

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

// dead-code-elimination/demo1
$tree -F .
.
├── go.mod
├── main.go
└── pkga/
└── pkga.go
// 堆代码 duidaima.com
// main.go
package main
import (
"fmt"
"demo/pkga"
)
func main() {
result := pkga.Foo()
fmt.Println(result)
}
// pkga/pkga.go
package pkga
import (
"fmt"
)
func Foo() string {
return "Hello from Foo!"
}
func Bar() {
fmt.Println("This is Bar.")
}
这个示例十分简单!main函数中调用了pkga包的导出函数Foo,而pkga包中除了Foo函数,还有Bar函数(但并没有被任何其他函数调用)。现在我们来编译一下这个module,然后查看一下编译出的可执行文件中都包含pkga包的哪些函数!(本文实验中使用的Go为1.22.0版本[1])$go build $go tool nm demo|grep demo在输出的可执行文件中,居然没有查到关于pkga的任何符号信息,这可能是Go的优化在“作祟”。我们关闭掉Go编译器的优化后,再来试试:
$go build -gcflags '-l -N' $go tool nm demo|grep demo 108ca80 T demo/pkga.Foo关掉内联优化后,我们看到pkga.Foo出现在最终的可执行文件demo中,但并未被调用的Bar函数并没有进入可执行文件demo中。
// dead-code-elimination/demo2
$tree .
.
├── go.mod
├── main.go
├── pkga
│ └── pkga.go
└── pkgb
└── pkgb.go
// pkga/pkga.go
package pkga
import (
"demo/pkgb"
"fmt"
)
func Foo() string {
pkgb.Zoo()
return "Hello from Foo!"
}
func Bar() {
fmt.Println("This is Bar.")
}
在这个示例中,我们在pkga.Foo函数中又调用了一个新包pkgb的Zoo函数,我们来编译一下该新示例并查看一下哪些函数进入到最终的可执行文件中:$go build -gcflags='-l -N' $go tool nm demo|grep demo 1093b40 T demo/pkga.Foo 1093aa0 T demo/pkgb.Zoo我们看到:只有程序执行路径上能够触达(被调用)的函数才会进入到最终的可执行文件中!
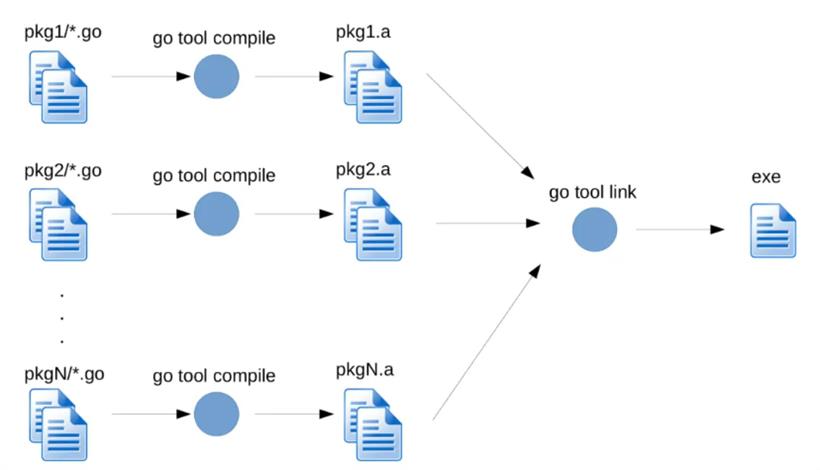
$go build -ldflags='-dumpdep' -gcflags='-l -N' > deps.txt 2>&1 $grep demo deps.txt # demo main.main -> demo/pkga.Foo demo/pkga.Foo -> demo/pkgb.Zoo demo/pkga.Foo -> go:string."Hello from Foo!" demo/pkgb.Zoo -> math/rand.Int31n demo/pkgb.Zoo -> demo/pkgb..stmp_0 demo/pkgb..stmp_0 -> go:string."Zoo in pkgb"到这里,我们知道了Go通过某种机制保证了只有真正使用到的代码才会最终进入到可执行文件中,即便某些代码(比如pkga.Bar)和那些被真正使用的代码(比如pkga.Foo)在同一个包内。这同时保证了最终可执行文件大小在可控范围内。
3.标记完成后,算法会将所有未被标记的符号标记为不可达的未用。这些未被标记的符号表示不会被入口点或其他可达符号访问到的代码。
// dead-code-elimination/demo3/main.go
type X struct{}
type Y struct{}
func (*X) One() { fmt.Println("hello 1") }
func (*X) Two() { fmt.Println("hello 2") }
func (*X) Three() { fmt.Println("hello 3") }
func (*Y) Four() { fmt.Println("hello 4") }
func (*Y) Five() { fmt.Println("hello 5") }
func main() {
var name string
fmt.Scanf("%s", &name)
reflect.ValueOf(&X{}).MethodByName(name).Call(nil)
var y Y
y.Five()
}
在这个示例中,类型*X有三个方法,类型*Y有两个方法,在main函数中,我们通过反射调用X实例的方法,通过Y实例直接调用Y的方法,我们看看最终X和Y都有哪些方法进入到最后的可执行文件中了:$go build -gcflags='-l -N' $go tool nm ./demo|grep main 11d59c0 D go:main.inittasks 10d4500 T main.(*X).One 10d4640 T main.(*X).Three 10d45a0 T main.(*X).Two 10d46e0 T main.(*Y).Five 10d4780 T main.main ... ...我们看到通过直接调用的可达类型Y只有代码中直接调用的方法Five进入到最终可执行文件中,而通过反射调用的X的所有方法都可以在最终可执行文件找到!这与前面提到的第三种情况一致。





