

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

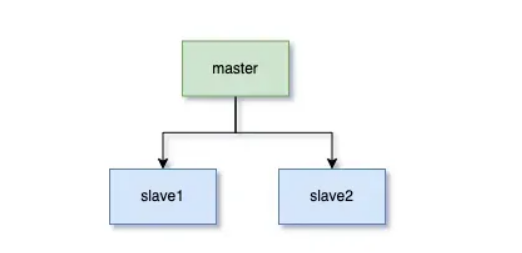
-- 主库配置 CHANGE MASTER TO MASTER_HOST='master_host', MASTER_USER='replica_user', MASTER_PASSWORD='password', MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=154; -- 从库启动复制 START SLAVE;效果:主库宕机时,从库自动切换为可读写状态,业务无感知。
CircuitBreakerConfig config = CircuitBreakerConfig.custom()
.failureRateThreshold(50) // 失败率超过50%触发熔断
.waitDurationInOpenState(Duration.ofMillis(1000))
.build();
CircuitBreaker circuitBreaker = CircuitBreaker.of("paymentService", config);
// 堆代码 duidaima.com
// 调用支付服务
Supplier<String> supplier = () -> paymentService.call();
Supplier<String> decoratedSupplier = CircuitBreaker
.decorateSupplier(circuitBreaker, supplier);
效果:当支付服务失败率飙升时,自动熔断并返回降级结果(如“系统繁忙,稍后重试”)。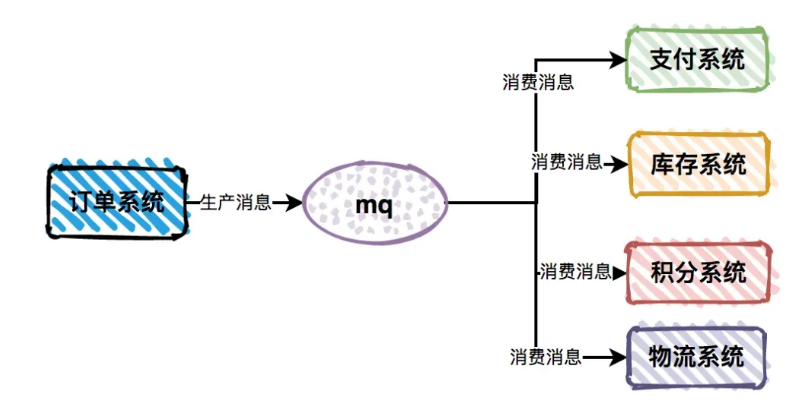
DefaultMQProducer producer = new DefaultMQProducer("seckill_producer");
producer.setNamesrvAddr("127.0.0.1:9876");
producer.start();
Message msg = new Message("seckill_topic", "订单数据".getBytes());
producer.send(msg);
效果:将瞬时10万QPS的请求平滑处理为数据库可承受的2000 TPS。apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: order-service-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: order-service
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60
效果:CPU利用率超过60%时自动扩容,低于30%时自动缩容。apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: bookinfo
spec:
hosts:
- bookinfo.com
http:
- route:
- destination:
host: reviews
subset: v1
weight: 90 # 90%流量走老版本
- destination:
host: reviews
subset: v2
weight: 10 # 10%流量走新版本
效果:新版本异常时,仅影响10%的用户,快速回滚无压力。@ApolloConfig
private Config config;
public ProductDetail getDetail(String productId) {
if(config.getBooleanProperty("recommend.switch", true)) {
// 调用推荐服务
}
// 返回基础商品信息
}
效果:关闭推荐服务后,详情页响应时间恢复至200ms以内。sharding:
tables:
user:
actualDataNodes: ds_${0..1}.user_${0..15}
tableStrategy:
standard:
shardingColumn: user_id
preciseAlgorithmClassName: HashModShardingAlgorithm
preciseAlgorithmType: HASH_MOD
shardingCount: 16
效果:10亿数据分散到16个物理表,查询性能提升20倍。# 模拟网络延迟 blade create network delay --time 3000 --interface eth0 # 模拟数据库节点宕机 blade create docker kill --container-id mysql-node-1效果:提前发现缓存穿透导致DB负载过高的问题,优化缓存击穿防护策略。
.数据驱动的优化才是王道(全链路压测+立体监控)




