就在前几天,Open AI 推出了新一代视频模型 Sora,又引发了一次 AI 领域的震动,大家纷纷惊呼这是又一个里程碑的时刻。然而,谷歌这次丝毫不落下风,火速发布了新一代多模态大模型 Gemini1.5。
超长上下文
人工智能模型的 “上下文窗口” 由标记(tokens)组成,这是用于处理信息的基本构建单元。标记可以是单词、图像、视频、音频或代码的整个部分或子部分。模型的上下文窗口越大,它就能在给定的提示中接收并处理更多的信息 — 使其输出更一致、相关且有用。
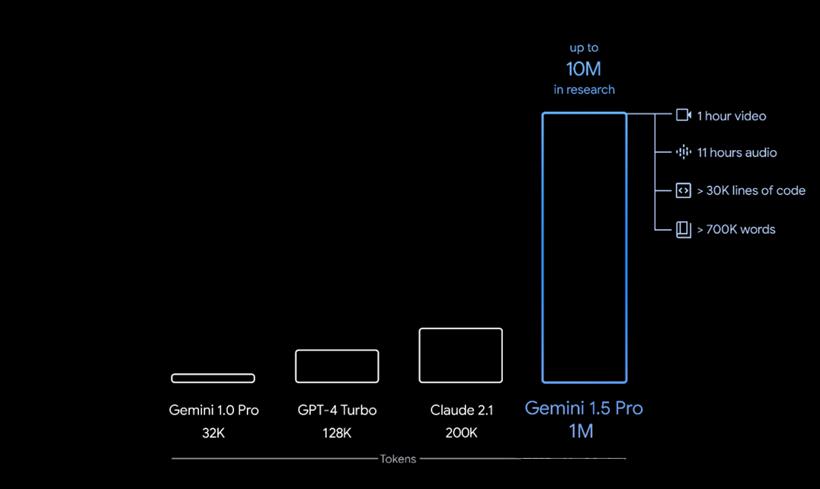
新一代的 Gemini 在长上下文理解方面取得了重大的突破,可以处理的信息量持续运行多达 100 万个Token,实现了迄今为止任何大型基础模型中最长的上下文处理能力,毫不夸张地说,这已经全面碾压了 OpenAI 目前最强的 GPT-4 Turbo 模型。
另外,作为一个多模态模型,Gemini 1.5 可不只能处理文字,它还能够一次性处理其他大量的信息 — 包括 1 小时的视频、11 小时的音频、超过 30,000 行代码的代码库或超过 700,000 个单词。100 万 Token 说的还是比较保守,它只是生产环境中稳定测试的结果,在谷歌的研究中,他们还成功测试了多达 1000 万个 Token 的上下文。
Gemini 1.5 构建在基于 Transformer 和 MoE 架构的研究之上。传统的 Transformer 作为一个大型的神经网络运行,而 MoE 模型则被划分为更小的“专家”神经网络。根据给定的输入类型,MoE 模型学会了有选择性地仅激活其神经网络中最相关的专家路径,这种架构大幅提高了模型的效率。
事实如何呢?Gemini 真的有官方吹的这么牛逼吗?我们来用几个例子验证一下。
文本测试 - 30 万 Token
首先使用阿波罗 11 号登月任务报告(一个 402 页的 PDF 文件,大约 33 万个 Token)做了一个测试。首先将阿波罗的 PDF 文件上传到 Google AI studio
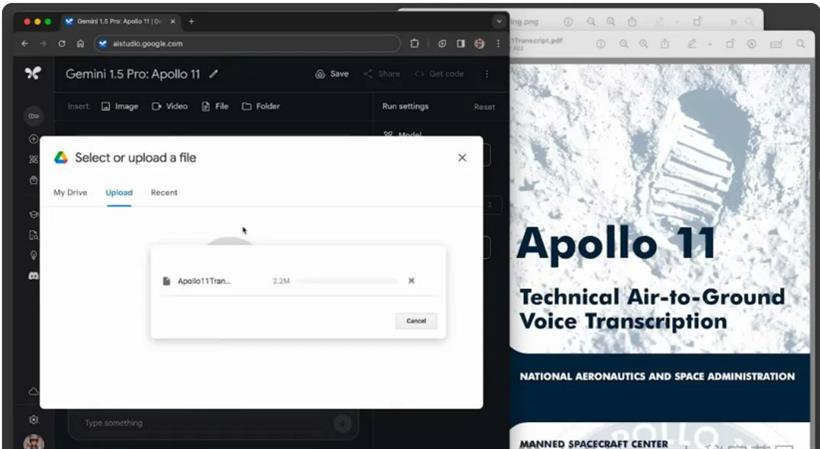
然后提出问题:
“Find 3 comedic moments. List quotes from this transcript and emoji.”
