前言
大家还记得双11得时候,会有一个大屏实时刷新显示交易金额,这究竟是怎么实时统计计算的呢?Apache Flink是一个开源、流行的大数据框架和分布式处理引擎,特别是针对流式数据的处理,那么今天通过一个简单的业务场景,实时统计用户的交易金额,感受一下flink的魅力。
Flink入门例子
业务场景
监听socket请求,获取用户的流水信息,实时输出用户的交易总金额。order信息如下所示:
public class Order {
/**
* 订单号
*/
private String orderId;
/**
* 用户号
*/
private String userId;
/**
* 交易金额
*/
private Long amount;
/**
* 交易时间
*/
private String date;
}
Flink统计任务步骤
1.引入flink相关的依赖,本案例采用flink最新的1.17.0版本
<properties>
<flink.version>1.17.0</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
2.创建flink执行环境

3.读取数据

4.处理数据,map方法转换成Order对象
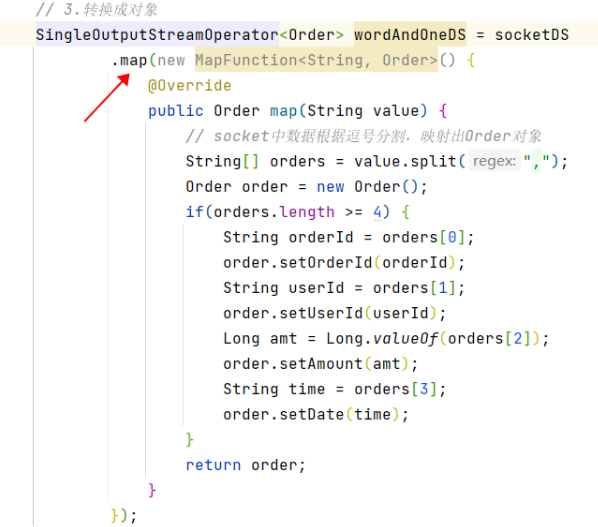
5.通过keyBy方法分组

6.根据金额字段sum聚合

7.转换输出结果

8.打印结果
mapRes.print();
9.开始执行任务
env.execute();
演示
1.通过nc命令服务器上启动socket服务
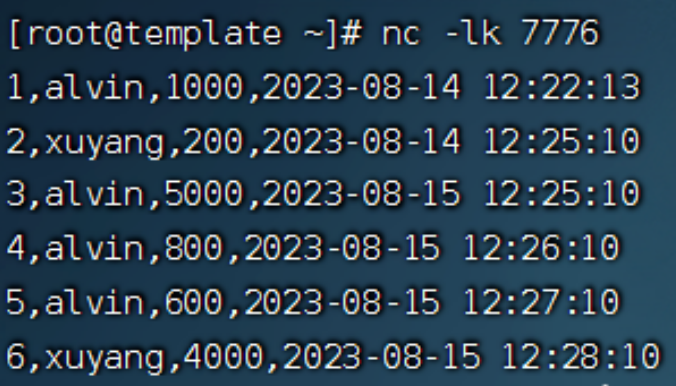
2.直接在idea中本地方式运行main方法,启动flink任务
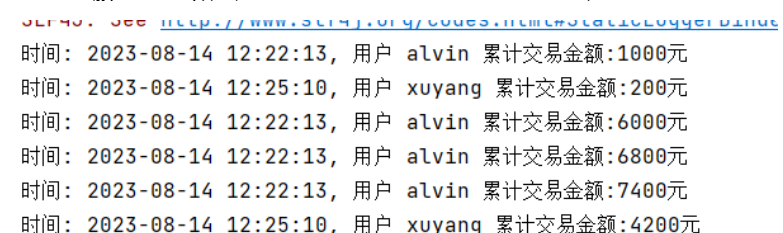
3. socket服务中发送数据,可以查看idea console实时输出统计结果
 打包运行
打包运行
目前flink任务在idea中运行正确,我们需要将它达成jar包,丢到linux服务器上的flink集群中运行。
1.maven打包插件
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>log4j:*</exclude>
<exclude>org.apache.hadoop:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<!-- Do not copy the signatures in the META-INF folder.
Otherwise, this might cause SecurityExceptions when using the JAR. -->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers combine.children="append">
<transformer
implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer">
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
2.flink界面提交任务
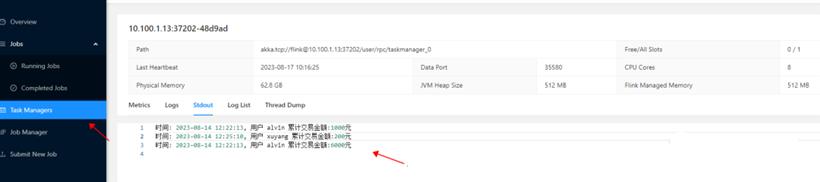
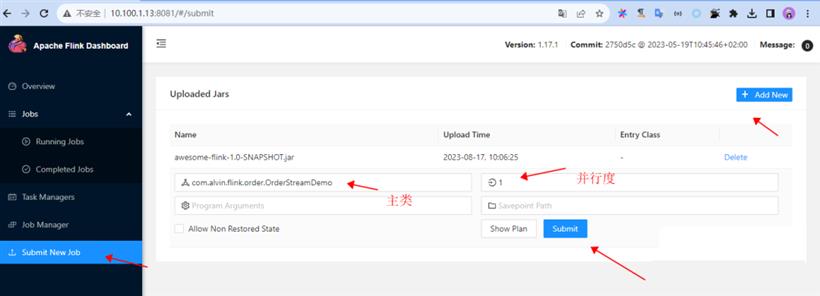 3.查看输出结果
3.查看输出结果
往socket中发交易数据,可以实时看到统计结果
 Flink究竟是什么?
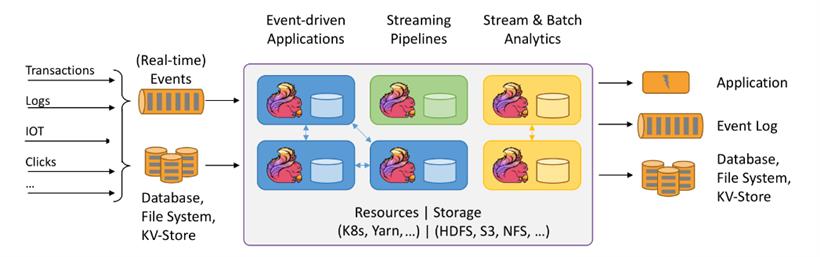
Flink究竟是什么?
通过上面的例子,我们能直观的感受到flink的能力,Flink是一个开源的流式处理框架,它提供了高效、可扩展和容错的数据流处理能力。它支持流式和批处理数据处理,并且具有低延迟、高吞吐量和精确一次处理语义的特性。
