最近几天,据说全世界的风投机构开会都在大谈 Sora。自去年初 ChatGPT 引发全科技领域军备竞赛之后,已经没有人愿意在新的 AI 生成视频赛道上落后了。在这个问题上,人们早有预判,但也始料未及:AI 生成视频,是继文本生成、图像生成以后技术持续发展的方向,此前也有不少科技公司抢跑推出自己的视频生成技术。
不过当 OpenAI 出手发布 Sora 之后,我们却立即有了「发现新世界」的感觉 —— 效果和之前的技术相比高出了几个档次。
在 Sora 及其技术报告推出后,我们看到了长达 60 秒,高清晰度且画面可控、能多角度切换的高水平效果。在背后的技术上,研究人员训练了一个基于 Diffusion Transformer(DiT)思路的新模型,其中的 Transformer 架构利用对视频和图像潜在代码的时空 patch 进行操作。
正如华为诺亚方舟实验室首席科学家刘群博士所言,Sora 展现了生成式模型的潜力(特别是多模态生成方面)显然还很大。加入预测模块是正确的方向。至于未来发展,还有很多需要我们探索,现在还没有像 Transformer 之于 NLP 领域那样的统一方法。想要探求未来的路怎么走,我们或许可以先思考一下之前的路是怎么走过的。那么,Sora 是如何被 OpenAI 发掘出来的?
从 OpenAI 的技术报告末尾可知,相比去年 GPT-4 长篇幅的作者名单,Sora 的作者团队更简洁一些,需要点明的仅有 13 位成员:
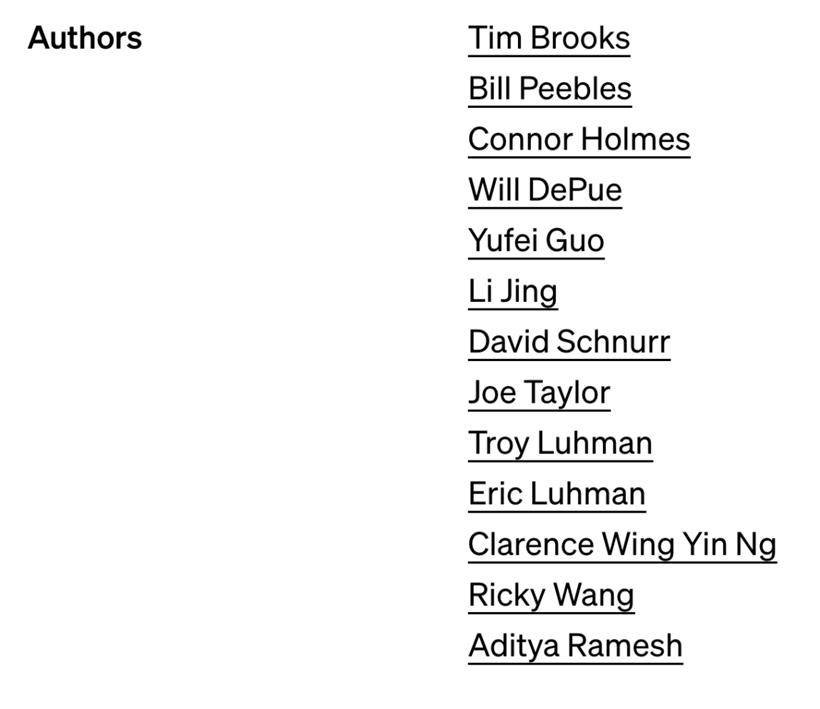
这些参与者中,已知的核心成员包括研发负责人 Tim Brooks、William Peebles、系统负责人 Connor Holmes 等。这些成员的信息也成为了众人关注的焦点。比如,Sora 的共同领导者 Tim Brooks,博士毕业于 UC Berkeley 的「伯克利人工智能研究所」BAIR,导师为 Alyosha Efros。

在博士就读期间,他曾提出了 InstructPix2Pix,他还曾在谷歌从事为 Pixel 手机摄像头提供 AI 算法的工作,并在英伟达研究过视频生成模型。
另一位共同领导者 William (Bill) Peebles 也来自于 UC Berkeley,他在 2023 年刚刚获得博士学位,同样也是 Alyosha Efros 的学生。在本科时,Peebles 就读于麻省理工,师从 Antonio Torralba。

值得注意的是,Peebles 等人的一篇论文被认为是这次 Sora 背后的重要技术基础之一。
论文《Scalable diffusion models with transformers》,一看名字就和 Sora 的理念很有关联,该论文入选了计算机视觉顶会 ICCV 2023。