“从这份记录中找出3个有趣的时刻,列出有趣的引述并附上 emoji 表情。”
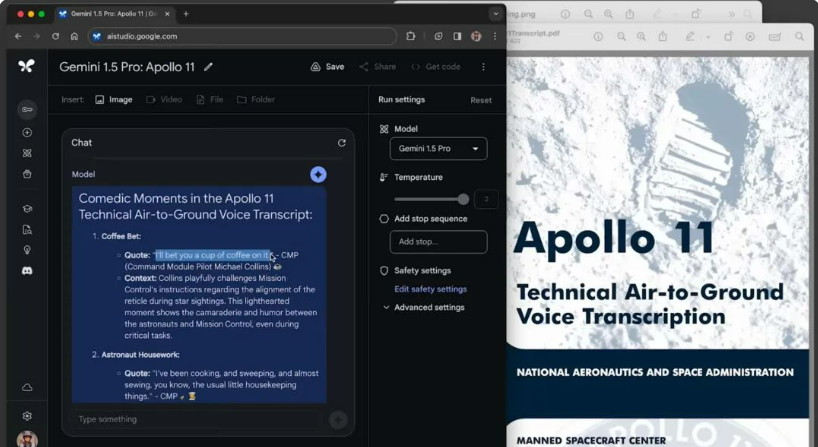
模型给出的回应是三段引述,比如来自迈克尔·柯林斯的这一段:
“I’ll bet you a cup of coffee on it.”
“我敢跟你打赌一杯咖啡。”
然后我们回到这份原始报告中,可以发现模型准确找到了这个引述,并准确提取出这个有趣的时刻。
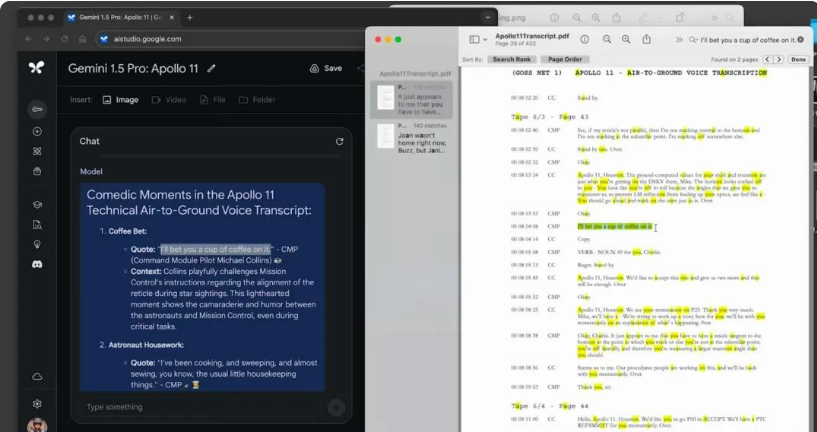
接着,我们再给出一个自己想象的一个抽象场景的描绘,然后问:
“What moment is this?”
“这是什么时刻?”
