除非你一直生活在岩石下面,否则你可能已经知道微服务是当今流行的架构趋势。与这一趋势一同成长,Segment早期就采用了这种最佳实践,这在某些情况下对我们很有帮助,但正如你将很快了解到的,在其他情况下则并非如此。
简单来说,微服务是一种面向服务的软件架构,其中服务器端应用程序通过组合许多单一用途、低开销的网络服务构建。微服务的好处包括提高模块化、减少测试负担、改进功能组合、环境隔离和开发团队自治。与之相对的是单体架构,在单体架构中,大量功能存在于一个服务中,该服务作为一个单元进行测试、部署和扩展。
在2017年初,我们的核心产品之一达到了一个临界点。看起来我们从微服务树上掉下来,碰到了每一个分支。小团队不仅没能更快地推进工作,反而陷入了不断增加的复杂性之中。微服务架构的本质优势变成了负担。我们的开发速度急剧下降,缺陷率迅速上升。
最终,团队发现自己无法取得进展,三名全职工程师大部分时间都在维持系统的正常运行。必须做出改变。这篇文章讲述了我们如何退一步,采用一种更符合我们产品需求和团队需求的方法。
[微服务的优势]
Segment的客户数据基础设施每秒处理数十万个事件并将其转发到合作伙伴的API,我们称之为服务器端目的地。有超过一百种这样的目的地,如Google Analytics、Optimizely或自定义的webhook。
几年前,当产品首次推出时,架构非常简单。有一个API接收事件并将其转发到一个分布式消息队列中。事件在这里指的是由Web或移动应用生成的JSON对象,包含有关用户及其行为的信息。一个示例负载如下所示:
当事件从队列中被消费时,会检查客户管理的设置以决定哪些目的地应接收该事件。然后,事件依次发送到每个目的地的API,这对开发人员很有用,因为他们只需将事件发送到一个端点,即Segment的API,而无需构建多个集成。Segment负责向每个目的地端点发出请求。
如果对某个目的地的请求失败,有时我们会尝试在稍后时间再次发送该事件。有些失败是可以重试的,而有些则不行。可重试的错误是那些可能被目的地接受的错误,例如HTTP 500、速率限制和超时。不可重试的错误是那些我们确定目的地永远不会接受的请求,例如无效凭据或缺少必填字段的请求。
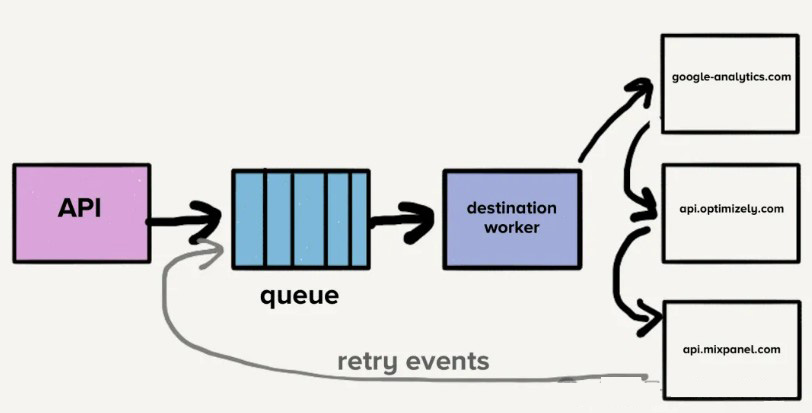
此时,一个队列中包含了最新的事件以及那些可能已重试多次的事件,涉及所有目的地,导致了队首阻塞的问题。换句话说,如果一个目的地变慢或宕机,重试请求会充斥队列,导致所有目的地的延迟。
