

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

C源程序需要经过预处理、编译、汇编几个阶段,得到各自源文件对应的可重定位目标文件,可重定位目标文件就是各个源文件的二进制机器代码,一般是.o格式。比如:util1.c、util2.c及main.c三个C源文件,经过预处理器、编译器、汇编器的处理,就可以得到各自的目标文件util1.o,util2.o以及main.o。
可重定位目标文件中的地址是从0开始的,需要链接器将若干个可重定位目标文件通过符号解析、重定位等工作,链接成为一个可执行的二进制目标文件。在Linux下,可以使用gcc -c 对源文件进行预处理、编译、汇编,得到目标文件:
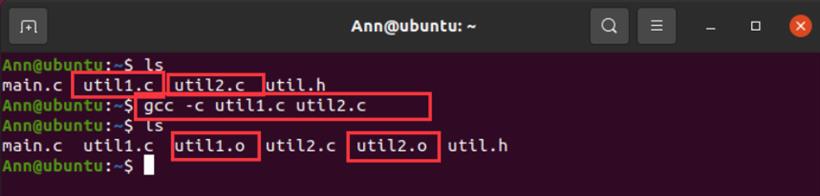
//util1.c
int add(int a,int b)
{
return a + b;
}
//堆代码 duidaima.com
//util2.c
int mult(int a,int b)
{
return a * b;
}
util.h中包含了对这两个函数的声明。 main.c使用其中的add函数:#include <stdio.h>
#include "util.h"
int main()
{
int a = 5;
int b = 10;
int c = add(a,b);
printf("%d\n",c);
return 0;
}
实际上,所有的编译系统都提供一种机制,将所有相关的目标模块(即目标文件)打包成为一个单独的文件,称为静态库。在Linux中,静态库以一种被称为存档(archive)的文件格式存放在磁盘中。存档文件由后缀.a标识,.a格式的存档文件是一组连接起来的可重定位目标文件的集合,有一个头部用来描述每个成员目标文件的大小和位置。C标准定义了许多静态库,如标准IO操作scanf,printf,字符串操作strcpy等,它们在libc.a库中;一些浮点数学函数如sin,cos等,它们在libm.a库中。

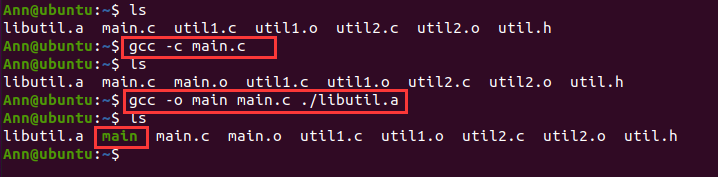

事实上是可以的,不过,这种设计有一个很大的缺点是系统中的每个可执行文件都要包含这个整个的大的目标模块的完全副本,这样做很浪费存储空间。比如,C标准的libc.a大约5MB,现在有一台机器装载了15个用到了C标准库的可执行文件,那么这15个可执行文件里每一个实际上都经过链接器的链接,嵌入了libc.a库中的5MB目标代码,而实际上它们可能用到5MB目标代码里的很小一部分(比如,某个目标文件可能只引用了标准库中的strcpy函数),这样,造成了严重的存储空间浪费。
而静态库实际上提供了这样一种功能:相关的函数可以被编译为独立的目标模块,然后封装成一个单独的静态库文件,当链接器构造一个可执行文件时,它只“提取”静态库里被应用程序引用的目标模块(换句话说,对于程序中用不到的,链接器不会将它复制到可执行文件中去),比如例子中main.c只用到了add函数,链接器就只会将库libutil.a中的multi1模块复制到可执行文件,而不会复制multi2模块。