模型正确地确定这是尼尔·阿姆斯特朗在月球上的第一步。
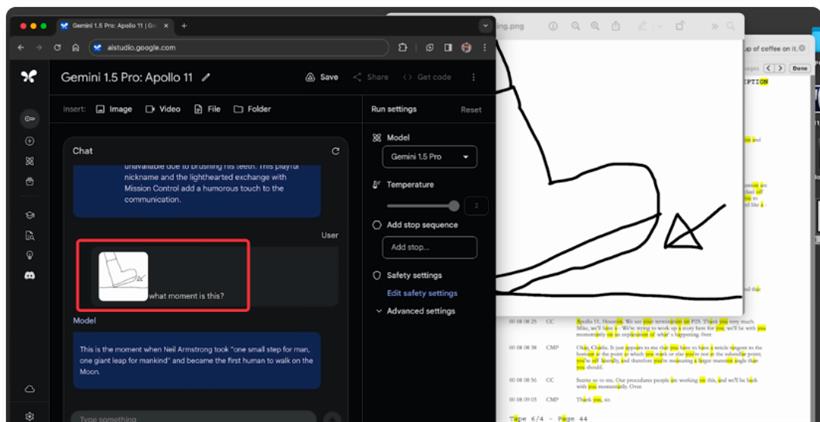
这效果还是相当炸裂的。。。
这个例子很好的证明了,Gemini 1.5 Pro 可以理解、推理和识别阿波罗 11 号登月任务报告的各种有趣的细节。
视频测试 - 60 万 Token
另外,Gemini 1.5 Pro 还能够对不同类型的模态执行高度复杂的理解和推理任务,包括视频。例如,当给定一部 44 分钟的无声喜剧片段,例如巴斯特·基顿的电影时,模型可以准确地分析各种情节要点和事件,甚至能够推理出电影中可能轻易被忽略的细节。

这部 44 分钟的电影总长度高达 60 万个 Token。
首先在 Google AI Studio 中上传这部电影,然后提问:
“Find the moment when a piece of paper is removed from the person's pocket and tell me some key information on it, with the timecode.”
“找出电影中某人口袋里取出一张纸的时刻,并告诉我上面的一些关键信息,以及时间码。”
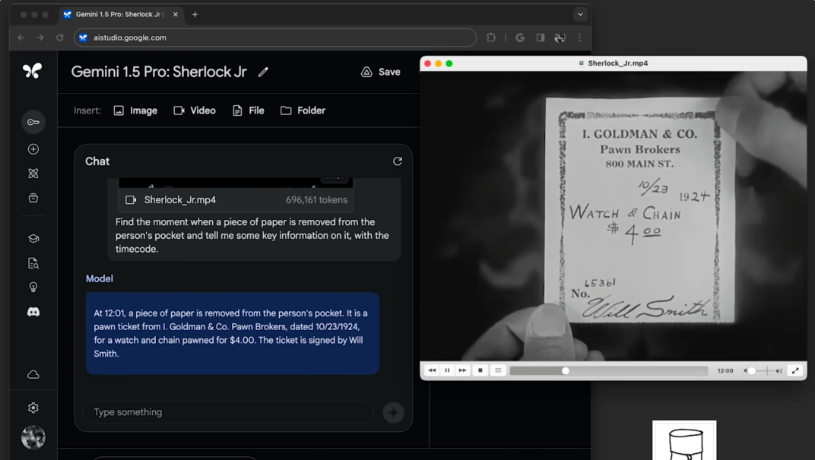
然后模型准确地找到了电影中纸片从某人口袋里被取出的那一刹那,并且准确地提取了上面的文字,而且时间也是准确的。
接下来,我们再给出一个比较抽象的图片场景描绘,并且询问发生这件事的时间点是什么?
