在这篇关于 Mamba 的文章中,我们来探索这个创新的状态空间模型(state-space model,SSM)如何在序列建模领域带来革命性的变革。Mamba 是由 Albert Gu 和 Tri Dao 开发的,因其在语言处理、基因组学、音频分析等领域的复杂序列时表现出色而受到关注。Mamba 采用线性时间序列建模和选择性状态空间,因此在这些不同的应用领域都展现出了卓越的性能。
论文链接:https://arxiv.org/abs/2312.00752
本文,我们将深入了解 Mamba 是如何解决传统 Transformer 在处理长序列时遇到的计算挑战的。Mamba 采用在状态空间模型中的选择性方法,这不仅加快了推理速度,还实现了与序列长度的线性缩放,显著提高了处理能力。
Mamba 的特别之处在于它的快速处理能力、选择性的 SSM 层,以及受 FlashAttention 启发的硬件友好设计。这些特点使得 Mamba 在许多现有模型中脱颖而出,包括那些基于 Transformer 架构的模型,这使得 Mamba 成为机器学习领域的一个重要进步。
一.Transformer vs Mamba
Transformer,如 GPT-4,已在自然语言处理领域设定了高标准。但是,它们在处理较长的序列时效率会下降。这就是 Mamba 的优势,它不仅能更高效地处理长序列,而且其独特的架构还简化了整个处理过程。Transformer 擅长处理数据序列,如文本,用于语言模型。与之前按顺序处理数据的模型不同,Transformer 能够同时处理整个序列,捕获数据内部的复杂关系。
它们利用注意力机制,使模型在做出预测时能够关注序列的不同部分。这种注意力是通过计算输入数据中的三组权重:查询、键和值来实现的。序列中的每个元素都会与其他元素进行比较,从而得到一个权重,这个权重表示在预测序列中下一个元素时每个元素应得到的 “注意力”。
Transformer 由两个主要部分组成:编码器用于处理输入数据,解码器用于生成输出。编码器包含多个层,每层包含两个子层:一个多头自我注意力机制和一个简单的、逐位置的全连接前馈网络。每个子层都使用规范化和残差连接来帮助训练深度网络。
解码器也包含类似于编码器的层,但增加了一个对编码器输出执行多头注意力的子层。解码器的顺序性质保证了对一个位置的预测只能基于之前的位置,保持了自回归的特性。
相比之下,Mamba 采取了不同的方法。尽管 Transformer 通过使用更复杂的注意力机制来解决长序列的问题,但 Mamba 采用选择性状态空间,提供了一个更加高效的解决方案。
下面是一个关于 Transformer 工作原理的高层次概述:
输入处理:Transformer 首先将输入数据转换为模型能够理解的格式,通常是通过位置信息丰富的嵌入表示。
注意力机制:核心在于注意力机制,它计算一个得分来决定在理解当前元素时,应该将多少关注放在输入序列的其他部分。
编码器 - 解码器架构:Transformer 由一个编码器组成,用来处理输入,以及一个解码器,用来生成输出。每个部分都包含多层,以提炼模型对输入的理解。
多头注意力:编码器和解码器中的多头注意力允许模型同时关注序列的不同部分,这提高了它从多样化上下文中学习的能力。
逐位置前馈网络:经过注意力处理后,一个简单的神经网络独立且统一地处理每个位置的输出,通过残差连接与输入结合,并进行层规范化。
输出生成:接着解码器预测一个输出序列,这个过程受到编码器上下文的影响以及它到目前为止生成的内容。
Transformer 凭借其并行处理序列的能力和强大的注意力机制,在翻译和文本生成等任务中表现出色。
