一. 引言
作为一名 gopher(以 go 为开发语言的程序猿),每每在迎战互联网大厂的技术面时,都会被问到一些 go 数据结构或者其独有机制的底层实现。比如,之前在面试 “腾讯TEG” 部门一面时,视频会议对面坐着一位儒雅随和的面试官问道:“你平常是用 go 语言是吧,那说一下 go 语言中有哪些引用类型呢?”
我心想,这可难不倒我,于是缓缓答到:“go 语言的引用类型有且切片(slice)、管道(channel)、函数(func)、接口(interface )以及字典(map)”。
面试官又说了,“我看你工作年限不是很长,就不问你 channel 的底层机制了,可能有点难!这样吧,你说一下 map 的底层实现,以及 map 增删数据和扩容时有哪些操作”。
“嘿我这暴脾气,意思是 channel 我就答不上来呗,瞧不起谁呢?”心里不禁细想,这面试官咋这么......善解人意呢
channel 的底层我就了解 CSP、优雅关闭通道等逻辑,要是问到源码实现,我倒真就不会了!但 go 语言中 map 的实现机制不算很复杂,和别的语言在设计上也有区分度,而且我在面试前专门花时间复习了一遍。看来,贴心的面试官不只是要找到最合适的候选人,还要找到最懂他们的人。
二. map 的底层数据结构
于是,我从 map 的数据结构、增删以及扩容等多个操作上描述 map 的底层实现。
首先,我们可以在 go 语言自带的 runtime/map.go 包中,找到 map 的底层数据结构代码:
type hmap struct {
count int // 元素的个数
B uint8 // 代表桶个数为2^B个
overflow uint16 // 溢出桶的数量
buckets unsafe.Pointer // map桶的指针地址
oldbuckets unsafe.Pointer // 发生扩容时,记录扩容前的buckets数组指针
extra *mapextra //用于保存溢出桶的地址
...
}
Go 语言的 map 是由 hmap 结构实现的,hmap 里记录了 map 的多个属性:包括元素个数、桶个数[2^B]、以及 map 桶的地址(buckets),和溢出桶的地址(extra)【后面我们会聊到溢出桶的概念,往下看】。
其中,extra 溢出桶的结构如下,参数分别记录了溢出桶的地址和上下桶指针:
type mapextra struct {
overflow *[]*bmap // 溢出桶的地址
oldoverflow *[]*bmap // 上一个桶的地址
nextOverflow *bmap // 下一个桶的地址
}
buckets 记录了存放 map 桶的 bmap 地址(一个 bucket 可认为是一个 bmap 桶),bmap 是记录 map 实际数据的关键结构,它在未编译时的结构体如下:
type bmap struct {
tophash [bucketCnt]uint8
}
tophash 记录了 map 数据中 key 的前 8 位,用于快速比对该 key 是否在 map 中存在。
当程序在编译期间,bmap 的结构如下:
//在编译期间会产生新的结构体
type bmap struct {
tophash [8]uint8 //存储哈希值的高8位
data byte[1] //key value数据:key/key/key/.../value/value/value...
overflow uintptr
}
bmap 中的 overflow 记录下一个 bmap 的地址,这里 overflow 是 uintptr 而不是 *bmap 类型,是为了保证 bmap 完全不含指针,来减少 gc 扫描。但这样溢出桶就会缺少引用,使用时也可能因为元素为空被 gc 掉,所以 hmap 中新增了 extra 来存储溢出桶的指针。
data 参数存储了真实的 map 数据(k-v 键值对),每个 bmap 存储 8 个 k-v 键值对,bmap 中键值对的存储方式是分开连续存储,如下图所示:

备注:当 k-v 对超过 8 个后,会新生成一个 bmap 存放数据,由 overflow 记录新的 bmap 地址
总结一下
在 go 的 map 实现中,表示的结构体是 hmap,hmap 里维护着若干个 bucket 桶(即 bmap 桶,后续为了统一,bmap 直接称作桶)。为了直观理解,我们提炼 hmap 中的关键字段为图形模式:

buckets 数组中每个元素都是 bmap 结构,每个 bmap 桶保存了 8 个 k-v 对,超过 8 个则新生成一个 bmap,由 overflow 记录新的 bmap 地址。
三. GET 和 PUT 操作
了解 map 的数据结构后,下面来学习 map 中存取数据的过程。
3.1 GET 获取数据
假设当前 B=4,即桶数量为 2^B = 16 个,假设现在要从 map 中获取 key5 对应的 value
m := make(map[string]string, 0)
...
