设计数据湖或中央数据仓库是许多大型组织的主要职能,这些组织每天处理数百万笔交易,并对这些交易进行进一步的报告、预测或机器学习项目分析。
为了将所有来自源系统(我们称之为“上游”)到其他业务应用(所谓“下游”)的数据点整合在一起,已经成为数据智能或商业智能团队的一个不同的工程奇迹。在完成所有这些练习和从上游到下游的紧密依赖后,管理数据变得越来越难以通过所有数据管道进行检查。
在大多数组织中,我们可以看到以下数据流程是从如下所示开始的:
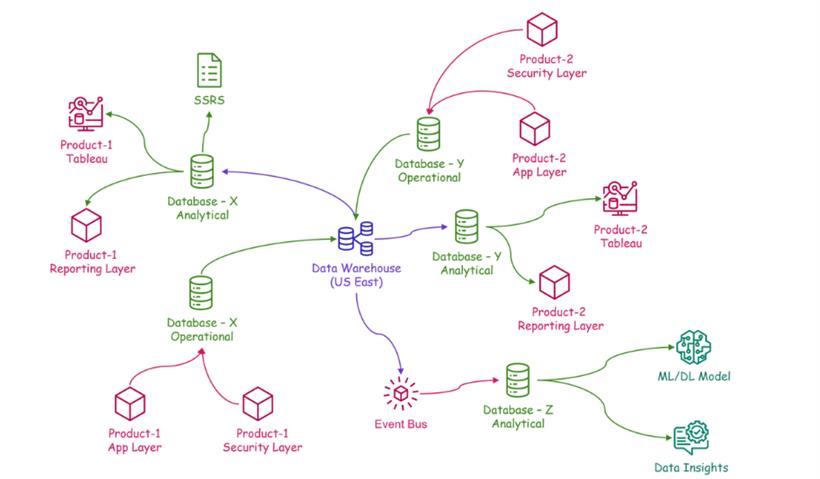
新应用程序或多或少是按领域驱动设计,这些应用程序与更特定于应用程序的数据非常紧密,这给数据库工程团队带来了新的挑战,要为满足所有方面的目的提供有组织的解决方案,如下所示:
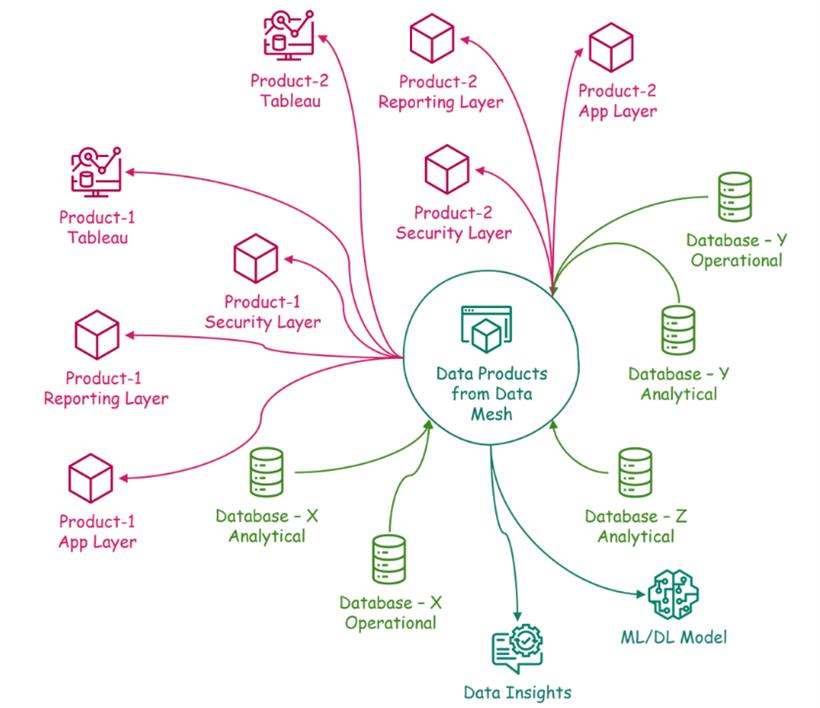
数据网格(Data Mesh)具有相同的功能集,以满足领域驱动的分散化的目的。为了设计数据网格,强调遵循4个原则,并针对组织中不同团队提供了不同的责任。
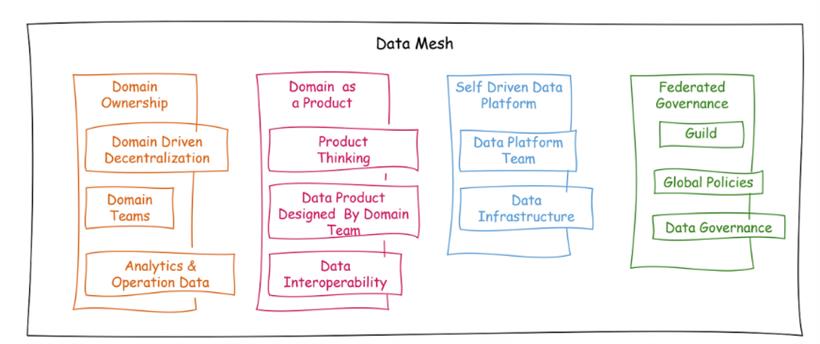 领域数据的所有权
领域数据的所有权
由于我们采用了领域驱动的分散化方法,因此在数据网格中,数据围绕着特定的业务领域进行拆分,就像我们在微服务中所做的那样。在数据领域中也是如此,将存在一个负责跟踪活动性的数据领域团队。数据领域团队可以使用数据创建数据产品,其他数据领域团队可以使用这些数据产品。
数据作为产品
在数据网格中,数据被视为可以由一个数据领域团队发布并可以被另一个数据领域团队消费的产品。数据领域团队必须以产品思维来考虑数据,他们对数据质量、表示和内聚性负完全责任。此外,数据领域团队必须与数据网格启用团队合作,以获取数据产品的资格。
自主驱动的数据平台