假设目的地X出现临时问题,每个请求都会超时。这不仅会创建一个大的请求积压,还会导致每个失败的事件在队列中重试。虽然我们的系统会自动扩展以应对增加的负载,但队列深度的突然增加会超出我们的扩展能力,导致最新事件的延迟。所有目的地的交付时间都会增加,因为目的地X出现了短暂的故障。客户依赖于交付的及时性,所以我们不能在管道的任何地方容忍等待时间的增加。
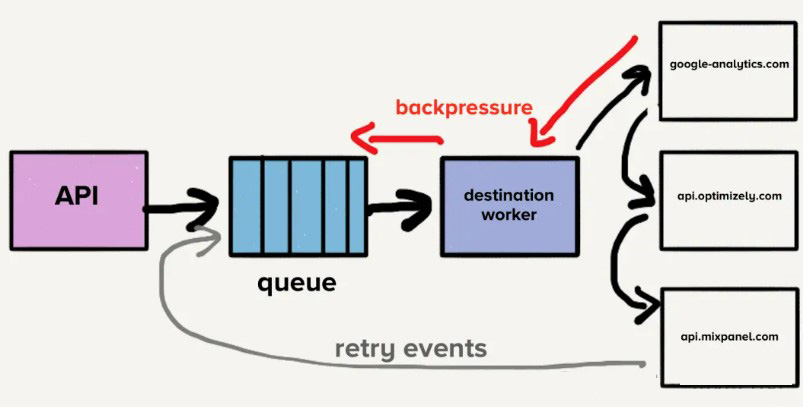
为了解决队首阻塞问题,团队为每个目的地创建了一个单独的服务和队列。这种新架构包括一个额外的路由进程,该进程接收入站事件并将事件的副本分发到每个选定的目的地。现在,如果一个目的地出现问题,只有它的队列会积压,其他目的地不会受到影响。这样的微服务架构将各个目的地彼此隔离,这在一个目的地频繁出现问题时尤其重要。
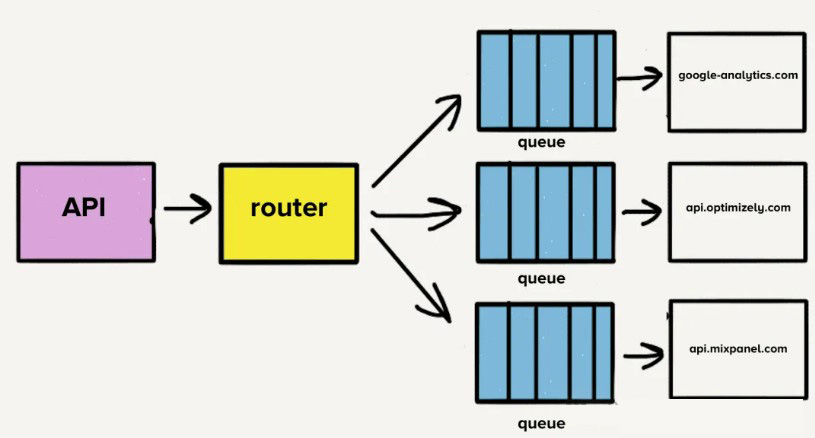 [独立代码库的理由]
[独立代码库的理由]
每个目的地API使用不同的请求格式,需要自定义代码将事件转换为匹配的格式。一个基本的例子是目的地X需要将生日发送为traits.dob,而我们的API接受traits.birthday。目的地X的转换代码可能如下所示:
许多现代目的地端点已经采用了Segment的请求格式,使得某些转换相对简单。然而,这些转换可能非常复杂,具体取决于目的地API的结构。例如,对于一些较旧且非常庞大的目的地,我们需要将值插入手工制作的XML负载中。
最初,当目的地被分成单独的服务时,所有代码都在一个代码库中。一个巨大的挫折点是单个失败的测试会导致所有目的地的测试失败。当我们想部署一个更改时,即使这些更改与初始更改无关,我们也必须花时间修复失败的测试。为了解决这个问题,决定将每个目的地的代码拆分到各自的代码库中。所有目的地已经分离成各自的服务,所以这一转变是自然的。
拆分成独立的代码库使我们能够轻松地隔离目的地的测试套件。这种隔离使开发团队在维护目的地时能够快速行动。
[扩展微服务和代码库]
随着时间的推移,我们增加了50多个新目的地,这意味着50多个新代码库。为了减轻开发和维护这些代码库的负担,我们创建了共享库,以便在所有目的地之间简化常见的转换和功能,例如HTTP请求处理。
例如,如果我们想从事件中获取用户的名字,可以在任何目的地的代码中调用event.name()。共享库会检查事件中的属性键name和Name。如果这些不存在,它会检查firstName、first_name和FirstName。对于姓氏,它会以相同方式检查这些属性,并将两个名字组合形成全名。共享库使构建新目的地变得快捷。统一的一组共享功能带来的熟悉感使维护变得不再头疼。
然而,新的问题开始出现。测试和部署这些共享库的更改影响了我们所有的目的地。维护这些代码库需要大量时间和精力。进行改进时,我们需要测试和部署几十个服务,这是一个高风险的任务。在时间紧迫时,工程师们只会在单个目的地的代码库中包含更新版本的共享库。
