

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

@Cacheable(clusterId = "cluster1", prefix = "user", keys = {"#userId"})
public User getUserById(Long userId) {
return userRepository.findById(userId);
}
@UpdateCache(clusterId = "cluster1", prefix = "user", keys = {"#userId"})
public User update(User user) {
return userRepository.update(user);
}
基于常见的缓存问题和场景,切面应该实现以下功能: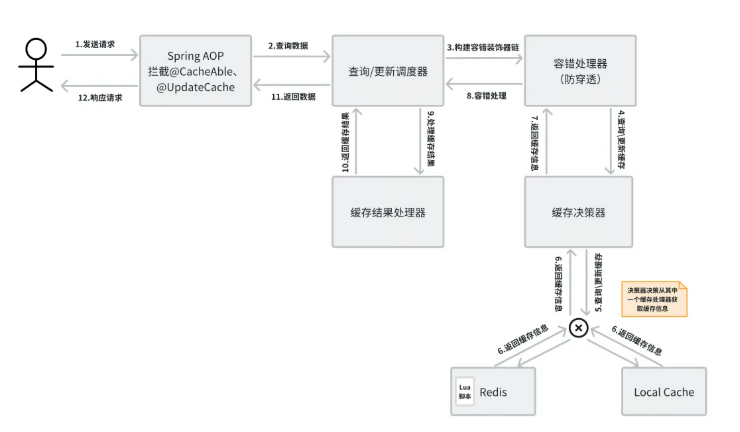
弹性数据一致性保障:执行Lua脚本保证一组缓存操作的原子性。支持设置数据库缓存不一致时间,默认为1.5s,框架在1.5s后保证最终一致性。当用户设置不一致时间为0s时,框架保证实时一致性。
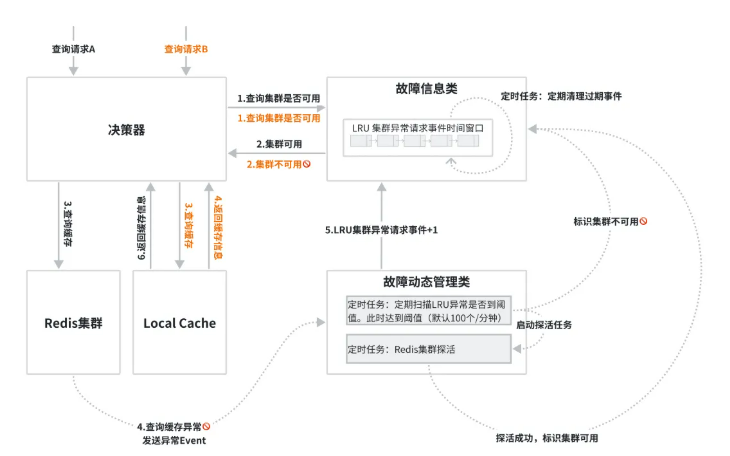
5.当集群探活成功后,会标识集群可用,此时探活定时任务关闭,后续查询请求会优先请求Redis,实现缓存升级。
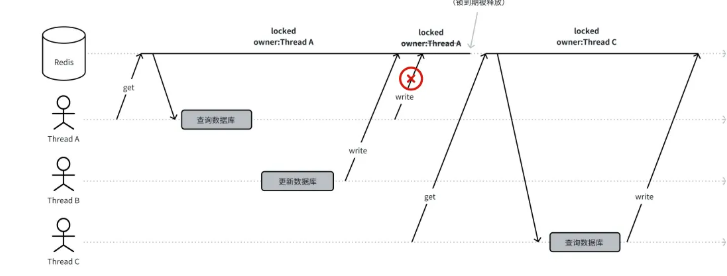
其中,owner、lockInfo、unlockTime基于Lua脚本执行的原子性实现了一个分布式锁。
private staticfinal String GET_SH =
"local key = KEYS[1]\n"
+ "local newUnlockTime = ARGV[1]\n"
+ "local owner = ARGV[2]\n"
+ "local currentTime = tonumber(ARGV[3])\n"
+ "local value = redis.call('HGET', key, '" + VALUE + "')\n"
+ "local unlockTime = redis.call('HGET', key, '" + UNLOCK_TIME + "')\n"
+ "local lockOwner = redis.call('HGET', key, '" + OWNER + "')\n"
+ "local lockInfo = redis.call('HGET', key, '" + LOCK_INFO + "')\n"
+ "if unlockTime and currentTime > tonumber(unlockTime) then\n"
+ " redis.call('HMSET', key, '" + LOCK_INFO + "', 'locked', '" + UNLOCK_TIME + "', 'newUnlockTime', '" + OWNER + "', owner)\n"
+ " return {value, '" + NEED_QUERY + "'}\n"
+ "end\n"
+ "if not value or value == '' then\n"