数据网格中的所有数据都可以在公司内部任何地方使用。因此,可以在短时间内创建新的报告或数据产品,并传播到随后的数据产品。这带来了治理问题,因为数据的控制可以通过治理政策进行。
联合治理
治理通过不同的数据政策和安全政策进行处理,由数据领域团队根据数据发布和数据消费受到的不同合同来执行。然而,如果政策未正确定义,治理可能是数据的一个问题点。
数据网格架构
数据网格具有多种架构,可以使用不同的语言和它们的框架进行定义。这完全取决于团队特定的实现,这些实现用于实现数据产品。
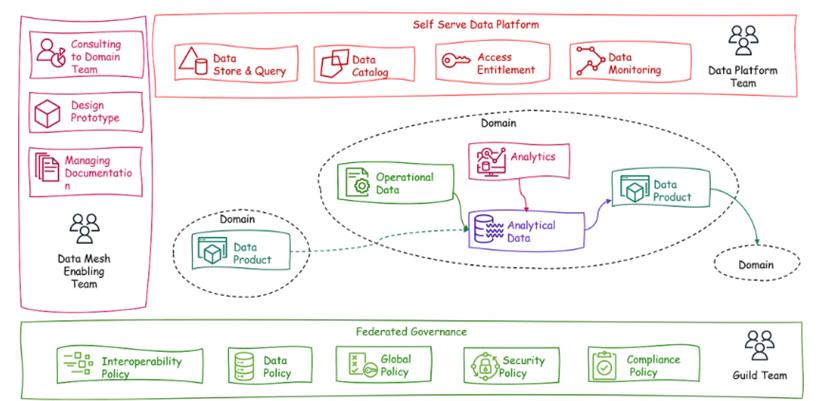
数据网格的路线图可以由不同团队共同设计和实施。每个团队都有维护数据网格的责任。
数据网格启用团队
启用团队是数据网格架构的主要团队,用于与数据领域团队进行连接。他们为数据产品创建原型和文档。他们指导数据领域团队遵循定义的数据产品规则,并帮助他们为数据网格授予数据产品。
数据平台团队
平台团队主要维护基础设施,以维护数据对数据网格的可用性。他们用于维护所有数据产品的数据目录。数据目录可以是其他数据领域团队查找数据网格并设计他们的数据产品的元数据。数据平台团队还拥有数据存储、监控和访问数据网格的矩阵。
数据领域团队
数据领域团队可以是创建应用程序或数据产品的工程或开发团队。数据产品是操作数据、分析功能和来自其他数据产品的数据的组合。其他数据产品也可以使用类似的方式。
行业团队
行业团队拥有数据治理政策,并负责创建数据、安全和其他合规政策。定义政策有助于定义数据网格中数据产品的可访问性。数据网格是新的现代化数据架构模式,可以在不久的将来在企业级别实施。数据网格架构中有很多值得探索的地方


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