随着时间的推移,这些共享库的版本在不同目的地的代码库之间开始分化。我们曾经在减少定制化方面的巨大优势开始逆转。最终,所有目的地都在使用不同版本的共享库。我们本可以构建工具来自动化部署更改,但此时,不仅开发人员的生产力受到了影响,我们还遇到了微服务架构的其他问题。
另一个问题是每个服务都有不同的负载模式。一些服务每天处理少量事件,而其他服务每秒处理数千个事件。对于处理少量事件的目的地,每当负载出现意外峰值时,操作员必须手动扩展服务。虽然我们确实实施了自动扩展,但每个服务所需的CPU和内存资源不同,使得自动扩展配置更像是一门艺术而不是科学。
随着目的地数量的迅速增加,团队平均每月增加三个目的地,这意味着更多的代码库、更多的队列和更多的服务。我们的微服务架构导致了操作开销与增加的目的地数量成线性增长。因此,我们决定退一步,重新思考整个管道。
[放弃微服务和队列]
列表上的第一项是将现在超过140个服务合并为一个服务。管理所有这些服务的开销对我们的团队来说是一个巨大负担。我们的工程师经常因为负载峰值被叫醒,导致我们无法安然入睡。然而,当时的架构使得迁移到单一服务变得具有挑战性。每个目的地都有一个单独的队列和服务。这意味着我们必须重构每个队列中的消息处理逻辑。我们决定从零开始构建一个新的目的地系统。
我们的目标是创建一个单一的、共享的队列,所有事件在这里排队,并由一个共享的目的地处理器进行处理。新的架构避免了我们在微服务架构中遇到的队首阻塞和队列深度增加的问题。
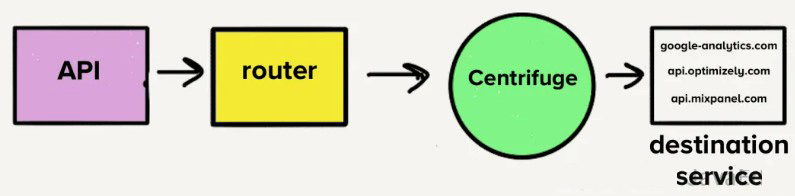
新的目的地处理器被设计为单一服务,处理所有目的地的事件。这不仅减少了服务数量,还减少了代码库和测试套件的数量。我们保留了共享库的优势,但将其整合到一个更统一的系统中。这次重构使我们能够减少运维开销,并且由于所有事件都在一个队列中处理,我们能够更好地处理负载峰值。我们还实现了更细粒度的负载控制,使我们能够根据负载分布调整资源。
新的架构不仅提高了系统的可靠性,还大大改善了我们的开发效率。我们的团队不再被琐碎的运维任务束缚,可以专注于提供更多客户价值。这段旅程教会我们,微服务并不总是最佳选择。尽管它们在特定情况下具有显著优势,但对于某些工作负载和团队规模而言,单体架构可能更加高效和易于管理。
通过这一旅程,我们学到了宝贵的经验。微服务架构的好处不言而喻,但我们也要意识到其带来的复杂性和管理成本。最终,我们找到了一种平衡,使我们的系统更加稳定和高效。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






