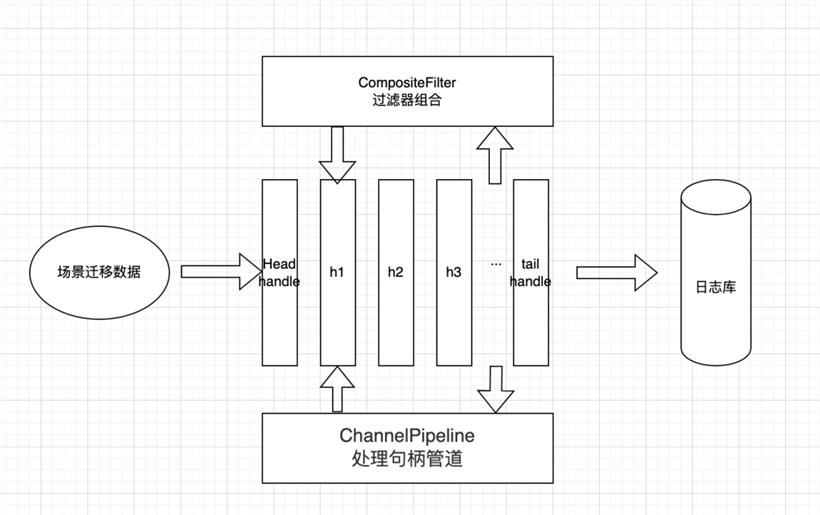
public class ChainContext<T, V> {
/**
* 存储信息<处理节点>
* */
AbstractHandler<T, V> handler;
/**
* 下一个节点
* */
ChainContext<T, V> next;
/**
* 遍历 pipeline 链表执行
* */
public void fireChainRun(DataVector<T, V> arg){
handler.invoke(arg);
ChainContext<T, V> next = this.next;
if (null!=next){
next.fireChainRun(arg);
}
}
public AbstractHandler<T, V> getHandler(){
return this.handler;
}
public ChainContext<T, V> getNext(){
return this.next;
}
public void setHandler(AbstractHandler<T, V> handler){
this.handler = handler;
}
public void insertNext(ChainContext<T, V> chain){
ChainContext<T, V> oldNext = getNext().next;
this.next = chain;
if (null!=oldNext){
chain.next = oldNext;
}
}
public void setNext(ChainContext<T, V> chain){
this.next = chain;
}
}