

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号


今天出场的是 DeepGEMM,是一个专为干净、高效的 FP8 通用矩阵乘法 (GEMM) 而设计的库,具有细粒度缩放功能。如 DeepSeek-V3 中所述,它支持普通和混合专家 (MoE) 分组 GEMM。该库用 CUDA 编写,在安装过程中无需编译,而是使用轻量级即时 (JIT) 模块在运行时编译所有内核。没有说 DeepSeek 不厉害的意思,但这三天的开源都能看出,即便背靠幻方,他们始终不像大厂那样资源雄厚,必须在压榨计算资源方面狠下功夫。
4.更简洁的设计:核心代码少,避免复杂依赖,便于学习和优化
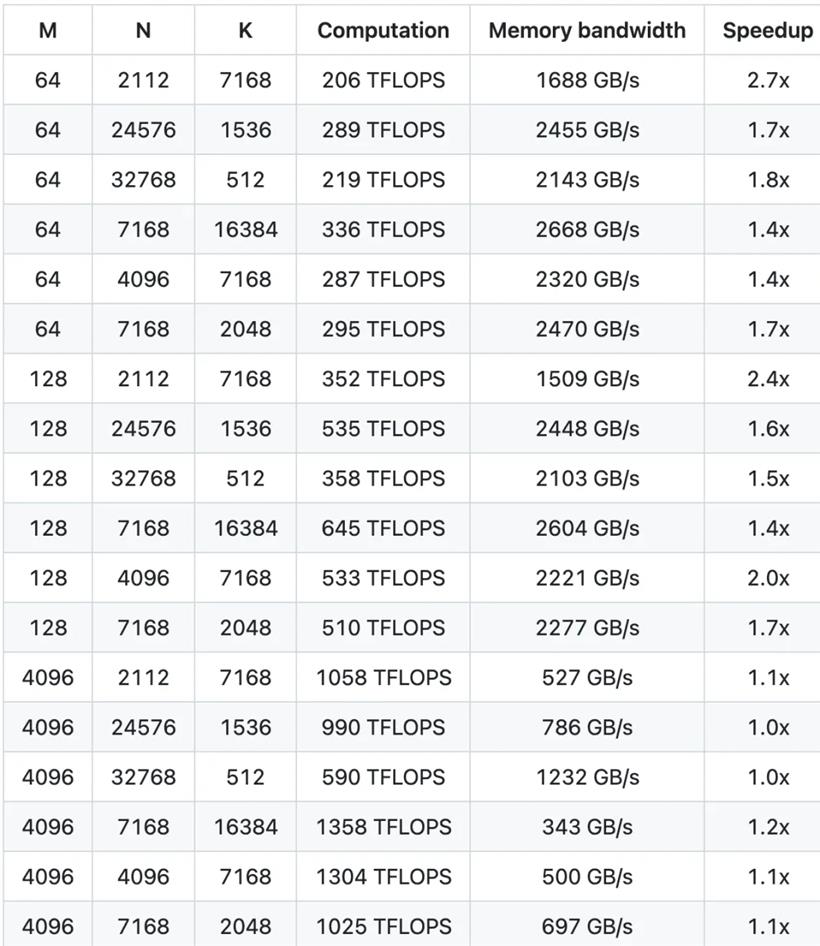
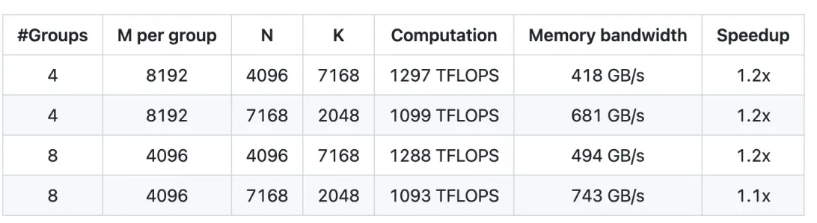
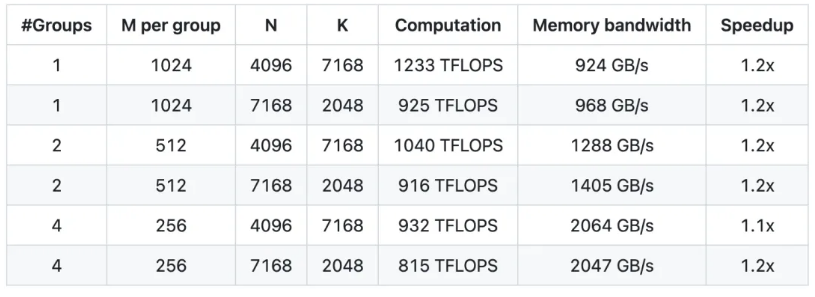
这些特性使其在现代 AI 计算中脱颖而出,尤其是在需要高效推理和低功耗的场景下。更高的效率和更灵活的部署,是 DeepGEMM 的亮点,核心逻辑仅约 300 行代码,却在大多数矩阵尺寸上超越了专家级别调优的内核。Hopper GPUs 上最高可达 1350+ FP8 TFLOPS。FP8 是一种压缩数字的方法,相当于把原本需要 32 位或 16 位存储的数字,精简成 8 位存储。就像你用更小的便利贴记笔记,虽然每张纸能写的内容少了,但携带和传递更快。
这种压缩计算的好处是内存占用减少——同样大小的任务,需要的「便利贴」更少,搬运小纸片比大文件快,因此计算速度也更快。但挑战是很容易出错。为了解决 FP8 精度问题,DeepGEMM 用了巧妙的「两步法」:用 FP8 进行大批量乘法,像用计算器快速按出一串结果。这个步骤里,误差在所难免。但没关系,还有第二步:高精度汇总。每隔一段时间,就把这些结果转成更精确的 32 位数累加,像用草稿纸仔细核对总和,避免误差积累。
先跑,再通过两级累积防错。通过这种设计,DeepGEMM 让 AI 模型在手机、电脑等设备上运行得更流畅,同时减少耗电,适合未来更复杂的应用场景。包括对 JIT 编译的应用,也是类似的思路。JIT 编译,全称是「Just-In-Time」编译,中文可以叫即时编译,相对应的概念是静态编译。一般的程序在你用之前就得全部写好、编译好,变成电脑能懂的语言,但 JIT 编译不一样,它是程序运行的时候才把代码变成电脑能执行的指令。