论文链接:https://arxiv.org/abs/2212.09748
不过,这项研究在发表的过程还遇到了一些坎坷。上周五 Sora 发布时,图灵奖获得者、Meta 首席科学家 Yann LeCun 第一时间发推表示:该研究是我的同事谢赛宁和前学生 William Peebles 的贡献,不过因为「缺乏创新」,先被 CVPR 2023 拒绝,后来被 ICCV 2023 接收。
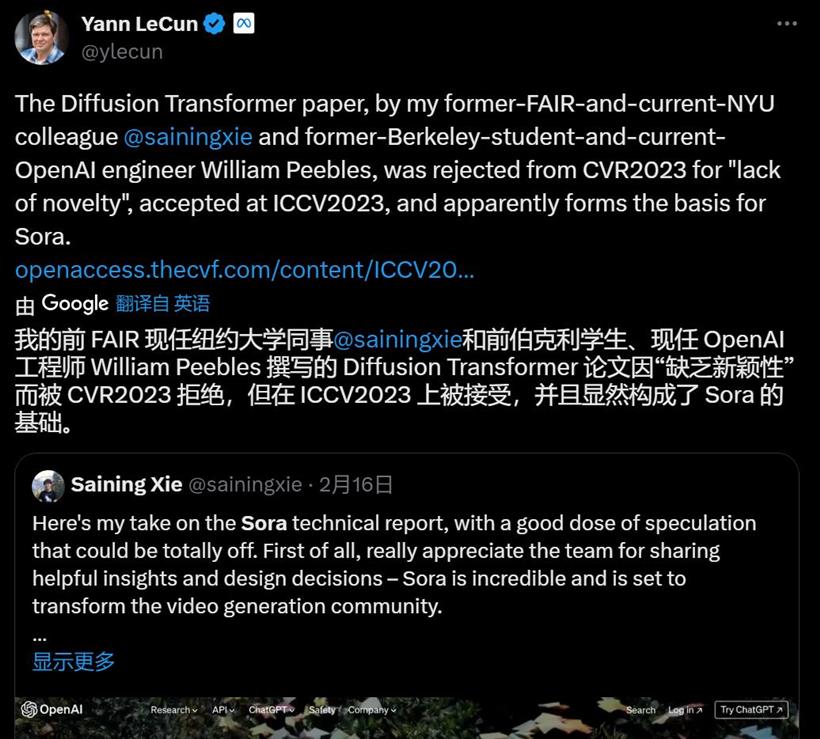
具体来说,这篇论文提出了一种基于 transformer 架构的新型扩散模型即 DiT。在该研究中,研究者训练了潜在扩散模型,用对潜在 patch 进行操作的 Transformer 替换常用的 U-Net 主干网络。他们通过以 Gflops 衡量的前向传递复杂度来分析扩散 Transformer (DiT) 的可扩展性。
研究者发现,通过增加 Transformer 深度 / 宽度或增加输入 token 数量,具有较高 Gflops 的 DiT 始终具有较低的 FID。除了良好的可扩展性之外,DiT-XL/2 模型在 class-conditional ImageNet 512×512 和 256×256 基准上的性能优于所有先前的扩散模型,在后者上实现了 2.27 的 FID SOTA 数据。
目前这篇论文的引用量仅有 191。同时可以看到,William (Bill) Peebles 所有研究中引用量最高的是一篇名为《GAN 无法生成什么》的论文:
当然,论文的作者之一,前 FAIR 研究科学家、现纽约大学助理教授谢赛宁否认了自己与 Sora 的直接关系。毕竟 Meta 与 OpenAI 互为竞争对手。
Sora 成功的背后,还有哪些重要技术?
除此之外,Sora 的成功,还有一系列近期业界、学界的计算机视觉、自然语言处理的技术进展作为支撑。简单浏览一遍参考文献清单,我们发现,这些研究出自谷歌、Meta、微软、斯坦福、MIT、UC 伯克利、Runway 等多个机构,其中不乏华人学者的成果。
归根结底,Sora 今天的成就源自于整个 AI 社区多年来的求索。
从 32 篇参考文献中,我们选择了几篇展开介绍:
Ha, David, and Jürgen Schmidhuber. "World models." arXiv preprint arXiv:1803.10122 (2018).

