

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

前言
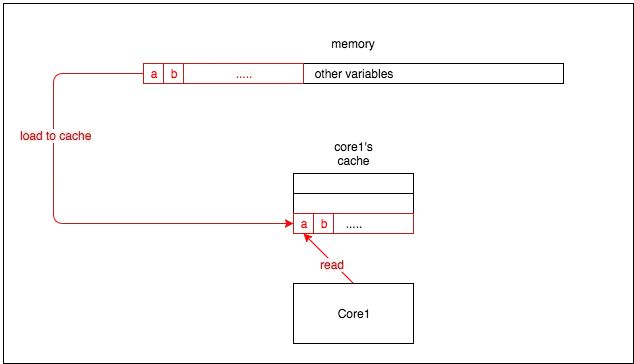
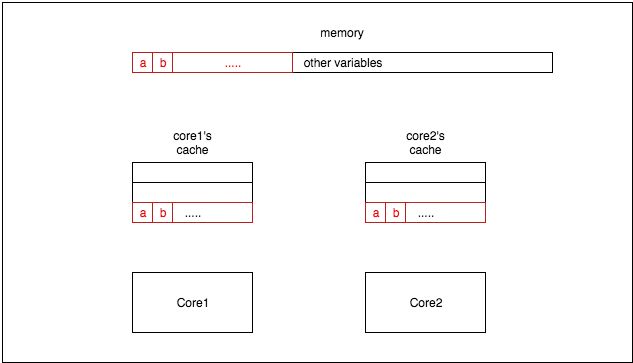
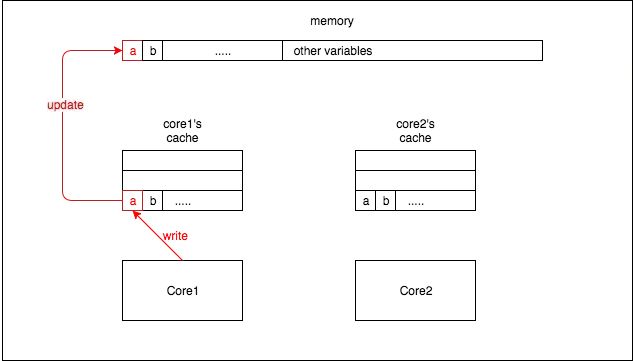
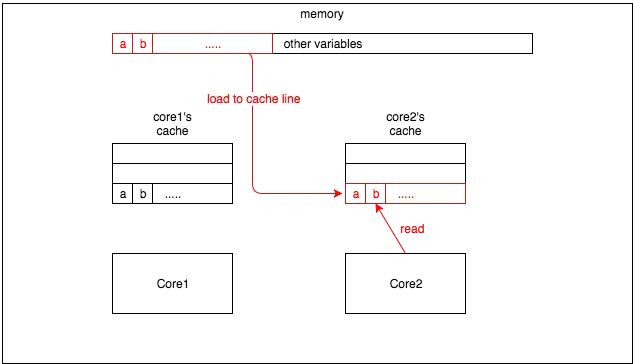
在解释伪共享(false sharing)之前,有必要简要介绍一下 CPU 架构中缓存是如何工作的。CPU 缓存中的最小单位是缓存行(cache line)(如今,CPU 中常见的缓存行大小为 64 字节)。因此,当 CPU 从内存读取一个变量时,它会同时读取该变量附近的所有变量。图 1 是一个简单的例子:
type NoPad struct {
a uint64
b uint64
c uint64
}
func (myatomic *NoPad) IncreaseAllEles() {
atomic.AddUint64(&myatomic.a, 1)
atomic.AddUint64(&myatomic.b, 1)
atomic.AddUint64(&myatomic.c, 1)
}
还有另一个我在变量之间添加了 [8]uint64 以进行填充的结构体:type Pad struct {
a uint64
_p1 [8]uint64
b uint64
_p2 [8]uint64
c uint64
_p3 [8]uint64
}
func (myatomic *Pad) IncreaseAllEles() {
atomic.AddUint64(&myatomic.a, 1)
atomic.AddUint64(&myatomic.b, 1)
atomic.AddUint64(&myatomic.c, 1)
}
然后我编写了一个简单的代码来运行基准测试:func testAtomicIncrease(myatomic MyAtomic) {
paraNum := 1000
addTimes := 1000
var wg sync.WaitGroup
wg.Add(paraNum)
for i := 0; i < paraNum; i++ {
go func() {
for j := 0; j < addTimes; j++ {
myatomic.IncreaseAllEles()
}
wg.Done()
}()
}
wg.Wait()
}
func BenchmarkNoPad(b *testing.B) {
myatomic := &NoPad{}
b.ResetTimer()
testAtomicIncrease(myatomic)
}
func BenchmarkPad(b *testing.B) {
myatomic := &Pad{}
b.ResetTimer()
testAtomicIncrease(myatomic)
}
在 2014 年的 MBA 上运行的基准测试如下:$> go test -bench=. BenchmarkNoPad-4 2000000000 0.07 ns/op BenchmarkPad-4 2000000000 0.02 ns/op PASS ok 1.777s基准测试的结果显示,性能从 0.07 ns/op 提高到了 0.02 ns/op,这是一个很大的改进。你也可以在其他语言(如 Java)中测试这一点,我相信你会得到相同的结果。在你将其应用到生产环境之前,你应该了解两个关键点:
$ go test -bench=. -v goos: darwin goarch: arm64 pkg: false-sharing BenchmarkNoPad BenchmarkNoPad-8 1000000000 0.09618 ns/op BenchmarkPad BenchmarkPad-8 1000000000 0.1065 ns/op PASS ok false-sharing 2.368s跟作者的结果完全相反,哈哈。我们可以写一个简单的基准测试来验证使用 cache padding 来解决 false sharing 的效果:
package main
import (
"sync/atomic"
"testing"
)
func BenchmarkPadding(b *testing.B) {
b.Run("without_padding", func(b *testing.B) {
nums := [128]atomic.Int64{}
i := atomic.Int64{}
b.RunParallel(func(pb *testing.PB) {
id := i.Add(1)
for pb.Next() {
nums[id].Add(1)
}
})
})
b.Run("with_padding", func(b *testing.B) {
type pad struct {
val atomic.Int64
_ [8]uint64
}
nums := [128]pad{}
i := atomic.Int64{}
b.RunParallel(func(pb *testing.PB) {
id := i.Add(1)
for pb.Next() {
nums[id].val.Add(1)
}
})
})
}
在 without_padding 场景中,由于 nums 数组的元素可能共享相同的缓存行,多个 goroutine 同时修改相邻元素时会导致缓存行失效,从而降低性能。而在 with_padding 场景中,通过在高频访问的变量之间加入缓存填充 _ [8]uint64,使得每个元素都占据独立的缓存行,减少了这种缓存行的失效情况,预期能观察到性能的提升。$ go test -bench=. -v goos: darwin goarch: arm64 pkg: false-sharing BenchmarkPadding BenchmarkPadding/without_padding BenchmarkPadding/without_padding-8 55441728 22.09 ns/op BenchmarkPadding/with_padding BenchmarkPadding/with_padding-8 1000000000 1.075 ns/op PASS ok false-sharing 4.255s基准测试的结果显示,性能从 22.09 ns/op 提高到了 1.075 ns/op。





