为什么要使用多线程
提高响应速度:对于耗时操作,使用线程可以避免阻塞主线程,提高应用程序的响应速度。
实现并行操作:在多CPU系统中,使用线程可以并行处理任务,提高CPU利用率。
改善程序结构:将一个既长又复杂的进程分为多个线程,可以使其成为几个独立或半独立的运行部分,这样有利于程序的修改和理解。
方便的通信机制:线程间可以通过共享内存等方式进行通信,比进程间通信更方便、高效。
创建线程有几种方式?
创建线程有四种方式:
1.通过继承Thread类来创建线程。
2.通过实现Runnable接口来创建线程。
3.通过实现Callable接口来创建线程。
4.使用Executor框架来创建线程池。
简单实现
public class ThreadTest {
public static void main(String[] args) {
Thread thread = new MyThread();
thread.start();
}
}
class MyThread extends Thread {
@Override
public void run() {
System.out.println("关注公众号:一安未来");
}
}
public class ThreadTest {
public static void main(String[] args) {
MyRunnable myRunnable = new MyRunnable();
Thread thread = new Thread(myRunnable);
thread.start();
}
}
class MyRunnable implements Runnable {
@Override
public void run() {
System.out.println("关注公众号:一安未来");
}
}
public class ThreadTest {
public static void main(String[] args) throws ExecutionException, InterruptedException {
MyThreadCallable mc = new MyThreadCallable();
FutureTask<Integer> ft = new FutureTask<>(mc);
Thread thread = new Thread(ft);
thread.start();
System.out.println(ft.get());
}
}
class MyThreadCallable implements Callable {