Mamba 模型则采用不同的方式运作,它使用选择性状态空间来处理序列。这种方法解决了 Transformer 在处理长序列时的计算效率问题。Mamba 的设计实现了更快的推理速度,并且随着序列长度的线性缩放,为序列建模树立了一个新的范式,特别适用于处理日益增长的序列。
二.Mamba 独特之处
Mamba 最独特的地方在于它脱离了传统的注意力和 MLP(多层感知器)模块。这种简化使得模型更轻便、更快速,并且能随着序列长度线性地缩放,这是之前模型无法做到的。
Mamba 的关键特性包括:
选择性 SSM:通过选择性 SSM,Mamba 能够过滤掉不相关信息,专注于重要数据,从而更高效地处理序列。
硬件意识算法:Mamba 采用了针对现代硬件(尤其是 GPU)优化的并行算法,这提高了计算速度,相比传统模型减少了内存需求。
简化架构:Mamba 通过整合选择性 SSM 并去除注意力和 MLP 模块,提供了一个更简单、更统一的结构,从而带来更好的可扩展性和性能。
在语言、音频和基因组学等多个领域,Mamba 展示了优越的性能,无论是在预训练还是特定领域任务中都有出色表现。例如,在语言建模方面,Mamba 的性能可媲美或超越更大的 Transformer 模型。
Mamba 的代码和预训练模型可以在 GitHub 上公开获取,供社区使用。
GitHub:https://github.com/state-spaces/mamba
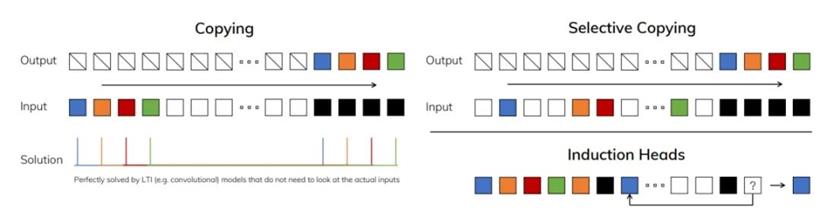
对于线性模型来说,标准复制任务很简单。选择性复印和感应头需要用于 LLM 的动态、内容感知存储器。
结构化状态空间(Structured State Space,S4)模型最近成为了序列模型领域的一种有前景的新类别,它融合了循环神经网络(RNN)、卷积神经网络(CNN)和传统状态空间模型的特性。S4 模型借鉴了连续系统的思想,特别是那些将一维函数或序列通过隐含状态进行映射的系统。在深度学习领域,S4 模型代表了一项重大创新,为设计高效且适应性强的序列模型提供了全新的方法。
S4 模型的动态
基本的结构化状态空间模型(S4)接受一个序列 x,并通过学习到的参数 A、B、C 以及一个延迟参数 Δ 来生成输出 y。这个转换过程包括对这些参数进行离散化(即将连续的函数转换成离散的函数)并应用 SSM 操作,这个操作是时间不变的,也就是说在不同的时间步长上是不会改变的。
离散化的重要性
离散化是一个关键过程,它通过一些固定的公式将连续的参数转换成离散的形式,使得 S4 模型能够保持与连续时间系统的联系。这赋予了模型一些额外的特性,如分辨率不变性,并确保了适当的规范化,从而增强了模型的稳定性和性能。离散化的过程也类似于 RNN 中用于管理信息流的门控机制。
线性时间不变性(LTI)
S4 模型的核心特性之一是它们的线性时间不变性。这意味着模型的动态在时间上保持一致,其参数在所有时间步长上都是固定的。LTI 是递归和卷积的基础,为构建序列模型提供了一个简单但强大的框架。
克服基本限制
传统上,S4 框架由于其线性时间不变的本质而受到限制,在需要适应性动态的数据建模方面面临挑战。最近的研究论文提出了一种方法,通过引入时变参数来克服这些限制,从而摆脱了 LTI 的束缚。这使得 S4 模型能够处理更多样化的序列和任务,显著扩大了其适用范围。
“状态空间模型” 这一术语广泛用于描述涉及潜在状态的任何递归过程,在多个学科中有不同的含义。在深度学习的背景下,S4 模型或结构化 SSM 指的是一类专门为高效计算而优化的模型,同时它们也能够处理复杂的序列。
S4 模型可以被集成到端到端的神经网络架构中,作为独立的序列转换组件。它们在某种程度上类似于 CNN 中的卷积层,为各种神经网络架构中的序列建模提供了基础支撑。
 三.序列建模中选择性的重要性