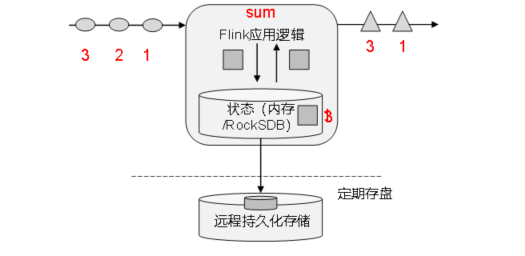
Flink的核心目标,是"数据流上的有状态计算"。把流处理需要的额外数据保存成一个“状态”,然后针对这条数据进行处理,并且更新状态,这就是所谓的“有状态的流处理”。
 总结
总结
本文通过一个实时统计用户的交易金额的例子感受了一下Flink的作用,但是实际场景往往比这复杂的多,比如统计用户指定时间范围内(3天内)的交易金额,交易流水发生乱序了怎么办,Flink面对这些问题其实都有相应的机制处理,需要进一步去挖掘学习。
附录
完整代码如下
public class OrderStreamDemo {
public static void main(String[] args) throws Exception {
// 堆代码 duidaima.com
// 1.创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
// 设置并行度
env.setParallelism(1);
// 2.读取数据
DataStreamSource<String> socketDS = env.socketTextStream("10.100.1.13", 7776);
// 3.转换成对象
SingleOutputStreamOperator<Order> wordAndOneDS = socketDS
.map(new MapFunction<String, Order>() {
@Override
public Order map(String value) {
// socket中数据根据逗号分割,映射出Order对象
String[] orders = value.split(",");
Order order = new Order();
if(orders.length >= 4) {
String orderId = orders[0];
order.setOrderId(orderId);
String userId = orders[1];
order.setUserId(userId);
Long amt = Long.valueOf(orders[2]);
order.setAmount(amt);
String time = orders[3];
order.setDate(time);
}
return order;
}
});
// 4 分组
KeyedStream<Order, String> wordAndOneKS = wordAndOneDS.keyBy(
new KeySelector<Order, String>() {
@Override
public String getKey(Order value) {
return value.getUserId();
}
}
);
// 5 聚合
SingleOutputStreamOperator<Order> sumDS = wordAndOneKS.sum("amount");
// 6. 转换输出结果
SingleOutputStreamOperator<String> mapRes = sumDS.map(new MapFunction<Order, String>() {
@Override
public String map(Order value) throws Exception {
String str = String.format("时间: %s, 用户 %s 累计交易金额:%d元", value.getDate(), value.getUserId(), value.getAmount());
return str;
}
});
// 7.输出数据
mapRes.print();
// 8.执行
env.execute();
}
}



 闽公网安备 35020302035485号
闽公网安备 35020302035485号