@Override
public String call()throws Exception {
return "关注公众号:一安未来";
}
}
public class ThreadTest {
public static void main(String[] args) throws Exception {
ThreadPoolExecutor executorOne = new ThreadPoolExecutor(5, 5, 1,
TimeUnit.MINUTES, new ArrayBlockingQueue<Runnable>(20), new CustomizableThreadFactory("Yian-Thread-pool"));
executorOne.execute(() -> {
System.out.println("关注公众号:一安未来");
});
// 堆代码 duidaima.com
//关闭线程池
executorOne.shutdown();
}
}
线程和进程的区别
线程和进程是操作系统中重要的概念,都是操作系统资源分配的基本单位,但它们有一些关键的区别。
1.地址空间和资源拥有:进程是执行中的一个程序,具有自己的地址空间和文件描述符等资源。线程是在进程中执行的一个单独的执行路径,共享进程的地址空间和资源。
2.开销:创建和销毁一个进程需要保存寄存器、栈信息以及进行资源分配和回收等操作,开销较大。而线程的创建和销毁只需保存寄存器和栈信息,开销较小。
3.通信切换:进程之间必须通过IPC(进程间通信)进行通信,切换开销相对较大。线程之间可以直接共享进程的地址空间和资源,切换开销相对较小。
4.并发性:进程是独立的执行单元,具有自己的调度算法,在并发条件下更加稳定可靠。而线程共享进程的资源,线程之间的调度和同步比较复杂,对并发条件的处理需要更多的注意。
5.一对多的关系:一个线程只能属于一个进程,而一个进程可以拥有多个线程。
Runnable和 Callable有什么区别
Runnable接口只有一个需要实现的方法,即run()。当你启动一个线程时,这个run()方法就会被执行。Runnable的主要问题是它不支持返回结果
Callable可以返回结果,也可以抛出异常。它有一个call()方法,当调用这个方法时,这个方法就会被执行。
volatile作用,原理
主要用于声明变量,以指示该变量可能会被多个线程同时访问,从而防止编译器进行一些优化,确保线程之间能够正确地读写共享变量。volatile 提供了一种轻量级的同步机制,但它并不能替代 synchronized,因为它无法解决复合操作的原子性问题。