fmt.Println(m[key5])
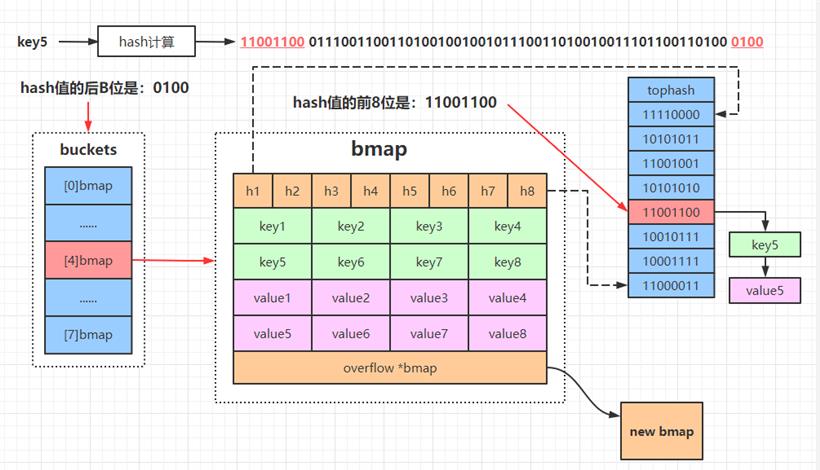
如上图示,get 流程分为:
1.计算 k5 的 hash 值【64 位操作系统,计算结果有 64 个比特位】;
2.通过hash 值的最后 B 位来确定在哪号桶,0100 转为十进制为 4,所以在 4 号桶;
3.根据 hash 值的前 8 位和 tophash 进行比对,快速确定在桶的哪个位置,执行下一步;
4.将查询的 key5 和 bmap 中的 key5 进行比对,如果完全匹配则获取对应 value5;
5.如果在当前桶没找到,就去 overflow 连接的下一个溢出桶里找,重复执行 3-4 步骤。
3.2 PUT存放数据
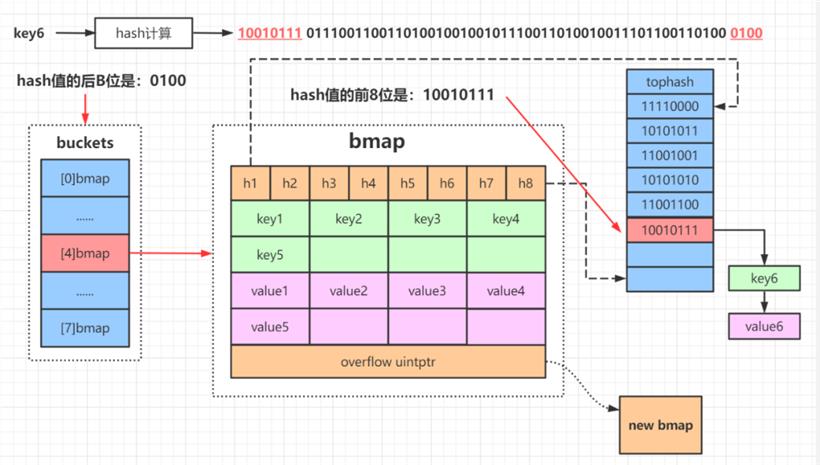
map 赋值可分为以下几步(假设我们添加 key6):
.通过 key6 的 hash 值后 B 位确定是哪一个桶;
.遍历当前桶,通过 key 的 hash 值前 8 位和 tophash 进行对比,防止 key 重复,然后找到存储元素的位置,即bmap 的第一个空位置处插入数据;
.如果当前桶元素已满,会创建一个新的 bmap 桶插入元素,然后用 overflow 记录新 bmap 的地址,并在 hmap 中的 extra 指针数组中添加新桶的引用。
3.3 关于 hash 冲突
当两个不同的 key 落入同一个桶中时,就是发生了哈希冲突。当桶未满时,会用开放寻址法从前往后找到第一个空位进行插入。当 bmap 桶已经有 8 个 k-v 键值对 时,就会新建溢出桶(bmap),并通过 overflow 记录新 bmap 的地址,以及 hmap 的 extra 指针数组中添加新桶的引用 。
四. DELETE操作
map 删除时:
.如果删除的元素是值类型,如 int、float、bool、string 以及数组,map 的内存不会自动释放;
.如果元素是引用类型,如指针、slice、map 和 chan 等,map 内存会释放一部分,但释放的内存是子元素引用类型的内存占用,map 本身的内存占用并没有影响;
.将 map 置为 nil 以后,内存才会释放,下一次 GC 时内存会被回收。
所以,map删除后不会立马释放内存,接下来我们验证一下。
4.1 当 map 值为基本类型时
// 申请一个全局map来保证内存被分配在堆上
var intMap map[int]int
var cnt = 8192
// 堆代码 duidaima.com
// printMemStats 打印内存分配数据
func printMemStats() {
var m runtime.MemStats
runtime.ReadMemStats(&m)
log.Printf("Alloc = %vKB, TotalAlloc = %vKB, Sys = %vKB, NumGC = %v\n",
m.Alloc/1024, m.TotalAlloc/1024, m.Sys/1024, m.NumGC)
}
func initMap() {
intMap = make(map[int]int, cnt)
for i := 0; i < cnt; i++ {
