- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

给吃瓜的朋友先科普一下,SWE-bench Verified 是什么?简单说,这是个专门测试 AI 写代码能力的考卷,里面有 500 道实战题。每道题都来自 GitHub 上的真实 bug,主要是 Python 项目——Django、matplotlib、scikit-learn 等。AI 要像真正的开发者一样提交 Pull Request 来修复 bug,还得通过所有测试用例。
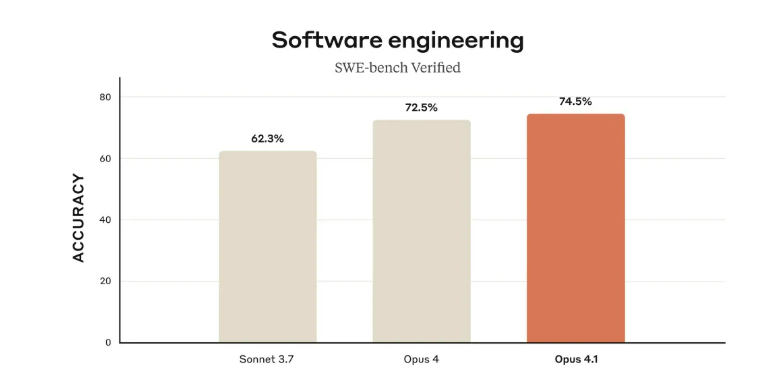
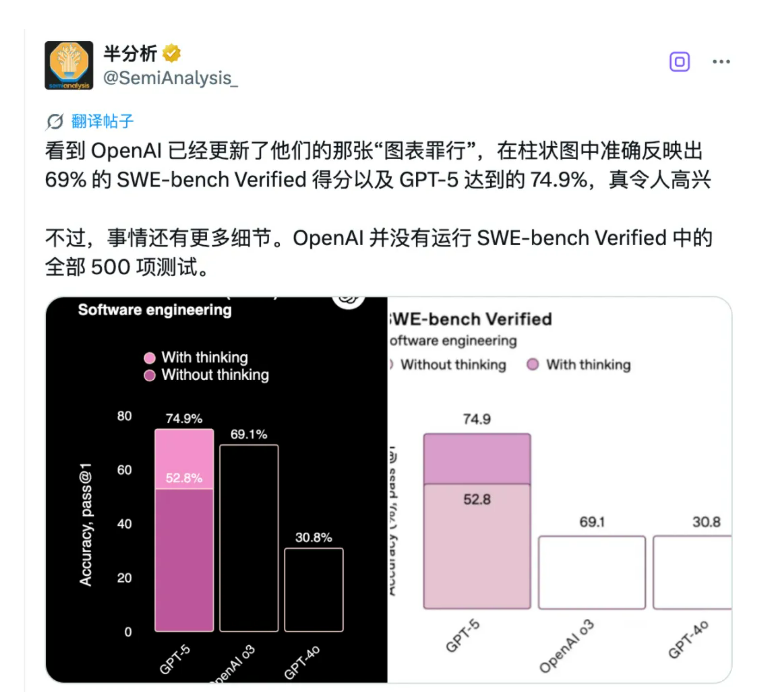
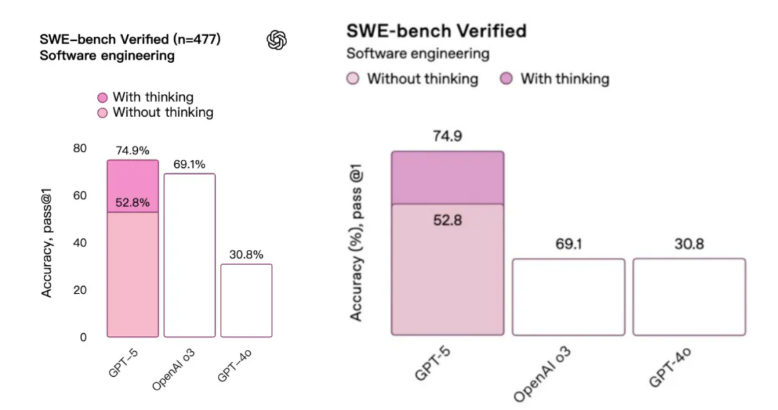
于是,SemiAnalysis 直接开始算账:500 道题考 74.9%,大概答对了 374.5 道。但 OpenAI 在标注里白纸黑字写着——他们只跑了 477 道题。那 23 道哪儿去了?OpenAI 的解释是:「这些题在我们现有的基础设施上无法运行。」有意思的是,OpenAI 很敞亮,至少说了是 477 道题。但又不是很敞亮——别家都是 500 道题的标准套餐,你少做 23 道,还把分数挂在最显眼的地方比较,这就有点微妙了。而这已经不是 OpenAI 第一次这么干了。