作用:
可见性: 当一个线程修改了一个被 volatile 修饰的变量的值,其他线程能够立即看到这个修改,即保证了变量的可见性。
禁止指令重排序: volatile 修饰的变量的读写操作会禁止指令重排序,确保变量的写操作不会被重排序到其它操作之前。
原理:
volatile 的实现原理涉及到 CPU 的缓存一致性和内存屏障(Memory Barrier)的概念。
内存可见性: 当一个线程写入一个 volatile 变量时,会强制将该线程对应的本地内存中的值刷新到主内存中,从而保证了其他线程能够看到最新的值。同样,当一个线程读取一个 volatile 变量时,会强制从主内存中读取最新的值到本地内存中。
禁止指令重排序: volatile 修饰的变量的读写操作会在其前后插入内存屏障,防止在其前后的指令被重排序。
synchronized 的实现原理以及锁优化
如果synchronized作用于代码块,反编译可以看到两个指令:monitorenter、monitorexit,JVM使用monitorenter和monitorexit两个指令实现同步;如果作用synchronized作用于方法,反编译可以看到ACCSYNCHRONIZED标记,JVM通过在方法访问标识符(flags)中加入ACCSYNCHRONIZED来实现同步功能。
同步代码块,当线程执行到monitorenter的时候要先获得monitor锁,才能执行后面的方法。当线程执行到monitorexit的时候则要释放锁。
同步方法,当线程执行有ACCSYNCHRONI标志的方法,需要获得monitor锁。每个对象都与一个monitor相关联,线程可以占有或者释放monitor。
monitor监视器
操作系统的管程(monitors)是概念原理,ObjectMonitor是它的原理实现。在Java虚拟机(HotSpot)中,Monitor(管程)是由ObjectMonitor实现的,其主要数据结构如下:
ObjectMonitor() {
_header = NULL;
_count = 0; // 记录个数
_waiters = 0,
_recursions = 0;
_object = NULL;
_owner = NULL;
_WaitSet = NULL; // 处于wait状态的线程,会被加入到_WaitSet
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ;
FreeNext = NULL ;
