

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

6.支持Linux、Mac系统
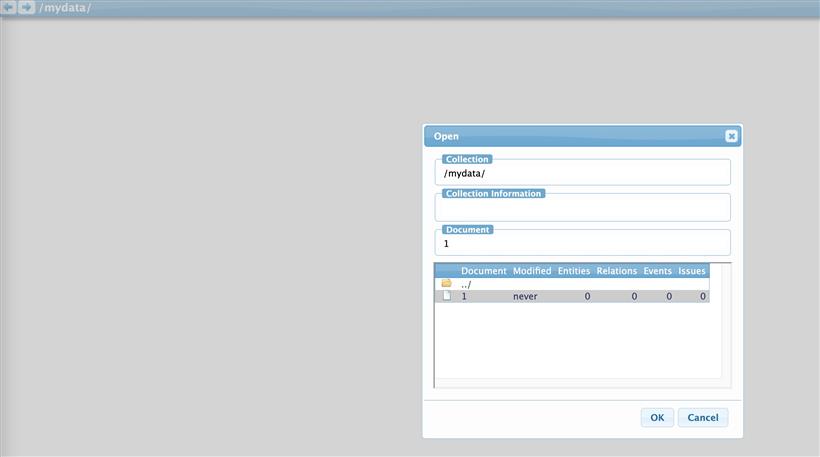
[entities] person act like hate [relations] Act-Person Arg1:<ENTITY>, Arg2:<ENTITY> [events] [attributes]这里我只需要对实体和关系进行标注,比如我需要标注实体:人物,动作(包含喜欢/讨厌);关系:人物和动作的关系 当我们在网页server端打开/mydata/1.txt后,可以如下图开始标注了
[labels] person | 人名 like | 喜欢 hate | 讨厌 [drawing] SPAN_DEFAULT fgColor:black, bgColor:lightgreen, borderColor:darken ARC_DEFAULT color:black, arrowHead:triangle-5 person bgColor:yellow, borderColor:red like bgColor:green, borderColor:red hate bgColor:gray, borderColor:red接下来,就会在标注的页面看到如下所示了。
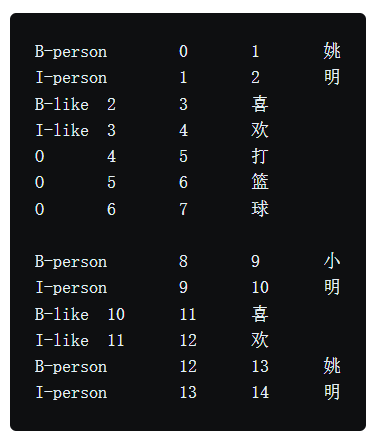
import os
import sys
def read_file(file_path):
with open(file_path, 'r',encoding='utf8') as file:
lines = file.readlines()
return lines
def write_file(file_path, lines):
with open(file_path, 'w',encoding='utf8') as file:
for line in lines:
file.write(line)
def check_one_file(conll_path, ann_path):
# check process: 针对conll文件进行检查B开头的字符是否通过brat转化后是正确的
ann_lines = read_file(ann_path)
conll_lines = read_file(conll_path)
begin_words, begin_index = [], []
for ann_i in ann_lines:
class_i, start_i, end_i = ann_i.split('\t')[1].split(' ')
begin_words.append('B-' + class_i)
begin_index.append(start_i)
ann_zip = dict(zip(begin_index, begin_words))
# check
new_conll = []
for conll_i in conll_lines:
if conll_i == '\n':
new_conll.append(conll_i)
else:
tag_i, start_i, end_i, word_i = conll_i.split('\t')
if start_i in begin_index:
if tag_i != ann_zip[start_i]:
new_conll.append(ann_zip[start_i] + '\t' + start_i + '\t' + end_i + '\t' + word_i)
else:
new_conll.append(conll_i)
else:
new_conll.append(conll_i)
return new_conll
if __name__ == '__main__':
sub_dir = sys.argv[1]
# sub_dir = '../data/fd'
# 生成一个保存新conll文件的文件夹
new_dir = os.path.join(sub_dir,'conll')
if not os.path.exists(new_dir):
os.mkdir(new_dir)
path_pre = []
for path_i in os.listdir(sub_dir):
if path_i.endswith('.ann'):
path_pre.append(path_i.split('.ann')[0])
for path_pre_i in path_pre:
ann_path_i = os.path.join(sub_dir,f'{path_pre_i}.ann')
conll_path_i = os.path.join(sub_dir,f'{path_pre_i}.conll')
new_conll_i = check_one_file(conll_path_i,ann_path_i)
new_path_i = os.path.join(new_dir,f'{path_pre_i}.conll')
write_file(new_path_i,new_conll_i)
print(f'Write {conll_path_i} completed!')
