一、背景简介
权限管控是一个应用系统最重要的基础能力之一,通常权限可以分为功能权限和数据权限,功能权限主要用来控制用户可以执行的操作,即用户可以做什么;数据权限则控制用户可以操作的对象范围,这里的对象指业务数据,数据权限进一步细化还可以分为行级权限和字段级权限,如控制用户可以查询本部门的数据,而不能查看其他部门数据,或者只能查看一条业务数据的部分字段信息。
我们接触的数据权限通常是指对某一个应用系统内部的业务数据进行管控,这些业务数据由用户的行为活动产生,如一个交易应用中的交易数据,通常用户只能查看到自己的交易记录,这就是最基本、最常见的数据权限管控策略。大数据权限系统需要管控的数据范围要大的多,包含了数据仓库中的所有表,同时管控的用户也并非普通的应用系统用户(产生数据的用户),而是数据开发人员、数据分析人员等(使用数据的用户)。本文将着重介绍某大数据权限系统的数据权限管控。
二、数据安全的重要性
随着业务的发展,数据已经成为企业和用户最重要的数字资产以及核心竞争力之一,数据安全的重要性愈发的突显,安全体系的建设更为重要和关键。为加强公司内部的数据安全和管理,减少使用数据的风险,我司数据平台团队结合公司数据安全分类分级标准,遵循最小权限原则,对公司内部的数据分析、数据服务、数据开发等各种数据使用场景进行了权限管控。
三、数据权限管控场景
数据权限的管控需求并非凭空产生,而是来自于实际使用场景的需要,尤其是数据需要透出的场景。当前需要权限管控的场景主要包括:
1.数据分析/查询场景,我司的数据分析工具主要包含开源 BI 工具 Metabase、自建的数据查询分析系统小采 DA。需要对用户查询的表、字段等进行权限管控。
2.数据开发场景,主要为数据团队自建的数据开发平台 IData。对于各个业务线在自行开发数据作业时,对开发人员使用的来源表进行权限管控。
四、面临的问题
从上述管控场景可以看到,我们需要在用户使用 Metabase、小采 DA、IData 时做数据权限管控。其中 Metabase 本身自带权限控制功能,其可以做到按数据源、图表集合、用户组的粒度分配权限,而在过去,我们也使用 Metabase 自带的权限系统做看板图表的权限控制,同时 Metabase 使用了 Presto 做查询引擎,所以基于 Presto 的 Apache Ranger 插件,使用 Apache Ranger 做更细粒度的表级权限管控。
而经过一段时间的使用后,现行的权限管控方式面临了诸多问题:
1.Metabase 和 Apache Ranger 的权限管理方式已经不能满足需要,Metabase 的权限控制粒度较粗,其粒度是数据源、集合、用户组级的,同时依赖于管理员进行权限分配,操作比较繁琐。同样 Apache Ranger 也是依赖于管理员来进行权限管控,权限配置效率低。