+ " if lockOwner and lockOwner ~= owner then\n"
+ " return {value, '" + NEED_WAIT + "'}\n"
+ " end\n"
+ " redis.call('HMSET', key, '" + LOCK_INFO + "', 'locked', '" + UNLOCK_TIME + "', newUnlockTime, '" + OWNER + "', owner)\n"
+ " return {value, '" + NEED_QUERY + "'}\n"
+ "end\n"
+ "if lockInfo and lockInfo == 'locked' then \n"
+ " return {value, '" + SUCCESS_NEED_QUERY + "'}\n"
+ "end\n"
+ "return {value , '" + SUCCESS + "'}";
"取数据"操作定义:查询数据库并更新缓存。如果满足以下两个条件之一,则需要更新缓存:2.数据锁定已过期
private staticfinal String INVALID_SH =
"local key = KEYS[1]\n"
+ "local newUnlockTime = tonumber(ARGV[1])\n"
+ "redis.call('HDEL', key, '" + OWNER + "')\n"
+ "local value = redis.call('HGET', key, '" + VALUE + "')\n"
+ "redis.call('HSET', key, '" + LOCK_INFO + "', 'locked')\n"
+ "if not value or value == '' then\n"
+ " return {true, '" + EMPTY_VALUE_SUCCESS + "'}\n"
+ "end\n"
+ "if newUnlockTime > 0 then\n"
+ " redis.call('HSET', key, '" + UNLOCK_TIME + "', newUnlockTime)\n"
+ "end\n"
+ "return {'', '" + SUCCESS + "'}";
2.4.1 数据一致性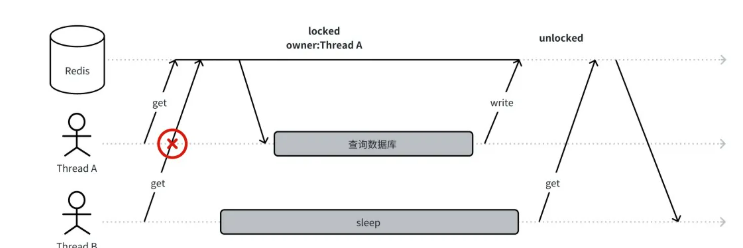
2.网络IO开销:Lua脚本传输
更大的性能开销来自于网络IO。以获取缓存值的操作为例,每次都需要传输完整的Lua脚本,脚本大小约为500 bytes。在高并发场景下,这个网络开销会迅速累积,成为性能瓶颈。| 特性\命令方式 | EVAL | EVALSHA |
|---|---|---|
| 脚本传输 | 每次传输完整脚本 | 仅传输脚本对应SHA1哈希值 |
| 性能 | 较低(网络开销大) | 较高(适合频繁调用) |
| 适用场景 | 一次性脚本或调试 | 生产环境高频调用的脚本 |
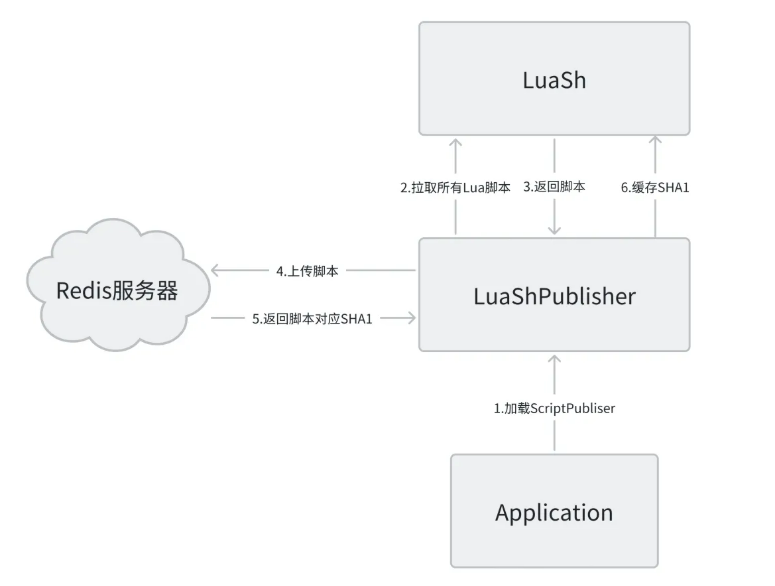
哈希值记录:将Redis返回的SHA1哈希值记录到本地缓存中
成功退出:当所有脚本都成功上传后,重试任务会自动退出
统一规范:所有缓存操作遵循相同模式





