Go泛型也出来很久了,最近也用泛型去实现一些功能,例如数据结构一些应用还是没有什么问题的。但是如果做一些类型上限制,还是有点问题,和其他语言有一些不一样的地方,想要基于泛型做一些类型上的限制,必须使用组合的模式,或者嵌套。这篇我将记录一下我在Go泛型上遇到一些问题。
阅读这篇文章读者需要了解Go泛型怎么使用和泛型能做什么,还有了解map结构原理,并且本文会以LinkedHashMap作为一个泛型结构讲解一些关于Go泛型不完美的地方。读者要知道LinkedHashMap底层是怎么工作的才能读懂这篇文章。
原生Map局限性
大家都知道Go的内置map结构在遍历的时候是无序的,如果要让其有序输出那么就要对key进行排序,然后收集排序完的key依次索引输出这样子,但是很麻烦的样子,并且还不能保证map存储的的顺序不是以插入值的顺序而存储,并且还不能按照访问操作顺序重排底层存储结构元素的关系,了解的原生map应该知道底层是通过hash function打乱并且存储在不同桶里,遍历只能从不同的桶里随机输出这些元素,这就是无序的原因。
LinkedHashMap
使用过Java朋友应该知道一个数据结构叫LinkedHashMap,这个数据结构是可以保证数据存储顺序的,并且还能按照配置动态调整存储的元素的顺序关系,下面这是一段Java代码,介绍一下工作原理:
// 堆代码 duidaima.com
LinkedHashMap<String, Integer> lmap = new LinkedHashMap<String, Integer>();
lmap.put("语文", 1);
lmap.put("数学", 2);
lmap.put("英语", 3);
lmap.put("历史", 4);
lmap.put("政治", 5);
lmap.put("地理", 6);
lmap.put("生物", 7);
lmap.put("化学", 8);
for(Entry<String, Integer> entry : lmap.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
输出结果可以看到:
语文: 1
数学: 2
英语: 3
历史: 4
政治: 5
地理: 6
生物: 7
化学: 8
可以看到是以我们插入时候的顺序输出的结果,可以做到有序的。这是怎么做到的呢?如果深入底层源代码分析发现,他内部结构入下图:
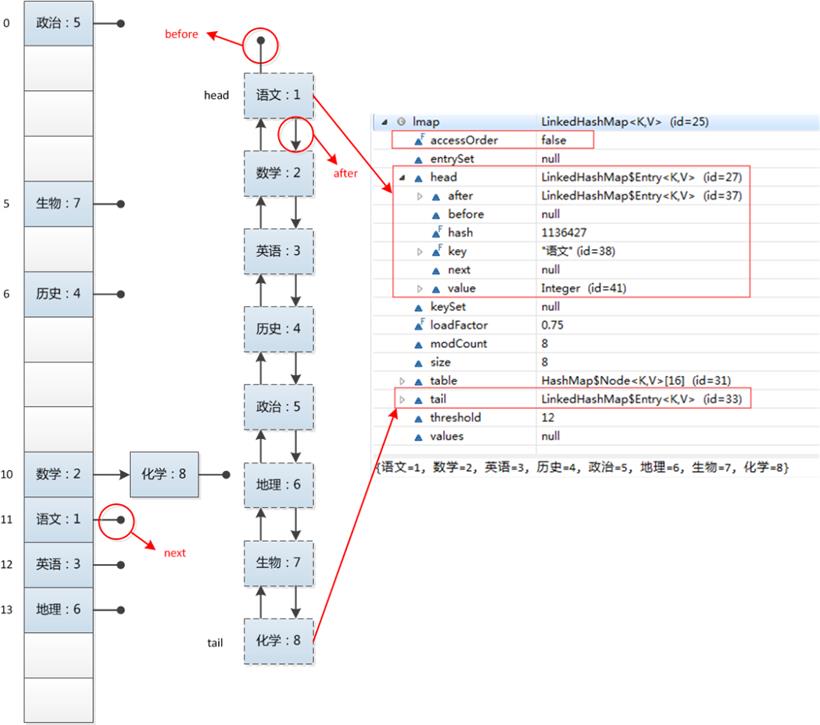
和HashMap的运行结果不同,LinkedHashMap的迭代输出的结果保持了插入顺序,它底层其实就是一个map加Linked List组成一个结构,map负责索引,而Linked List负责的是数据顺序组织存储方式,可以形成一个完全有序的链表,大部分可能认为就是一个链式存储方式,这是不对的,有兴趣可以源代码,是两种数据结构组合而成,类似于LRU淘汰算法那样,每次操作元素都会发生底层数据交换位置。
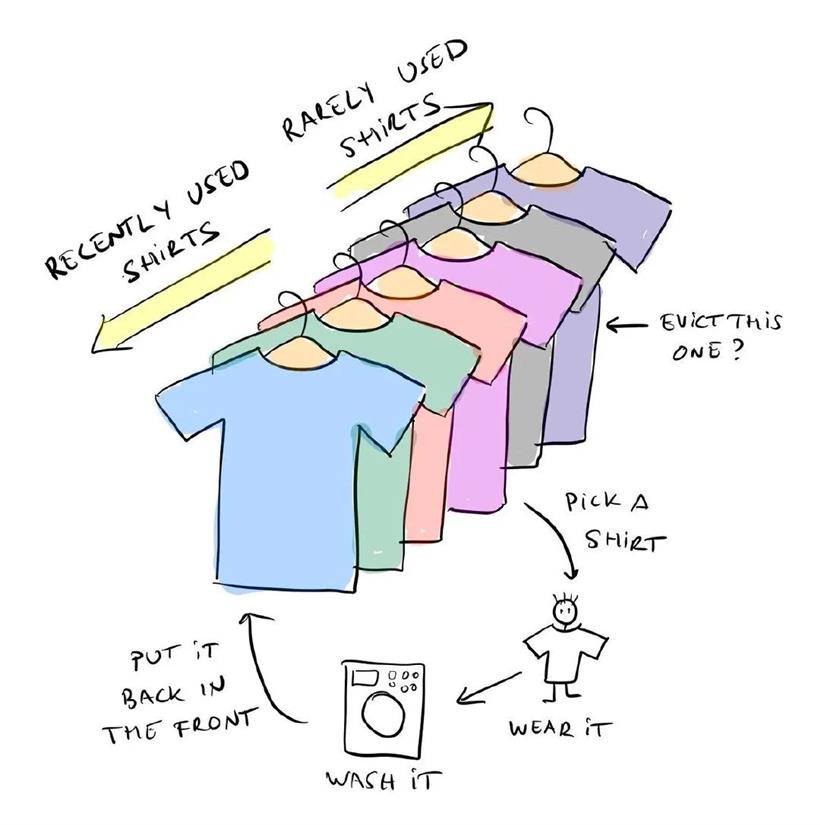
元素是被内置的map索引着的只是为了方便快速拿取,而为了数据能和插入时一致的顺序又用链表组织成了有序链表,原理可以想象上面这幅图,你洗衣服拿衣服怎么洗的?如果读者看到这里看不懂话,可以去网上看看关于LinkedHashMap底层实现的代码分析文章吧,我这里不讲解了。
用Go泛型实现