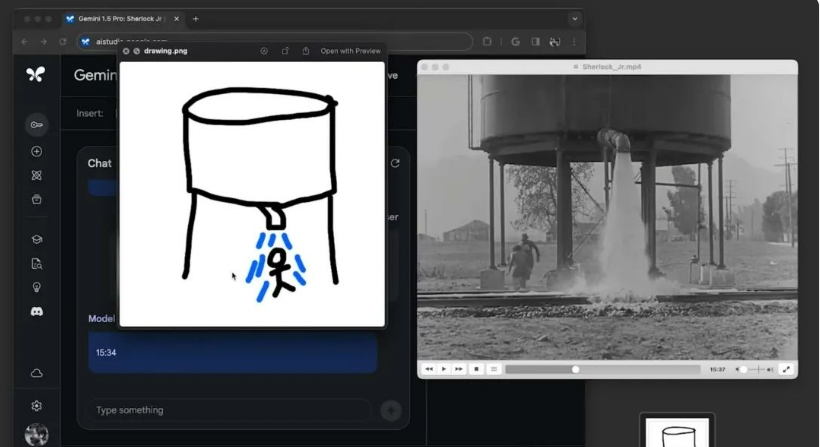
模型返回的时间点是 15:34,然后我们查找这个时间码,发现这正是我们所寻找的场景。
代码测试 - 80 万 Token
下面我们再来验证一下它的代码理解能力。我们提取了所有 Three.js 示例的代码,并将其合并为一个 txt 文件上传到 Google AI Studio 中 (超过 80 万个 Token)。然后,我们要求模型找到三个学习角色动画的示例。
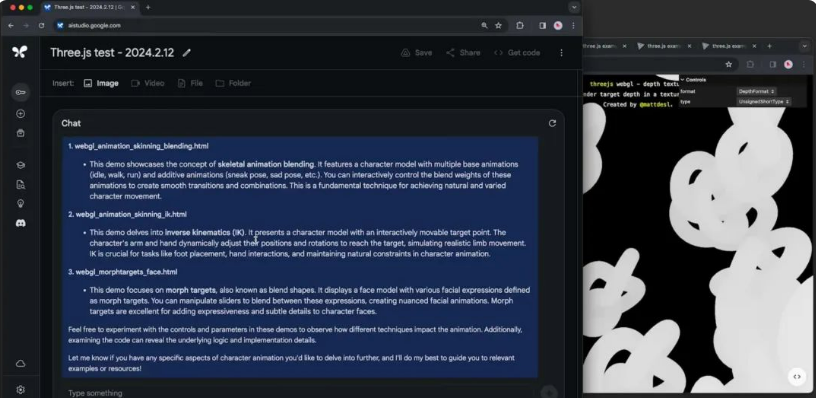
模型查找了数百个示例,并挑选出了三个,包括关于混合骨骼动画、关于姿态以及关于面部动画的形态目标的示例,这些都是根据我们的提示进行选择的合适内容。
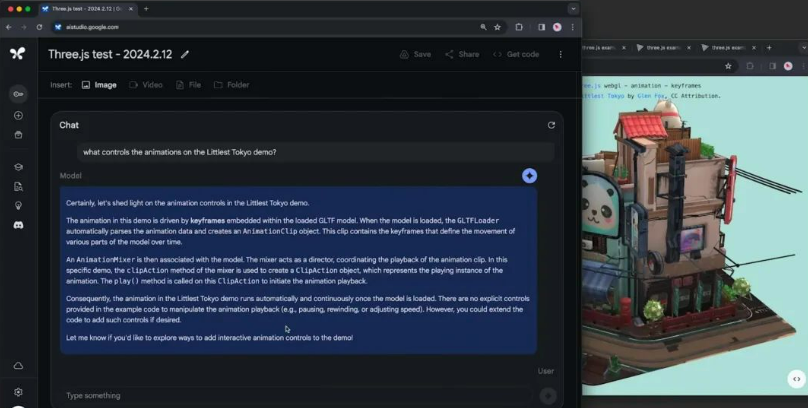
