麻省理工学院和香港中文大学联合发布了LongLoRA,这是一种全新的微调方法,可以增强大语言模型的上下文能力,而无需消耗大量算力资源。通常,想增加大语言模型的上下文处理能力,需要更多的算力支持。例如,将上下文长度从2048扩展至8192,需要多消耗16倍算力。
LongLoRA在开源模型LLaMA2 7B/13B/70B上进行了试验,将上下文原始长度扩展至32K、64K、100K,所需要的算力资源却很少。
开源地址:https://github.com/dvlab-research/LongLoRA
论文地址:https://arxiv.org/abs/2309.12307
LongLoRA的高效微调方法
根据LongLoRA的论文介绍,采用了两大步骤完成了高效微调。第一,在训练期间使用一种更简单的注意力形式(聚焦于特定信息),开发者称之为转变短注意力(S2-Attn)。这种新的注意力方法有助于节省大量的计算能力,而且几乎与常规的注意力方法一样有效,在训练过程中发挥了重要作用。
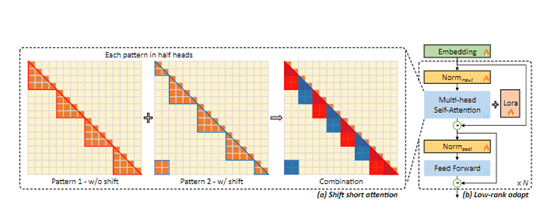
第二,重新挖掘了一种有效扩大上下文(用于训练的信息量)的方法。开发人员发现,一种名为LoRA的方法对此非常有效,尤其是当与可训练的嵌入和规范化一起使用时。
LongLoRA在各种任务上都显示出了优异的结果,可以与不同大小的LLMs一起使用。它可以将用于训练的数据量从4k增加到100k,对于另一个模型,可以增加到32k,所有这些都在一台强大的计算机机器上完成。此外,它与其他现有技术兼容性很强,并不会改变原始模型设计架构。

此外,为了让 LongLoRA 更加实用、高效,开发者还整理了一个名为 LongQA 的数据集,其中包含 3000 多对用于训练的问题和答案。这使得 LongLoRA 还能有效改进大语言模型的输出能力。
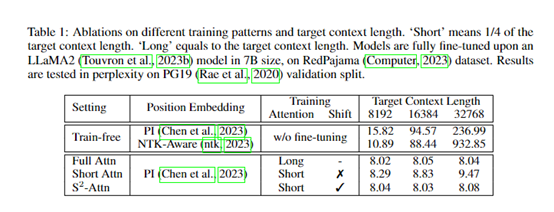 研究发现
研究发现
该研究评估了Proof-pile 和 PG19数据集上的不同模型。研究发现,在训练过程中,随着上下文大小的增加,模型的表现更好,显示了其微调方法的有效性。简单来说,使用更多信息进行训练,将会带来更好的结果。例如,当上下文窗口大小从 8192 增加到 32768 时,一个模型的困惑度性能从 2.72 提高到 2.50。
该研究还探讨了这些模型可以在一台机器上处理多少上下文。开发人员扩展了模型以处理极长的上下文,并发现模型仍然表现良好,尽管上下文尺寸较小时性能有所下降。
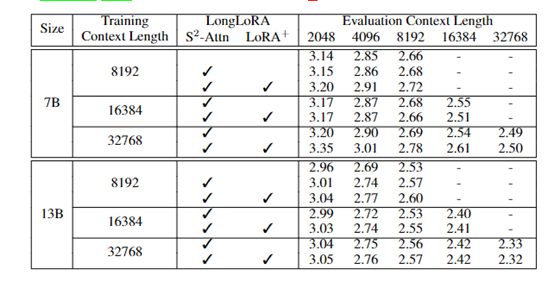
除了语言建模之外,该研究还测试了其他任务,包括在很长的对话中找到特定的主题。开发人员的模型在这项任务中的表现与最先进的模型类似,甚至在某些情况下表现得更好。值得一提的是,与竞争对手相比,开发人员的模型能够更有效地适应开源数据。
LongLoRA表明,大模型能够处理的信息越多,理解语言的能力就越强。并且它不仅擅长处理长文本,而且LongLoRA也非常擅长在长对话中找到特定的主题。这表明它可以处理现实世界中复杂而混乱的任务。但因为加大了上下文窗口,所以LongLoRA在处理较短的文本片段时会有一些问题,这个问题作者还没有找到原因。
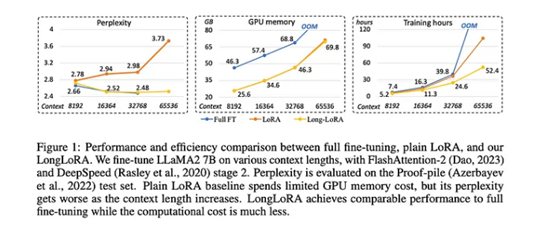
总体来说,LongLoRA 在大型语言模型领域提出了创新方法,在处理大量信息时,也可以更轻松、更高效地微调这些模型,而必须消耗更多的算力资源。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