对其工作原理介绍完了,下面我就针对这个这种方式,使用Go去实现类似的,算是重复造轮子吧。但是在泛型key上还是遇到一些问题,顺便写一个文章记录。下面这是我使用Go复刻的LinkedHashMap代码,Node[K Hashed, V any]结构是为了底层数据存储所设计的,而LinkedHashMap为主体结构,注意里面的table map[uint64]*Node[K, V]字段。
type Node[K Hashed, V any] struct {
Prev, Next *Node[K, V]
Key K
Value V
}
// Stored structure
type LinkedHashMap[K Hashed, V any] struct {
accessOrder bool // the iteration ordering method
capacity int // total capacity
head, tail *Node[K, V] // linked list
table map[uint64]*Node[K, V] // data storeage
size int // current size
}
为了这个map能达到和Java的LinkedHashMap一样的效果,我在key泛型上做了限制,因为要支持双泛型参数声明,所以有两个泛型参数,如果简单一个话,这个键完全可以设置为string类型,那这样的后果就调用方只能使用string类型做为键了,而value可以泛型,那么就会失去双参数泛型的意义。
type Hashed interface {
comparable
string
HashCode() uint64
}
为了支持更多类型作为key这里我定义了一个Hashed接口作为泛型约束,可以看到comparable和string还有HashCode() uint64,comparable为了默认一些基础的数据类型例如int和float能作为键,而string大家了解他底层实现的话其实是一个包装的类型,真实的数据是[]byte类型,如果以现在的方式去使用string作为键,那么我还要针对string去做哈希才能得到最终哈希值。
在看一下具体的crud代码:
func NewLinkedHashMap[K Hashed, V any](capacity int, accessOrder bool) LinkedHashMap[K, V] {
return LinkedHashMap[K, V]{
accessOrder: accessOrder,
capacity: capacity,
table: make(map[uint64]*Node[K, V], capacity),
}
}
func (hashmap *LinkedHashMap[K, V]) Put(key K, value V) bool {
node := &Node[K, V]{
Key: key,
Value: value,
}
if hashmap.size == 0 {
hashmap.head = node
hashmap.tail = node
return true
}
if node, ok := hashmap.table[sum64]; ok {
node.Value = value
moveNode(node)
node.Next = nil
addNodeAtTail(hashmap, node)
hashmap.size += 1
return true
}
addNodeAtTail(hashmap, node)