intMap[i] = i
}
}
// 删除map中所有key
func delMapKey() {
for i := 0; i < cnt; i++ {
delete(intMap, i)
}
}
func main() {
printMemStats()
initMap()
log.Println("after initMap, len(map) =", len(intMap))
// 手动进行GC垃圾回收
runtime.GC()
printMemStats()
delMapKey()
log.Println("after delMapKey, len(map) =", len(intMap))
runtime.GC()
printMemStats()
intMap = nil
runtime.GC()
printMemStats()
}
最终打印结果为:
Alloc = 108, TotalAlloc = 108, Sys = 6292, NumGC = 0
after initMap, len(map) = 8192
Alloc = 410, TotalAlloc = 424, Sys = 6867, NumGC = 1
after delMapKey, len(map) = 0
Alloc = 410, TotalAlloc = 425, Sys = 6931, NumGC = 2
Alloc = 99, TotalAlloc = 427, Sys = 6931, NumGC = 3
其中,Alloc 为当前堆对象占用的内存空间,单位是KB;TotalAlloc是累计分配的堆对象空间,Sys是占用操作系统的内存空间,NumGC是垃圾回收的次数。可以明显看出,当 map 删除基本类型元素后,无论怎样 GC,内存都没有释放。
4.2 当 map 值为引用类型时
type Person struct {
Name string
Age int
}
var intMap map[int]*Person
func initMap() {
intMap = make(map[int]*Person, cnt)
for i := 0; i < cnt; i++ {
intMap[i] = &Person{
Name: "zhangsan",
Age: 20,
}
}
}
修改 map 的值类型为引用类型,其余代码不变,再次执行结果:
Alloc = 108, TotalAlloc = 108, Sys = 6036, NumGC = 0
after initMap, len(map) = 8192
Alloc = 601, TotalAlloc = 615, Sys = 6867, NumGC = 1
after delMapKey, len(map) = 0
Alloc = 409, TotalAlloc = 615, Sys = 6931, NumGC = 2
Alloc = 99, TotalAlloc = 618, Sys = 6931, NumGC = 3
两个例子对比可以发现,当 map 值为基本类型时,对 key 进行删除操作不会释放空间;而当 map 值为引用类型时,会释放一部分空间(value 的堆上空间),但是 map 本身占用的内存并没有减少,这是为什么呢?