论文标题:World Models
作者:David Ha、Jurgen Schmidhuber
机构:谷歌大脑、NNAISENSE(Schmidhuber 创立的公司)、Swiss AI Lab
论文链接:https://arxiv.org/pdf/1803.10122.pdf
这是一篇六年前的论文,探索的主题是为强化学习环境建立生成神经网络模型。世界模型可以在无监督的情况下快速训练,以学习环境的压缩空间和时间表示。通过使用从世界模型中提取的特征作为代理的输入,研究者发现能够训练出非常紧凑和简单的策略,从而解决所需的任务,甚至可以完全在由世界模型生成的幻梦中训练代理,并将该策略移植回实际环境中。
机器之心报道:《模拟世界的模型:谷歌大脑与 Jürgen Schmidhuber 提出「人工智能梦境」》
Yan, Wilson, et al. "Videogpt: Video generation using vq-vae and transformers." arXiv preprint arXiv:2104.10157 (2021).

论文标题:VideoGPT: Video Generation using VQ-VAE and Transformers
作者:Wilson Yan、Yunzhi Zhang、Pieter Abbeel、Aravind Srinivas
机构:UC 伯克利
论文链接:https://arxiv.org/pdf/2104.10157.pdf
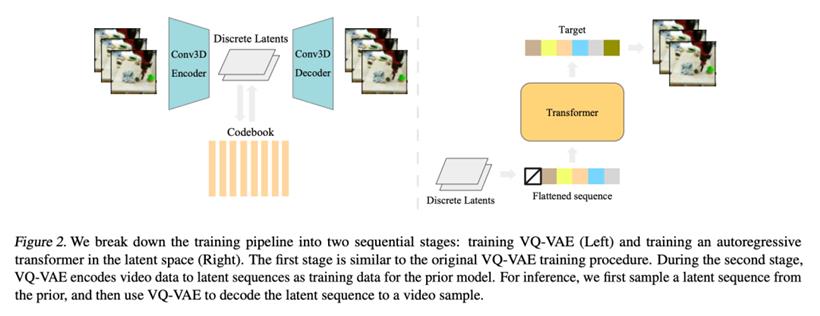
这篇论文提出的 VideoGPT 可用于扩展基于似然的生成对自然视频进行建模。Video-GPT 将通常用于图像生成的 VQ-VAE 和 Transformer 模型以最小的修改改编到视频生成领域,研究者利用 VQVAE 通过采用 3D 卷积和轴向自注意力学习降采样的原始视频离散潜在表示,然后使用简单的类似 GPT 的架构进行自回归,使用时空建模离散潜在位置编码。VideoGPT 结构下图:
Wu, Chenfei, et al. "Nüwa: Visual synthesis pre-training for neural visual world creation." European conference on computer vision. Cham: Springer Nature Switzerland, 2022.

论文标题:NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion
作者:Chenfei Wu、Jian Liang、Lei Ji、Fan Yang、Yuejian Fang、Daxin Jiang、Nan Duan
机构:微软亚洲研究院、北京大学
论文链接:https://arxiv.org/pdf/2111.12417.pdf
相比于此前只能分别处理图像和视频、专注于生成其中一种的多模态模型,NÜWA 是一个统一的多模态预训练模型,在 8 种包含图像和视频处理的下游视觉任务上具有出色的合成效果。
为了同时覆盖语言、图像和视频的不同场景,NÜWA 采用了 3D Transformer 编码器 - 解码器框架,它不仅可以处理作为三维数据的视频,还可以分别用于处理一维和二维数据的文本和图像。
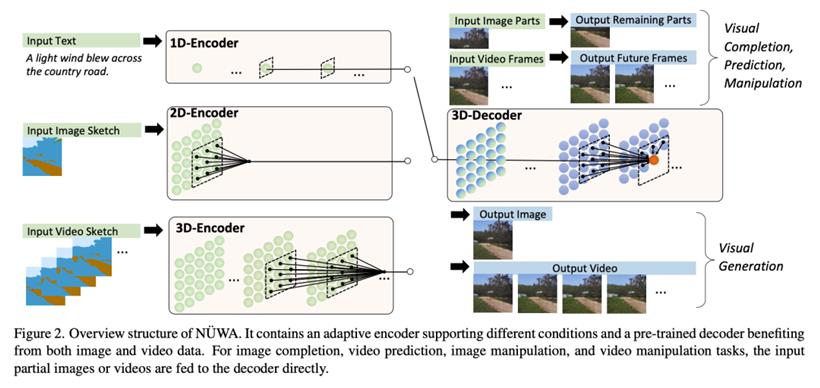
该框架还包含一种 3D Nearby Attention (3DNA) 机制,以考虑空间和时间上的局部特征。3DNA 不仅降低了计算复杂度,还提高了生成结果的视觉质量。与几个强大的基线相比,NÜWA 在文本到图像生成、文本到视频生成、视频预测等方面都得到了 SOTA 结果,还显示出惊人的零样本学习能力。
He, Kaiming, et al. "Masked autoencoders are scalable vision learners." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.