3.3 实体BIOE输出def bioe_transfer(tags:List[List[str]]):
"""
将BIO格式转成BIOE格式
"""
new_tags_all = []
for tags_i in tags:
new_tags = []
for i in range(len(tags_i) - 1):
tag_i = tags_i[i]
tag_after = tags_i[i + 1]
if tag_i == 'O':
new_tags.append(tag_i)
else:
if tag_i.split('-')[0] == 'B':
new_tags.append(tag_i)
else:
if tag_i == tag_after:
new_tags.append(tag_i)
else:
# 最后一个
new_tags.append('E-' + tag_i.split('-')[1])
if tags_i[-1] == tags_i[-2]:
if tags_i[-1] == 'O':
new_tags.append('O')
else:
new_tags.append('E-' + tags_i[-1].split('-')[1])
else:
new_tags.append(tags_i[-1])
new_tags_all.append(new_tags)
return new_tags_all
3.4 关系结果输出(干货)import pandas as pd
import numpy as np
import sys
# 堆代码 duidaima.com
if __name__ == '__main__':
path_txt = sys.argv[1]
line_start = []
line_end = []
line_len = []
with open(path_txt,'r',encoding='utf8') as txt_f:
txt_lines = txt_f.readlines()
num = 0
for txt_i in txt_lines:
txt_i = txt_i.split('\n')[0]
line_len.append(len(txt_i))
if num == 0:
start_i = num
else:
start_i = num + 1
line_start.append(start_i)
num = start_i + len(txt_i)
line_end.append(num)
rel_label = []
rel_index_1 = []
rel_index_2 = []
ent_index = []
ent_label = []
ent_start = []
ent_end = []
ent_words = []
with open(path_txt.split('.txt')[0] + '.ann','r',encoding='utf8') as ann_f:
ann_lines = ann_f.readlines()
for ann_i in ann_lines:
e_r_i = ann_i.split('\t')[0]
if 'R' in e_r_i:
rel_i = ann_i.split('\t')[1].split(' ')
rel_label.append(rel_i[0])
rel_index_1.append(rel_i[1].split(':')[1])
rel_index_2.append(rel_i[2].split(':')[1])
else:
rs_ent = ann_i.split('\t')
ent_index.append(rs_ent[0])
ent_words.append(rs_ent[2].strip())
rs_ent_in = rs_ent[1].split(' ')
ent_label.append(rs_ent_in[0])
ent_start.append(int(rs_ent_in[1]))
ent_end.append(int(rs_ent_in[2]) - 1)
df_ent = pd.DataFrame({'index':ent_index,'words':ent_words,'label':ent_label,'start':ent_start,'end':ent_end})
df_rel = pd.DataFrame({'label':rel_label,'ent_1':rel_index_1,'ent_2':rel_index_2})
df_line = pd.DataFrame({'txt':txt_lines,'start':line_start,'end':line_end})
ent_1_label = []
ent_1_words = []
ent_1_start = []
ent_1_end = []
ent_2_label = []
ent_2_words = []
ent_2_start = []
ent_2_end = []
txt_rep = []
txt_rep_start = []
for i in range(len(df_rel)):
ent_1_i = df_rel.loc[i,'ent_1']
ent_2_i = df_rel.loc[i,'ent_2']
ent_1_label.append(np.array(df_ent.loc[df_ent['index'] == ent_1_i,'label'])[0])
ent_1_words.append(np.array(df_ent.loc[df_ent['index'] == ent_1_i,'words'])[0])
ent_1_start.append(np.array(df_ent.loc[df_ent['index'] == ent_1_i,'start'])[0])
ent_1_end.append(np.array(df_ent.loc[df_ent['index'] == ent_1_i,'end'])[0])
ent_2_label.append(np.array(df_ent.loc[df_ent['index'] == ent_2_i, 'label'])[0])
ent_2_words.append(np.array(df_ent.loc[df_ent['index'] == ent_2_i, 'words'])[0])
ent_2_start.append(np.array(df_ent.loc[df_ent['index'] == ent_2_i, 'start'])[0])
ent_2_end.append(np.array(df_ent.loc[df_ent['index'] == ent_2_i, 'end'])[0])
# 匹配文档
ent_1_index = np.array(df_ent.loc[df_ent['index'] == ent_1_i, 'start'])[0]
df_line_i = df_line[(df_line['start'] <= ent_1_index) & (df_line['end'] >= ent_1_index)]
txt_rep_i = np.array(df_line_i['txt'])[0]
txt_rep_start_i = np.array(df_line_i['start'])[0]
txt_rep.append(txt_rep_i)
txt_rep_start.append(txt_rep_start_i)
df_rel['ent_1_label'] = ent_1_label
df_rel['ent_1_words'] = ent_1_words
df_rel['ent_1_start'] = ent_1_start
df_rel['ent_1_end'] = ent_1_end
df_rel['ent_2_label'] = ent_2_label
df_rel['ent_2_words'] = ent_2_words
df_rel['ent_2_start'] = ent_2_start
df_rel['ent_2_end'] = ent_2_end
df_rel['txt'] = txt_rep
df_rel['txt_start'] = txt_rep_start
df_rel.drop(['ent_1','ent_2'],axis=1,inplace=True)
csv_path = path_txt.split('.txt')[0] + '.csv'
df_rel.to_csv(csv_path, index=False)
print(f'Saved in {csv_path}!')
3.5 模型预测结果展示为brat(干货)