_EntryList = NULL ; // 处于等待锁block状态的线程,会被加入到该列表
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
}
Java Monitor 的工作机理
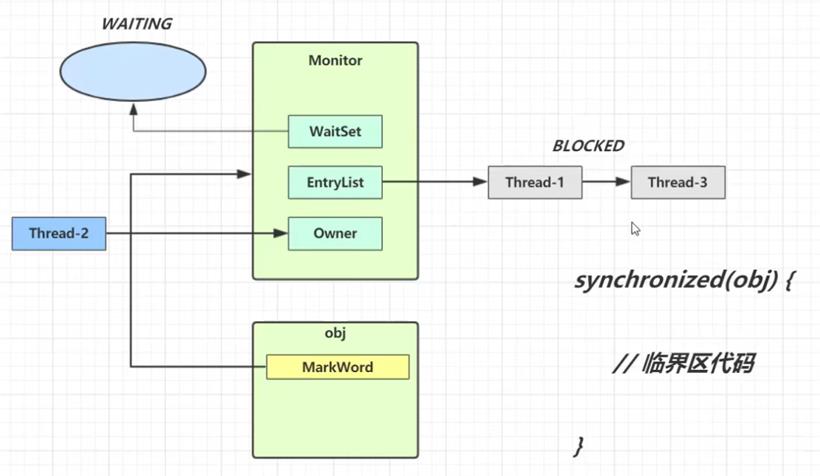
1.要获取monitor的线程,首先会进入EntryList队列。
2.当某个线程获取到对象的monitor后,进入Owner区域,设置为当前线程,同时计数器count加1。
3.如果线程调用了wait()方法,则会进入WaitSet队列阻塞等待。它会释放monitor锁,即将owner赋值为null,count自减1。
4.如果其他线程调用 notify()/notifyAll() ,会唤醒WaitSet中的某个或全部线程,该线程再次尝试获取monitor锁,成功即进入Owner区域。
5.同步方法执行完毕了,线程退出临界区,会将monitor的owner设为null,并释放监视锁
对象与monitor关联
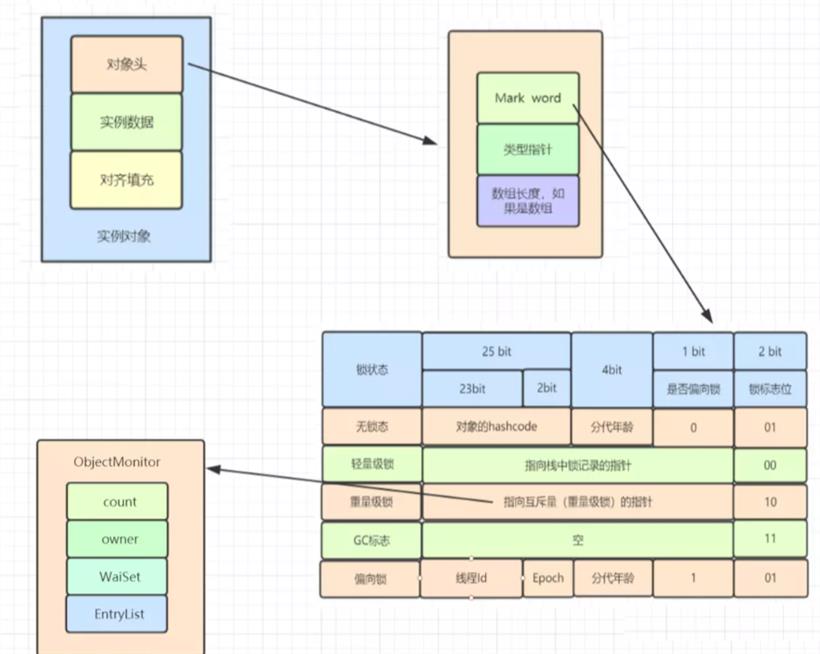
1.在HotSpot虚拟机中,对象在内存中存储的布局可以分为3块区域:对象头(Header),实例数据(Instance Data)和对象填充(Padding)。
2.对象头主要包括两部分数据:Mark Word(标记字段)、Class Pointer(类型指针)。
Mark Word 是用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程 ID、偏向时间戳等。

重量级锁,指向互斥量的指针。其实synchronized是重量级锁,也就是说Synchronized的对象锁,Mark Word锁标识位为10,其中指针指向的是Monitor对象的起始地址。
在JDK1.6之前,synchronized的实现直接调用ObjectMonitor的enter和exit,这种锁被称之为重量级锁。从JDK6开始,HotSpot虚拟机开发团队对Java中的锁进行优化,如增加了适应性自旋、锁消除、锁粗化、轻量级锁和偏向锁等优化策略,提升了synchronized的性能。
偏向锁:在无竞争的情况下,只是在Mark Word里存储当前线程指针,CAS操作都不做。
轻量级锁:在没有多线程竞争时,相对重量级锁,减少操作系统互斥量带来的性能消耗。但是,如果存在锁竞争,除了互斥量本身开销,还额外有CAS操作的开销。