2.权限管理分散在多个系统中,维护成本高,如果有新增应用系统,如小采DA,需要另外再开发一套权限系统。
3.数据权限授权管理由管理员专人负责,权限管理的工作量比较大,尤其涉及到人员变化甚至部门调整时,数据权限的管理工作量会指数式增长。同时管理员也无法精准的管理每个人的数据权限,易发生数据越权风险。
4.数据安全对细粒度权限管理的需求日益增长,难以满足精细化权限控制的需求。各自独立的权限系统,无法和公司内部其他安全系统结合,如和数据平台的分类分级信息打通;不利于权限的集中授权,无法做到一次授权,多方(多个数据平台)使用。同时难以做到数据查询的事中监控和事后审计。
五、新的权限系统建设目标
综合上述问题,我们提出了新的权限管理系统建设目标:
1.降低权限管理的成本,从管理员分配权限的方式改为用户自主按需申请数据权限(最小化权限原则),审批流程结合数据分级,引入多方参与审批把关,包含用户团队 leader(对本次申请负责)、数据相关方(对数据透出把关)、安全团队(高敏感性和高价值数据)。
2.权限集中管理、统一鉴权,其他应用的权限管控统一对接权限系统。做到一次授权,多方(多个数据平台)使用。同时可以满足事后审计、溯源需求。
3.支持表级、字段级、行级、Metabase 看板和报表等各种粒度的权限管控,打通元数据的分类分级信息。
六、权限系统设计实现
权限模型
在设计大数据权限系统过程中,我们主要调研了两种权限模型,一种是大家比较熟悉的 RBAC 模型(基于角色的权限控制模型),一种则是 ABAC 模型(Attribute-Based Access Control,基于属性的权限控制模型)。
RBAC
RBAC 模型是一个最常用的权限控制模型,以角色为粒度来管理资源的权限,根据用户分配的角色来鉴权。模型简单易理解,适用于大型组织的权限管理,根据用户的组织架构、用户岗位特性等预先定义角色,然后将角色分配给用户,简化权限管理流程。我们使用 RBAC 模型做功能权限的控制,这里不做过多描述。
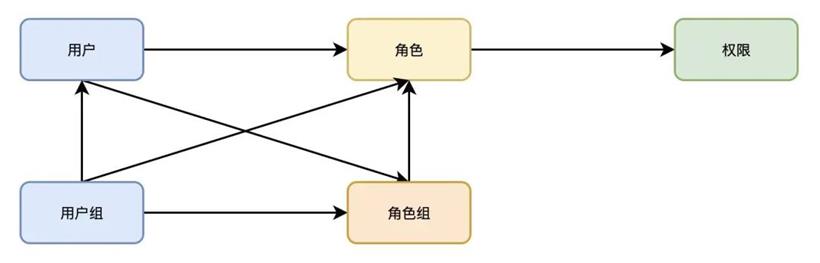 ABAC
ABAC
基于属性的权限控制(Attribute-Based Access Control,简称 ABAC)模型,一种非常灵活的授权模型。ABAC 模型更适用于动态权限分配的场景,可以灵活地控制用户的访问权限。但是 ABAC 模型的权限系统实现起来比较复杂。我们根据自身的实际需要,借鉴了 ABAC 模型的思想,设计了符合我们实际需要的数据权限模型。
数据权限模型主要分为几部分:
授权主体:授权主体即权限授予的对象,我们授权是基于用户、用户组的,即数据权限可以直接授权给一个用户,同时为了简化数据权限的申请,我们可以创建一个用户组,由该用户组的管理员申请用户组权限,申请完后,用户组中的所有用户默认拥有已申请的权限。
