为了在管理数据的系统中实现容错性,数据需要在多台服务器上进行复制。同时,向客户端提供关于数据一致性的保证也十分重要。
当数据在多台服务器上进行更新时,需要确定何时将更新的数据对客户端可见。仅依靠写入和读取多数派仲裁(Majority Quorum)并不足够,因为在某些故障场景下,可能会导致客户端看到的数据不一致。单个服务器并不了解仲裁集内其他服务器上数据的状态,只有当从多台服务器读取数据时,才能解决这些不一致性问题。但在某些情况下,这还不够,需要对发送给客户端的数据提供更强的一致性保证。
主从复制模式代表整个集群做出决策并将决策传播到所有其他服务器。每台服务器在启动时都会寻找存在的领导者。如果没有找到领导者,则会触发一次领导者选举。服务器们只有在成功选出领导者之后才会接受请求。只有领导者才会处理客户端的请求。如果请求直接发送给了跟随者服务器,跟随者会将请求转发给领导者服务器。
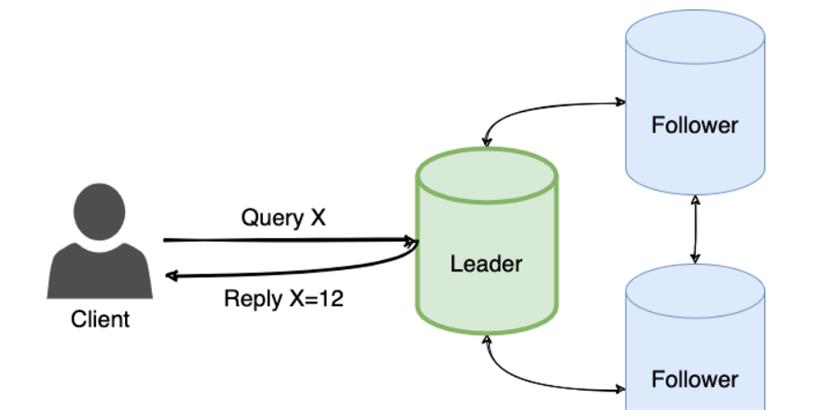 Leader 选举
Leader 选举
在规模较小的包含三到五个节点的集群中,比如那些实现了共识算法的系统,Leader 选举可以直接在数据集群内部完成,无需依赖任何外部系统。Leader 的选举发生在服务器启动阶段或者 Leader 失联阶段。每台服务器在启动时都会发起一次 Leader 的选举并尝试选出领导者。除非选举出 Leader,否则系统不会接受任何客户端请求。服务器只能处于三种状态之一:Leader、Follower 或寻找领导者(有时也称为 Candidate)。
目前有两个主流的、具有细微差别的领导者选举算法实现:ZooKeeper 实现中的 Zab ,以及 Raft 中的算法。
它们之间的差异包括 generation number 增加的时机、服务器启动时的默认状态,以及如何确保避免分裂投票。在 Zab 中,每台服务器在启动时都会寻找 Leader,generation number 仅在服务器当选为 Leader 时由 Leader 自身递增,通过确保在多台服务器同样是最新的状态下运行相同的逻辑来选择 Leader,从而避免分裂投票的情况。而对于 Raft,服务器默认以 Follower 状态启动,期望从现有 Leader 那里接收到心跳信号。如果没有收到心跳,它们会通过递增 generation number 来启动选举。为了避免分裂投票,Raft 采用了在启动选举前使用随机化超时的方式。
那么基于什么选举领导呢,或者凭什么你那么优秀被选为领导?基于两个因素:
1.由于这些系统主要用于数据复制,这就对哪些服务器能够赢得选举施加了一些额外的限制。只有保持“最新状态”的服务器才有可能成为合法的领导者。例如,在典型的基于共识的系统中,“最新状态”由两个要素来界定:
.最新的时钟(Generation Clock)
.日志中最新的写前日志索引(Write-Ahead Log Index)
2.如果所有服务器的数据更新程度均等,则会根据 - 某些实现特定的标准来选择领导者,比如哪台服务器排名更高或者具有更高的标识符(如 Zab 协议中常见的服务器 ID) - 若确保每次仅有一台服务器请求投票,则最先发起选举的服务器(例如 Raft 协议中的服务器)将有机会胜出。这意味着,只要精心设计确保同一时间内仅有一个服务器发起选举请求,那么率先开始选举过程的服务器便可能成为领导者。
在较小规模的数据集群中运行领导者选举机制效果良好。而对于拥有数千个节点的大规模数据集群来说,采用像 ZooKeeper 或 etcd 这样的强一致核心组件更为便捷,这些组件内部使用共识机制并提供线性化保证。在这样的大型集群中,通常会标记一台服务器作为主服务器或控制器节点,代表整个集群做出所有决策。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号