因为 map 底层在申请 bmap 桶后,桶的数量只会增不会减。而 map 的 delete 操作只会将 bmap 上的数据置为 nil(如果 value 是指针类型,那指针对象就被在下一次 GC 的时候被回收),但 bucket 本身占用的内存并没有变化,所以 map 本身的内存占用并不会因为删除了 key 而减少。
特别地,删除 key 之后 bmap 桶上出现空位,之后增加了新的 key,可能会把桶的空位填上,这时 map 的内存占用不变。
4.3 如何解决 map 引发的内存泄漏
当 map 频繁进行增删,或者添加了太多 key 时(触发 map 扩容),即便删除了这些 key,内存空间仍然降不下来,从而引发内存泄漏。
我们可以采用以下方法来解决:
1.将不再使用的 map 置为 nil,或者定期重启系统,让 map 重新分配;
2.当 map 的 value 占用内存比较大时,将 value 值改为指针;
3.定期将 map 里的元素拷贝到另一个 map 中。
一般,大流量冲击的互联网业务大都是 ToC 场景,上线频率非常高。有的业务可能一天上线好几次,在问题暴露之前就已经重启恢复了,问题不大🐶
五. map 的扩容条件
5.1 相同容量扩容
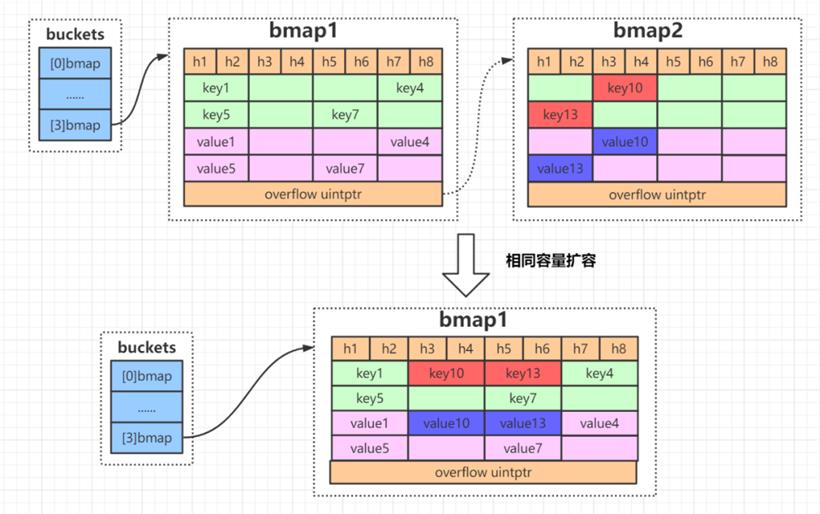
由于 map 不断 put 和 delete 元素,因此桶中可能会出现很多断断续续的空位,这些空位会导致 bmap 溢出桶很多,导致扫描时间变长。所以,这种扩容实际上是一种整理,把后置位的数据整理到前面。等量扩容时,元素会发生重排,但不会换桶,且元素桶的个数也不会增加。
5.2 二倍容量扩容
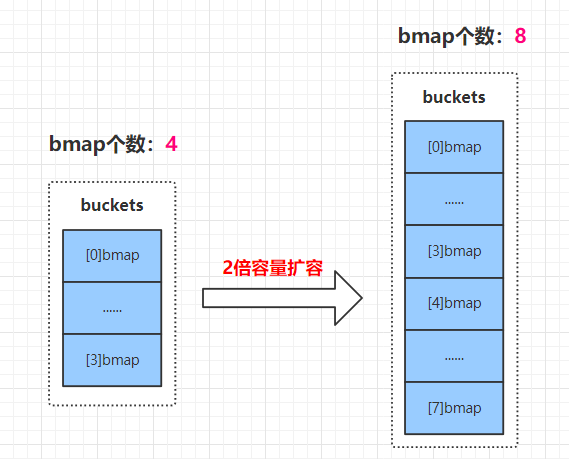
当桶数组不够用了,就会发生扩容,这时,元素会重排,bmap 桶增加,桶里面的 key 元素也可能会发生迁移。
如图所示,扩容前 B=2,扩容后 B=3,假设一个元素 key 的 hash 值后三位为 101,那么由上文介绍可知,扩容前,hash 值的后两位来决定几号桶。即扩容前,元素的后两位为 01,元素在 1 号桶;扩容后,元素的后三位为 101,元素需要迁移至 5 号桶。
5.3 发生扩容的条件
1) 扩容条件1:装载因子 > 6.5
正常情况,如果没有溢出桶,那么一个桶中最多有 8 个元素,当平均每个桶中的元素超过 6.5 个时,就意味着当前桶的容量快满了,需要扩容。装载因子 = map中元素的个数 / map中当前桶的个数,即 loadFactor = count / (2^B) 。
从公式可得,装载因子是指当前 buckets 中,每个桶的平均元素个数。
2)扩容条件2:溢出桶的数量过多
当 B < 15 时,如果 overflow 的 bmap 数量达到 2^B;
当 B >= 15 时,overflow 的 bmap 数量超过 2^15 后,开始扩容。
溢出桶数量过多的原因是:map 中大量 key 的 hash 值后 B 位都一样,使得个别 bmap 桶一直在插入新数据,进而导致它的溢出桶链条越来越长。
这样,当 map 在进行增删改查时,扫描速度就会越来越慢。当扩容后,可以对这些溢出桶的元素进行重排,使得元素在桶的位置更平均一些,以此提升扫描的效率。
3)扩容时的细节