DeepGEMM 支持普通 GEMM 和混合专家(MoE)分组 GEMM,这些任务的计算需求各不相同。JIT 编译能根据任务特点,临时调整代码,直接调动张量核心的FP8计算或变换引擎功能,减少浪费,提高速度。怎么形容这样一种技术路线呢:纤巧、轻量、锋利。对于广大开发者来说,DeepGEMM 可以说是又一个福音。以下是部署相关的信息,大家不妨玩起来。
DeepGEMM 是一个专为 FP8 通用矩阵乘法(GEMM)优化的库,具备精细的缩放机制,并在 DeepSeek-V3 中提出。它支持标准 GEMM 和混合专家(MoE)分组 GEMM。该库采用 CUDA 编写,无需在安装时进行预编译,而是通过轻量级的即时编译(JIT)模块在运行时编译所有核心函数。目前,DeepGEMM 仅支持 NVIDIA Hopper 张量核心。针对 FP8 张量核心计算精度不足的问题,它采用 CUDA 核心的两级累积(提升)技术进行优化。
尽管借鉴了一些 CUTLASS 和 CuTe 的概念,DeepGEMM 并未过度依赖它们的模板或数学运算,而是以简洁为目标,仅包含一个核心计算核函数,代码量约 300 行。这使得 DeepGEMM 成为学习 Hopper FP8 矩阵乘法与优化技术的清晰且易于理解的参考资源。尽管设计简洁,DeepGEMM 在各种矩阵形状下的性能可与专业优化的库媲美,甚至在某些情况下表现更优。
# 堆代码 duidaima.com # Submodule must be cloned git clone --recursive git@github.com:deepseek-ai/DeepGEMM.git # Make symbolic links for third-party (CUTLASS and CuTe) include directories python setup.py develop # Test JIT compilation python tests/test_jit.py # Test all GEMM implements (normal, contiguous-grouped and masked-grouped) python tests/test_core.py安装
python setup.py install然后,在你的 Python 项目中导入 deep_gemm,尽情使用吧!