hashmap.table[sum64] = node
hashmap.size += 1
return true
}
func (hashmap *LinkedHashMap[K, V]) Remove(key K) {
}
func (hashmap *LinkedHashMap[K, V]) Get(key K) *V {
return nil
}
func (hashmap *LinkedHashMap[K, V]) Size() int {
return hashmap.size
}
// 从两个节点中间删除节点
func moveNode[K Hashed, V any](node *Node[K, V]) {
node.Next.Prev = node.Prev
node.Prev.Next = node.Next
}
// addTail 添加节点到链表尾巴
func addNodeAtTail[K Hashed, V any](hashmap *LinkedHashMap[K, V], node *Node[K, V]) {
node.Prev = hashmap.tail
hashmap.tail.Next = node
hashmap.tail = node
}
问题来了,看函数签名为(hashmap *LinkedHashMap[K, V]) Put(key K, value V)的函数,问题在这,key我在设计的时候就限制为了Hashed类型,而如果这个key在使用的时候传入的是结构体类型,结构体实现了HashCode() uint64 那么就做成key,但是问题来了,如果是默认字符串,go内置的类型没有实现HashCode()uint64,那么我这里就要断言了,看看是不是string 然后函数内置去计算哈希?有木有什么办法不这样搞?
解决方法好几种:
.所以最后还是回归到类型断言,我其实想有木有其他好办法解决?
.还有一种方法就是我在我自己包里面 自定义一个装个一个string类型代替 默认内置的string类型 去实现HashCode()uint64 接口,这样就可以正确使用了,不过调用者在泛型字符串的时候必须使用我包里面这个string类型。
.如果按照上面这种其他类型也要去实现。
.还有一种让内置的table泛型也是和外面的LinkedHashMap一样,交给go编译器自己去处理,那这样就没有HashCode()uint64方法了。
例如下面这样我就自定义造了一个String包装类型满足key要求:
type Hashed interface {
// comparable
// string
HashCode() uint64
}
type String struct {
string
}
func (s String) HashCode() uint64 {
return Sum64([]byte(s.string))
}
func MakeString(str string) *String {
return &String{
string: str,
}
}
Go官方建议
Go官方给出使用泛型的意见是使用泛型去减少一些类型一样的重复代码,例如数据结构。但是如果把泛型用一些类型约束上还是和一些其他原因有所差距,要使用嵌套或者组合的方式重新构建新的类型去实现,然后使用构建的类型,例如上面我给出的我的这个例子。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