三.序列建模中选择性的重要性
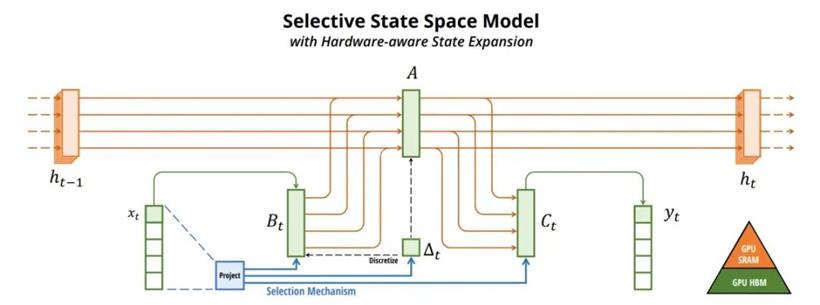
这篇论文指出,序列建模的一个关键方面是将上下文信息压缩成可管理的状态。能够选择性关注或过滤输入的模型,更有效地维护这种压缩状态,从而实现更高效、强大的序列模型。这种选择性对于模型在处理复杂的语言建模等任务时,适应性地控制信息沿序列的流动至关重要。
Selective SSM 提升了传统 SSM 的能力,使其参数可以依赖于输入,引入了一种以前时间不变模型无法实现的适应性。这导致了时变 SSM 的出现,它们不再使用卷积进行高效计算,而是依赖线性递归机制,这与传统模型有显著不同。
SSM + Selection (S6) 这种变体包含一个选择机制,使参数 B 和 C 以及延迟参数 Δ 依赖于输入。这使得模型能够选择性地关注输入序列 x 的特定部分。参数在考虑选择的情况下被离散化,并使用扫描操作以时变方式应用 SSM,顺序处理元素,并随时间动态调整关注点。
四.Mamba 性能亮点

就性能而言,Mamba 在推理速度和准确性方面表现出色。它的设计使得模型更好地利用更长的上下文,这在 DNA 和音频建模中得到了证明,超越了以前的模型在处理需要长期依赖的复杂任务上的表现。它还在跨多个任务的零样本评估中表现出多功能性,为此类模型在效率和可扩展性方面设定了新标准。
五.开始使用 Mamba
对于那些有意使用 Mamba 的用户,需要的技术条件包括 Linux 操作系统、NVIDIA GPU、PyTorch 1.12+ 和 CUDA 11.6+。安装过程包括使用 pip 命令从 Mamba 仓库安装所需的包。如果出现与 PyTorch 版本的兼容性问题,可以使用 pip 的 –no-build-isolation 选项来解决。这些模型经过了大型数据集如 Pile 和 SlimPajama 的训练,旨在满足多样化的计算需求和性能标准。
GitHub:https://github.com/state-spaces/mamba
Mamba 提供了从选择性 SSM 层到 Mamba 块再到完整语言模型结构的不同级别的接口。Mamba 块作为该架构的主要模块,利用了因果 Conv1d 层,并可轻松集成到神经网络设计中。提供的 Python 示例展示了如何实例化一个 Mamba 模型并通过它处理数据,突出了系统的简单性和灵活性。
在 Hugging Face 上,有多种规模的预训练 Mamba 模型可用,参数范围从 130M 到 2.8B,这些模型在 Pile 和 SlimPajama 数据集上接受了训练。这些模型旨在满足多样化的计算和性能需求,遵循 GPT-3 的规模标准。用户可以期望从这些模型中获得高吞吐量和准确性,使 Mamba 成为多种应用的强有力选择,包括但不限于语言建模。
Hugging Face:https://huggingface.co/papers/2312.00752
六.Mamba 的影响
Mamba 代表了序列建模领域的一次飞跃,为处理信息密集型数据提供了一种强大的替代 Transformer 架构的方案。其设计符合现代硬件的需求,优化了内存使用和并行处理能力。Mamba 的代码库和预训练模型的开源可用性使其成为 AI 和深度学习领域研究人员和开发人员的一个易于接入且强大的工具。
原文链接:https://www.unite.ai/mamba-redefining-sequence-modeling-and-outforming-transformers-architecture/


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