今年 4 月发布 GPT-4.1 时,OpenAI 就承认过这事儿。他们还做了个「保守估算」:如果把那 23 道没做的题都算 0 分,GPT-4.1 的成绩会从 54.6% 跌到 52.1%。那问题来了,这 23 道题到底是题目本身有问题,还是技术上确实搞不定?更关键的是,这些题难不难?如果恰好都是难度较高或者能拉低整体表现的题目,那 GPT-5 和 Claude Opus 4.1 的对比就没那么公平了。值得一提的是,SWE-bench Verified 这个测试集本身是由 OpenAI 在 2024 年推出。OpenAI 说,原始的 SWE-bench 数据集里有些题实在太难,几乎无法解决,会让 AI 的真实能力被低估。
3 分:没有额外信息基本做不了

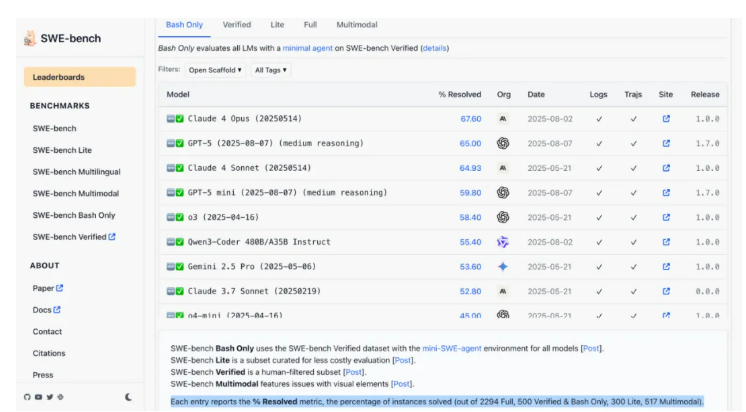
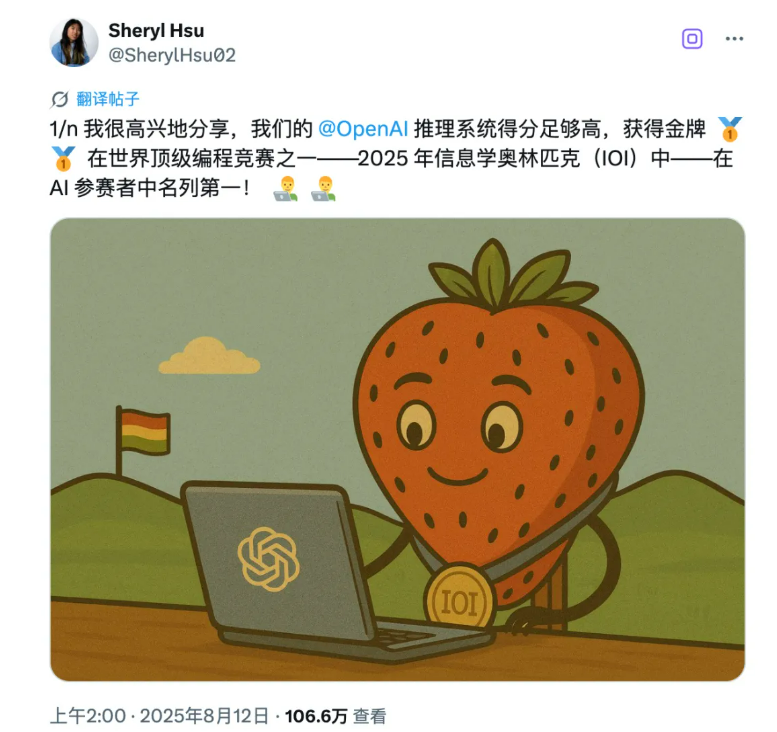
而在这个榜单上,5 月 14 日版本的 Claude 4 Opus 反而领先于 GPT-5。说到「内部版本」和「公开版本」的差距,今天 OpenAI 又秀了一把肌肉。他们的内部推理模型在 IOI 2025(国际信息学奥林匹克竞赛)上拿到 AI 组第一、人类总排名第 6。并且,这个模型跟上次拿 IMO 金牌的是同一个版本,没有专门针对 IOI 做额外训练。