自旋锁:减少不必要的CPU上下文切换。在轻量级锁升级为重量级锁时,就使用了自旋加锁的方式
锁粗化:将多个连续的加锁、解锁操作连接在一起,扩展成一个范围更大的锁。
锁消除:虚拟机即时编译器在运行时,对一些代码上要求同步,但是被检测到不可能存在共享数据竞争的锁进行消除。
线程有哪些状态
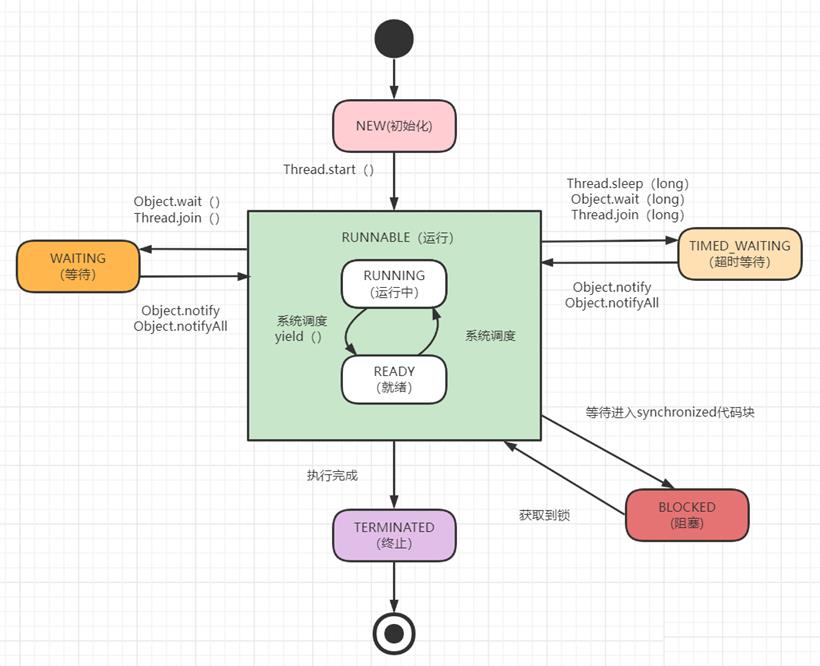
New:线程对象创建之后、但还没有调用start()方法,就是这个状态。
Runnable:它包括就绪(ready)和运行中(running)两种状态。如果调用start方法,线程就会进入Runnable状态。它表示我这个线程可以被执行啦(此时相当于ready状态),如果这个线程被调度器分配了CPU时间,那么就可以被执行(此时处于running状态)。
Blocked:阻塞的(被同步锁或者IO锁阻塞)。表示线程阻塞于锁,线程阻塞在进入synchronized关键字修饰的方法或代码块(等待获取锁)时的状态。比如前面有一个临界区的代码需要执行,那么线程就需要等待,它就会进入这个状态。它一般是从RUNNABLE状态转化过来的。如果线程获取到锁,它将变成RUNNABLE状态。
WAITING : 永久等待状态,进入该状态的线程需要等待其他线程做出一些特定动作(比如通知)。处于该状态的线程不会被分配CPU执行时间,它们要等待被显式地唤醒,否则会处于无限期等待的状态。一般Object.wait。
TIMED_WATING: 等待指定的时间重新被唤醒的状态。有一个计时器在里面计算的,最常见就是使用Thread.sleep方法触发,触发后,线程就进入了Timed_waiting状态,随后会由计时器触发,再进入Runnable状态。
终止(TERMINATED):表示该线程已经执行完成。
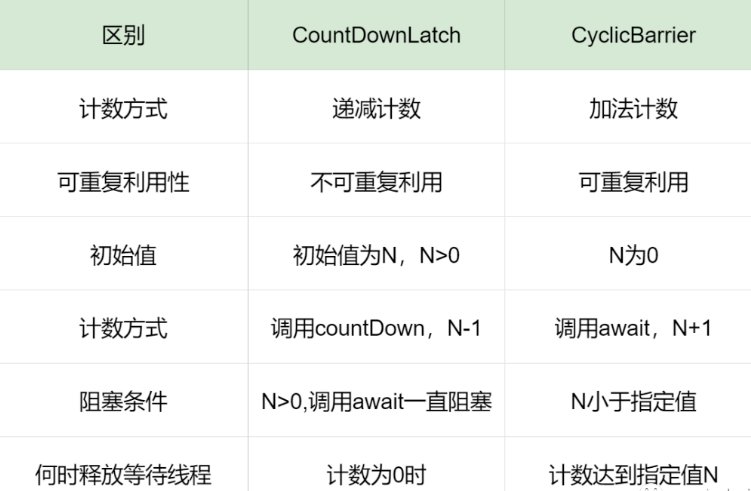
CountDownLatch与CyclicBarrier 区别
CountDownLatch和CyclicBarrier都用于让线程等待,达到一定条件时再运行。主要区别是:
CountDownLatch:一个或者多个线程,等待其他多个线程完成某件事情之后才能执行;
CyclicBarrier:多个线程互相等待,直到到达同一个同步点,再继续一起执行。
多线程环境下的伪共享
CPU的缓存是以缓存行(cache line)为单位进行缓存的,当多个线程修改相互独立的变量,而这些变量又处于同一个缓存行时就会影响彼此的性能。这就是伪共享
现代计算机计算模型:
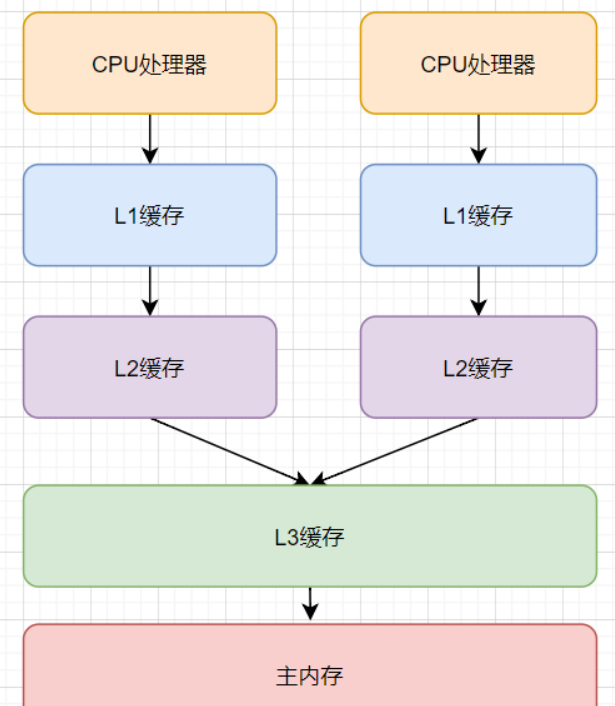