授权资源:我们将数据权限管控范围内的表、字段、行级数据、看板等抽象为授权资源。用户申请权限是即是对这些资源的权限申请。
授权操作:授权操作是用户可以对资源的操作,如读、写等。
授权环境:授权环境是用户对资源进行某些操作时的环境属性,如集群环境、有效时间等。
以上由授权主体、授权资源、授权操作以及授权环境组合为一个权限策略,用户申请权限时即生成一条权限策略,而权限验证时,则是一个根据授权主体、授权资源、授权操作以及授权环境检索和匹配权限策略的过程。
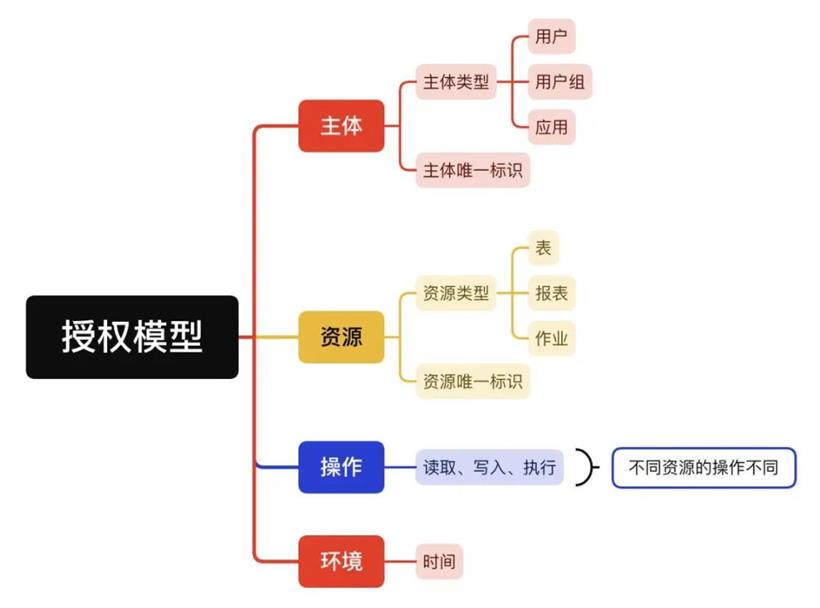 元数据和数据分级
元数据和数据分级
数据权限系统的建设离不开数仓元数据的建设,在数据权限申请、鉴权过程中都需要这些元数据的参与。对于数据的定级,我们把数据分为高、中、低三级,不同的安全等级则意味着数据不同的敏感度和价值,同时在数据权限的申请、数据的使用等场景,对于不同安全等级的权限,处理方式也不同。
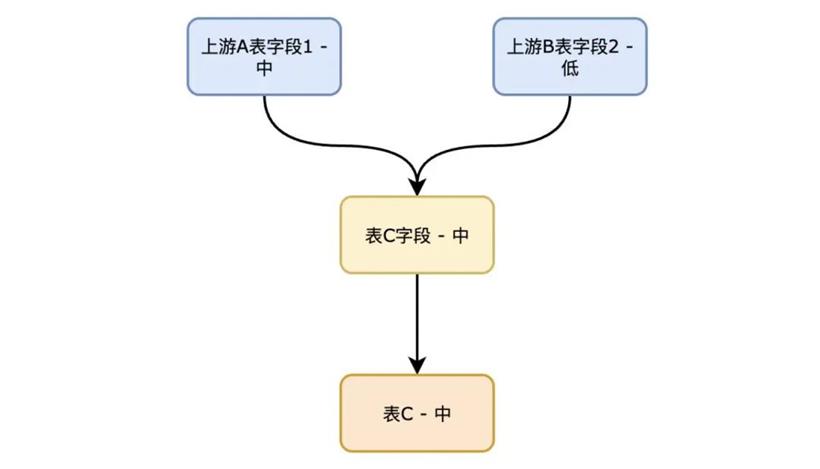
数据的安全等级来源于安全团队对于数仓上游业务表字段的打标,数据平台根据数据开发作业中的字段血缘关系,自动将安全等级从上游表的字段继承到下游表的字段,并从字段安全等级推断出表的安全等级。安全等级的继承和推断过程中,采用就高不就低的原则。即如果下游表的一个字段从上游不同表的不同字段计算产生,则依据上游表字段的最高安全等级产生。
表的安全等级由表的字段安全等级推断产生,包含高安全等级字段的表,则表的安全等级也为高。表的安全等级会影响权限申请的审批流程,高安全等级的表的申请流程需要更多角色参与。
申请了表权限后,可以查看表里低安全等级的字段数据,中、高安全等级的字段数据则会以脱敏或加密的方式呈现。
安全等级继承推断过程:
 数据权限验证
数据权限验证
权限系统提供了统一的权限数据查询和验证接口,以供数据平台其他应用的对接和调用。而不同的大数据查询引擎,对于权限检验的实现方案则有所不同。Metabase 系统使用 了 Presto 作为查询引擎,自建的小采 DA 应用则使用 Presto 或 Starrocks 查询数据。

对于 Presto 查询引擎,我们基于 Presto 的权限控制插件体系,实现了对于表、Metabase 看板的权限验证,中高安全等级的字段脱敏加密,以及行级数据权限的查询过滤。Starrocks 则没有类似的权限控制插件体系,所以在客户端实现 SQL 解析,根据解析出的表做权限控制。
 七、小结
七、小结
综上,我们简要讲述了某大数据权限系统的建设背景、目标、以及设计和实现。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






