

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

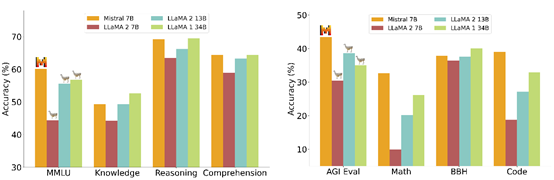
Mistral AI的开源大语言模型Mistral 7B主打参数小、能耗低、性能强等特点,并且允许商业化。支持生成文本/代码、数据微调、总结内容等,目前在github有4500颗星。
API接口:https://docs.mistral.ai/api

相比元宇宙,刚过完1岁生日的ChatGPT经受住了商业落地、用户受众等多重考验,并且带动了一大批科技公司参与到生成式AI变革中。目前,主要分为闭源和开源两大阵营。在Meta的Llama打响第一枪后,开源大语言模型领域涌现出了Writer、百川智能、Together.ai、Mistral AI等一大批优秀企业,同时获得了资本市场的认可。这些厂商也坚信,开源才是大模型通向AGI的捷径之一。
我们在欧洲开展业务,总部在法国巴黎。如果你在AI领域拥有丰富的研究、开发经验,请联系我们。当时就凭这三句话,便融了1.13亿美元种子轮融资,估值达到2.6亿美元。通常这种企业要么蹭一波热度拿完钱,随便改改模型坐着等死;要么就是扫地僧级别的技术大牛,一出手便名震天下。从本次融资结果来看,Mistral AI属于后者确实有两下子。


为了使模型能以更快的速度、更小的能耗进行推理,Mistral AI分别使用了分组查询注意力和滑动窗口注意力两大机制。分组查询注意力是对标准注意力机制的一种改进,通过对查询进行分组来减少计算复杂性。在 Transformer 模型中,注意力机制通常涉及查询、键和值的三组向量。
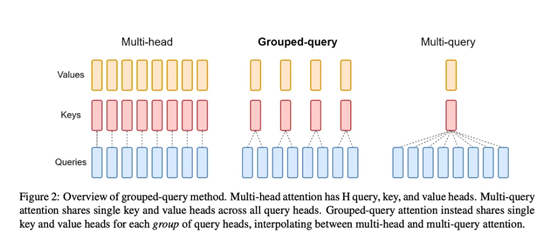
而分组查询注意力通过将多个查询合并成一个组来工作。然后,每个组的查询向量只与一部分键向量进行交互,而不是与所有键向量交互,整体效率非常高效。滑动窗口注意力是一种在序列处理任务中用来限制注意力机制的范围并减少计算量的技术。在这种方法中,每个元素的注意力不是对整个序列计算,而是仅限于其附近的一个窗口内的元素。