CPU执行速度比内存速度快好几个数量级,为了提高执行效率,现代计算机模型演变出CPU、缓存(L1,L2,L3),内存的模型。
CPU执行运算时,如先从L1缓存查询数据,找不到再去L2缓存找,依次类推,直到在内存获取到数据。
为了避免频繁从内存获取数据,聪明的科学家设计出缓存行,缓存行大小为64字节。
也正是因为缓存行的存在,就导致了伪共享问题,如图所示:

假设数据a、b被加载到同一个缓存行。
当线程1修改了a的值,这时候CPU1就会通知其他CPU核,当前缓存行(Cache line)已经失效。
这时候,如果线程2发起修改b,因为缓存行已经失效了,所以「core2 这时会重新从主内存中读取该 Cache line 数据」。读完后,因为它要修改b的值,那么CPU2就通知其他CPU核,当前缓存行(Cache line)又已经失效。
所以,如果同一个Cache line的内容被多个线程读写,就很容易产生相互竞争,频繁回写主内存,会大大降低性能。
解决伪共享问题的一种方法是通过填充(Padding)来确保共享的变量独立存储于不同的缓存行中。填充的思想是在变量之间插入一些无关的数据,使它们分布到不同的缓存行,从而避免多个变量共享同一个缓存行。
在Java中,可以使用@Contended注解来避免伪共享。这个注解可以在字段上使用,它会在字段的前后插入填充,使得字段单独占据一个缓存行。
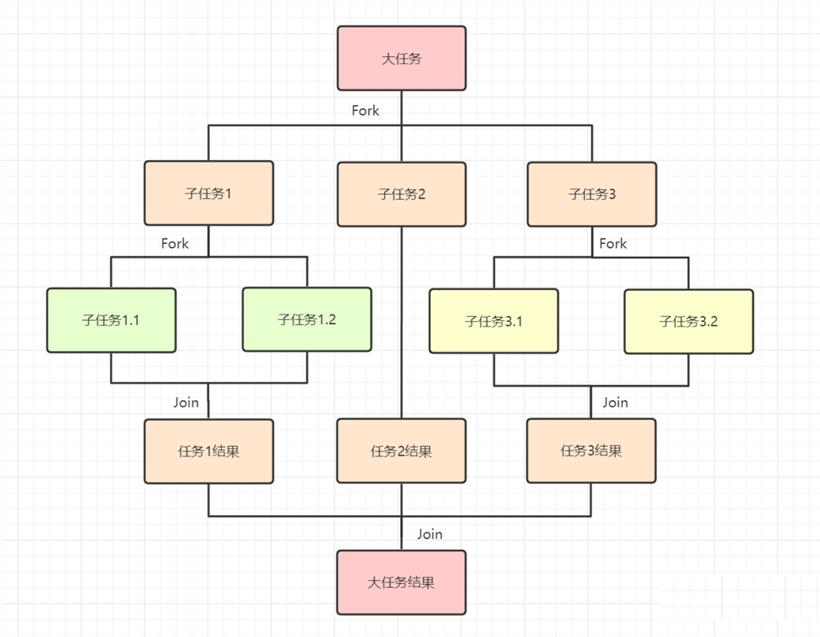
Fork/Join框架
Fork/Join框架是Java7提供的一个用于并行执行任务的框架,是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。
Fork/Join框架需要理解两个点,「分而治之」和「工作窃取」。
分而治之
 工作窃取
工作窃取
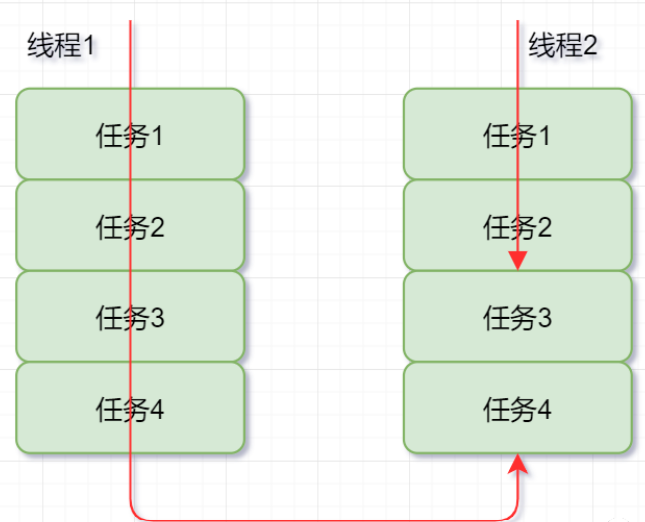
备注:一般就是指做得快的线程(盗窃线程)抢慢的线程的任务来做,同时为了减少锁竞争,通常使用双端队列,即快线程和慢线程各在一端。
ThreadLocal原理
ThreadLocal的内存结构图:
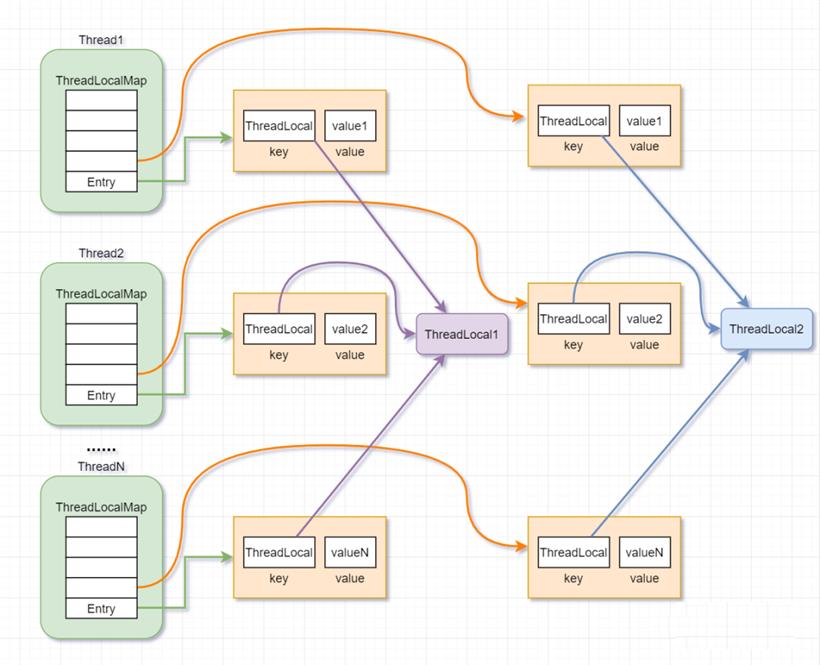
Thread线程类有一个类型为ThreadLocal.ThreadLocalMap的实例变量threadLocals,即每个线程都有一个属于自己的ThreadLocalMap。
ThreadLocalMap内部维护着Entry数组,每个Entry代表一个完整的对象,key是ThreadLocal本身,value是ThreadLocal的泛型值。