论文标题:Masked autoencoders are scalable vision learners
作者:Kaiming He、Xinlei Chen、Saining Xie、Yanghao Li、Piotr Dollar、Ross Girshick
机构:Meta
论文链接:https://arxiv.org/abs/2111.06377
这篇论文展示了一种被称为掩蔽自编码器(masked autoencoders,MAE)的新方法,可以用作计算机视觉的可扩展自监督学习器。MAE 的方法很简单:掩蔽输入图像的随机区块并重建丢失的像素。它基于两个核心理念:研究人员开发了一个非对称编码器 - 解码器架构,其中一个编码器只对可见的 patch 子集进行操作(没有掩蔽 token),另一个简单解码器可以从潜在表征和掩蔽 token 重建原始图像。研究人员进一步发现,掩蔽大部分输入图像(例如 75%)会产生重要且有意义的自监督任务。结合这两种设计,就能高效地训练大型模型:提升训练速度至 3 倍或更多,并提高准确性。
用 MAE 做 pre-training 只需 ImageNet-1k 就能达到超过 87% 的 top 1 准确度,超过了所有在 ImageNet-21k pre-training 的 ViT 变体模型。从方法上,MAE 选择直接重建原图的元素,而且证明了其可行性,改变了人们的认知,又几乎可以覆盖 CV 里所有的识别类任务,开启了一个新的方向。
具有良好扩展性的简单算法是深度学习的核心。在 NLP 中,简单的自监督学习方法(如 BERT)可以从指数级增大的模型中获益。在计算机视觉中,尽管自监督学习取得了进展,但实际的预训练范式仍是监督学习。在 MAE 研究中,研究人员在 ImageNet 和迁移学习中观察到自编码器 —— 一种类似于 NLP 技术的简单自监督方法 —— 提供了可扩展的前景。视觉中的自监督学习可能会因此走上与 NLP 类似的轨迹。
Rombach, Robin, et al. "High-resolution image synthesis with latent diffusion models." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022

论文标题:High-resolution image synthesis with latent diffusion models
作者:Robin Rombach、Andreas Blattmann、Dominik Lorenz、Patrick Esser、Bjorn Ommer
机构:慕尼黑大学、Runway
论文链接:https://arxiv.org/pdf/2112.10752.pdf
基于这篇论文的成果,Stable Diffusion 正式面世,开启了在消费级 GPU 上运行文本转图像模型的时代。
该研究试图利用扩散模型实现文字转图像。尽管扩散模型允许通过对相应的损失项进行欠采样(undersampling)来忽略感知上不相关的细节,但它们仍然需要在像素空间中进行昂贵的函数评估,这会导致对计算时间和能源资源的巨大需求。该研究通过将压缩与生成学习阶段显式分离来规避这个问题,最终降低了训练扩散模型对高分辨率图像合成的计算需求。
Gupta, Agrim, et al. "Photorealistic video generation with diffusion models." arXiv preprint arXiv:2312.06662 (2023).

论文标题:Photorealistic Video Generation with Diffusion Models
作者:李飞飞等
机构:斯坦福大学、谷歌研究院、佐治亚理工学院
论文链接:https://arxiv.org/pdf/2312.06662.pdf
在 Sora 之前,一项视频生成研究收获了大量赞誉:Window Attention Latent Transformer,即窗口注意力隐 Transformer,简称 W.A.L.T。该方法成功地将 Transformer 架构整合到了隐视频扩散模型中,斯坦福大学的李飞飞教授也是该论文的作者之一。值得注意的是,尽管概念上很简单,但这项研究首次在公共基准上通过实验证明 Transformer 在隐视频扩散中具有卓越的生成质量和参数效率。
这也是 Sora 32 个公开参考文献中,距离此次发布最近的一项成果。
最后,Meta 研究科学家田渊栋昨天指出, Sora 不直接通过下一帧预测生成视频的方法值得关注。更多的技术细节,或许还等待 AI 社区的研究者及从业者共同探索、揭秘。

在这一方面 Meta 也有很多已公开的研究。不得不说 Sora 推出后,我们虽然没有 OpenAI 的算力,但还有很多事可以做。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