在我们的 hmap 结构体中有一个 oldbuckets,扩容刚发生时,会把老数据先存到这个里面然后扩容 buckets,此时 buckets 容量是 oldbuckets 的两倍;
map 扩容是增量扩容非全量扩容,每次对 map 进行删改时,会触发从 oldbuckets 迁移到 buckets 的操作。这是因为全量扩容时如果 key 的数量很多,会极大耗费资源进而导致程序卡顿;
在扩容没有完全迁移完成之前,每次 get 或 put 遍历数据时,都会先遍历 oldbuckets,然后再遍历 buckets。
六. map 的注意事项
1)不可对元素取址
随着 map 元素的增长,map 底层可能会重新分配空间,导致之前的地址无效,我们来看一个例子:
type Student struct {
Name string
Age int
}
func f1() {
m := map[int]Student{
1: Student{Age: 15, Name: "jack"},
2: Student{Age: 16, Name: "danny"},
3: Student{Age: 17, Name: "andy"},
}
m[1].Name = "JACK" // 编译错误!!
}
这种情况会发生编译错误,因为 map 无法取址。即,可以得到 m[1],但不能对它的值作出任何修改。如果你想修改 value,可以使用带指针的 value,如下:
func f2() {
m := map[int]*Student{
1: &Student{Age: 15, Name: "jack"},
2: &Student{Age: 16, Name: "danny"},
3: &Student{Age: 17, Name: "andy"},
}
m[1].Name = "JACK"
}
2)线程不安全
假设某 map 桶数量为 4,即 B=2,当前元素数量也为 4,即桶满了。此时,两个 goroutine (g1 和 g2)对这个 map 进行读写操作,g1 插入 key1,g2 读取 key2,可能会发生以下情况:
g2 计算 key2 的 hash 值【1101......101】,B=2,并确定桶号为1;
g1 添加 key1,触发扩容条件,B 增加为 3,桶个数扩容为 8 个;
map 中的 key 开始数据迁移,假设迁移很快完成,这时 key2 从桶 1 迁移到了第 5 个桶;
g2 从桶 1 中遍历,获取数据失败!
所以,当操作 map 时,可以用 Go 自带的 sync.RWMutex 锁,或者使用 sync.Map(可支持并发锁和共享锁)来保证线程安全。
七. 后记
答完这些,面试官脸上依旧波澜不惊,淡淡说到:“那我们要不接着聊一聊 channel 吧?”
于是我硬着头皮,把所学知识点全都怼了出来,面试官似乎也看出了我的水平,不再为难,开始进行下一个话题。
面试完成后,我不禁心想:“不愧是企鹅厂,看来面对的候选人都是个顶个的强者啊!”
如今,在互联网行情如此冷峻的背景下,我们想要迎战互联网大厂的技术面,对所学技术不仅得应用广泛,还得在底层机制的认知上花一番功夫。毕竟,八股文谁都会背,算法题谁都会刷,面试官在筛选时也不得不加大难度,以测试候选人的知识广度和深度!而你和别人的差距,说不定就是这么一个 map 的距离。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