并发多线程场景下,每个线程Thread,在往ThreadLocal里设置值的时候,都是往自己的ThreadLocalMap里存,读也是以某个ThreadLocal作为引用,在自己的map里找对应的key,从而可以实现了线程隔离。
备注:内存泄露问题:指程序中动态分配的堆内存由于某种原因没有被释放或者无法释放,造成系统内存的浪费,导致程序运行速度减慢或者系统奔溃等严重后果。内存泄露堆积将会导致内存溢出。
ThreadLocal的内存泄露问题一般考虑和Entry对象有关,ThreadLocal::Entry被弱引用所修饰。JVM会将弱引用修饰的对象在下次垃圾回收中清除掉。这样就可以实现ThreadLocal的生命周期和线程的生命周期解绑。但实际上并不是使用了弱引用就会发生内存泄露问题,考虑下面几个过程:
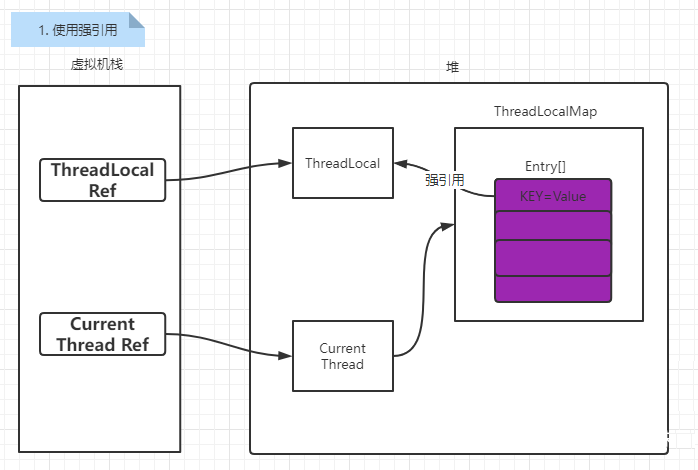
当ThreadLocal Ref被回收了,由于在Entry使用的是强引用,在Current Thread还存在的情况下就存在着到达Entry的引用链,无法清除掉ThreadLocal的内容,同时Entry的value也同样会被保留;也就是说就算使用了强引用仍然会出现内存泄露问题。
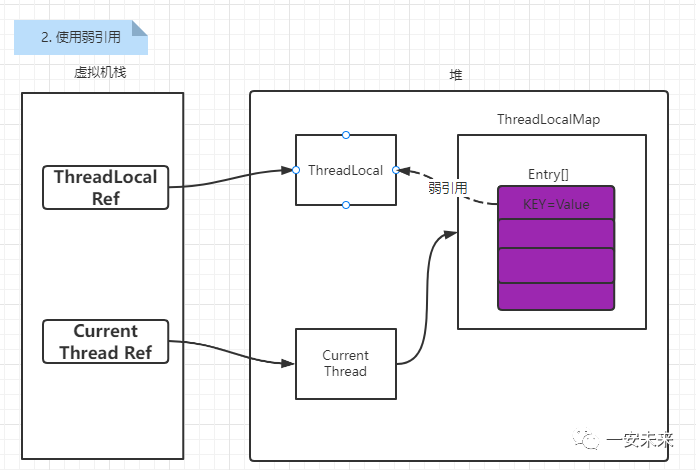
当ThreadLocal Ref被回收了,由于在Entry使用的是弱引用,因此在下次垃圾回收的时候就会将ThreadLocal对象清除,这个时候Entry中的KEY=null。但是由于ThreadLocalMap中任然存在Current Thread Ref这个强引用,因此Entry中value的值任然无法清除。还是存在内存泄露的问题。
AQS实现原理
AbstractQueuedSynchronizer(AQS)是Java中用于构建同步器的基础框架。它提供了一个灵活的、可重用的同步器实现,可以用来构建各种同步工具,如ReentrantLock、Semaphore、CountDownLatch等。AQS的核心思想是基于FIFO等待队列,通过状态(state)来管理线程的同步。
核心原理:
State(状态): AQS 的同步状态是一个整数,表示被同步的资源的状态。不同的同步器会使用不同的方式来表示状态的含义,例如,ReentrantLock 使用 state 表示持有锁的线程的数量,Semaphore 使用 state 表示可用的许可数量等。
FIFO 等待队列: AQS 使用一个FIFO的等待队列来管理获取同步资源失败的线程。每个节点(Node)表示一个等待线程,节点中保存了等待状态、前驱节点、后继节点等信息。当一个线程尝试获取锁但失败时,它会被包装成一个节点并加入到等待队列中。
独占模式和共享模式: AQS 支持独占模式和共享模式。独占模式表示只有一个线程能够获取同步资源,如ReentrantLock 就是独占模式的同步器。共享模式表示多个线程可以同时获取同步资源,如Semaphore 就是共享模式的同步器。AQS 使用 acquire 和 release 方法来分别表示获取和释放同步资源。
acquire 方法: 当线程尝试获取同步资源时,它会调用 AQS 的 acquire 方法。acquire 方法会根据同步状态的不同情况进行处理,如果同步状态允许当前线程获取资源,则直接返回;否则,当前线程会被包装成节点并加入到等待队列中,然后进入自旋等待状态,直到获取到资源。
release 方法: 当线程释放同步资源时,它会调用 AQS 的 release 方法。release 方法会根据同步状态的不同情况进行处理,然后唤醒等待队列中的下一个线程,使其有机会获取资源。
独占锁和共享锁的实现: AQS 提供了独占锁的实现方法 tryAcquire 和 tryRelease,以及共享锁的实现方法 tryAcquireShared 和 tryReleaseShared。
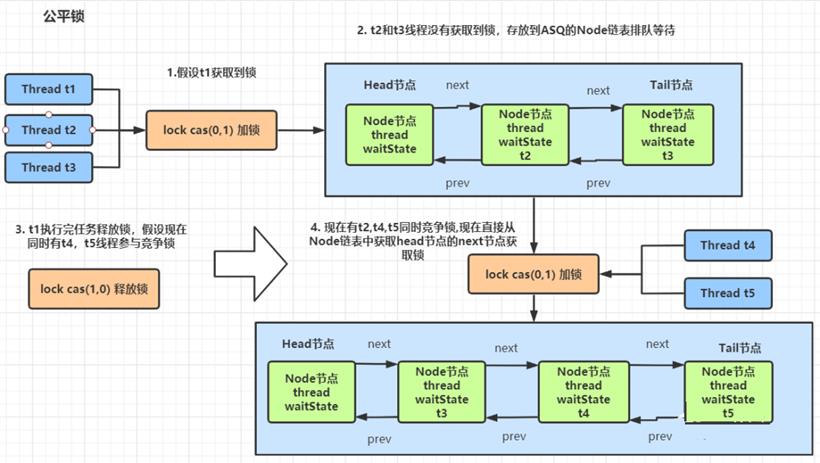
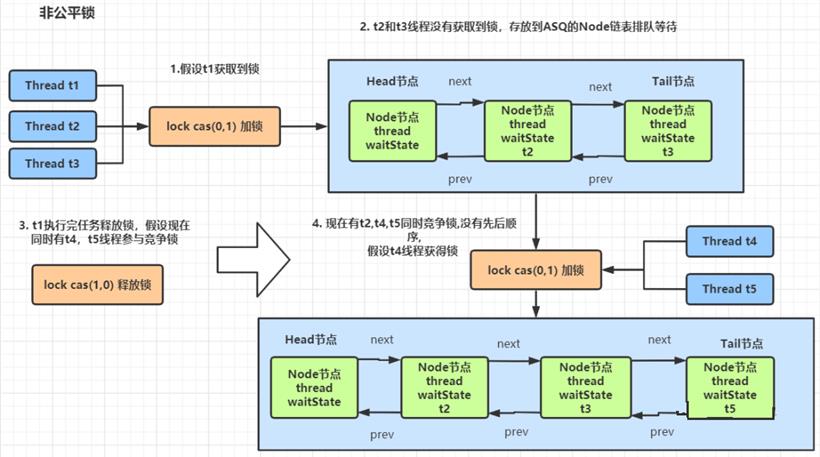
ReentrantLock 解析:
上下文切换
CPU上下文:CPU 寄存器,是CPU内置的容量小、但速度极快的内存。而程序计数器,则是用来存储 CPU 正在执行的指令位置、或者即将执行的下一条指令位置。它们都是 CPU 在运行任何任务前,必须的依赖环境,因此叫做。
CPU上下文切换:把前一个任务的CPU上下文(也就是CPU寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
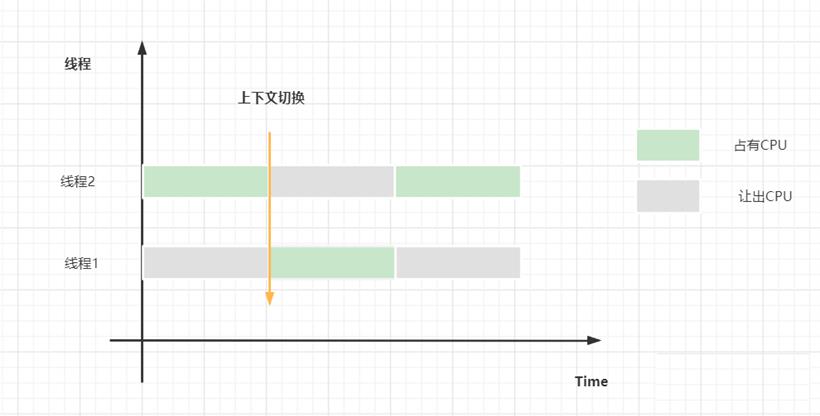
分时调度:让所有的线程轮流获得CPU的使用权,并且平均分配每个线程占用的 CPU 的时间片。
抢占式调度:优先让可运行池中优先级高的线程占用CPU,如果可运行池中的线程优先级相同,那么就随机选择一个线程,使其占用CPU。处于运行状态的线程会一直运行,直至它不得不放弃 CPU。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