接下来,我们询问了驱动 “Littlest Tokyo” 示例中的动画的是什么。可以看到,模型也成功地找到了那个演示,并解释了动画是在 gLTF 模型中嵌入的。然后,我们想知道是否可以定制这段代码,因此我们询问:
“请展示一些添加滑块以控制动画速度的代码,并使用其他演示中的那种界面。”
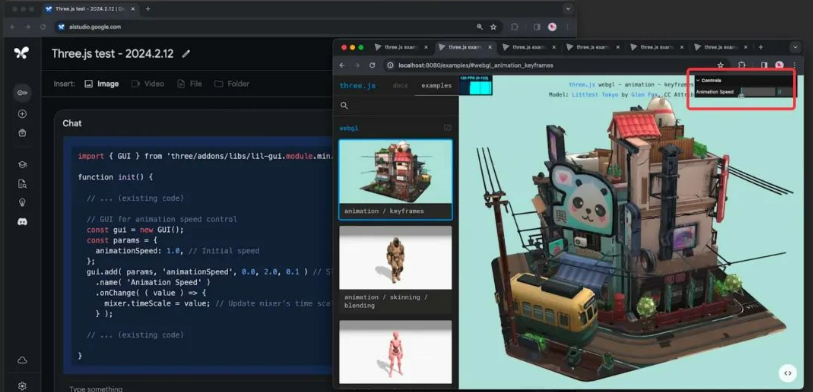
然后模型也非常准确的给出了我们想要的答案,在修改后的版本则增加了一个小滑块,可以提高,降低甚至停止动画。然后我们再测试一下多模态的能力,给他发送一张某个示例中的截图,我们没有对这个截图做任何说明,只是询问我们可以在哪里找到这个演示的代码:
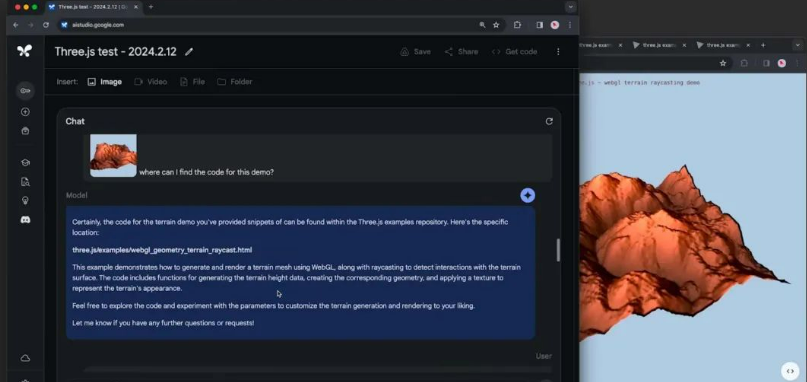
然后,模型能够在数百个演示中找到与这幅图像匹配的那一个。接下来,我们要求模型对场景进行一些更改,询问:“我如何修改代码以使地形更平坦?”
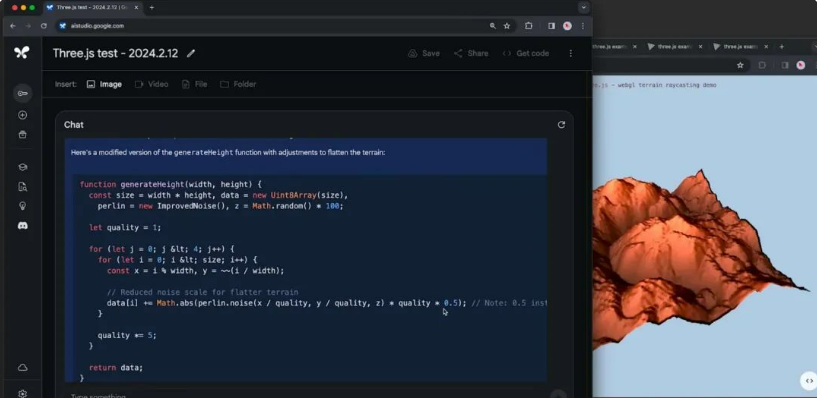
模型能够精确地找到一个特定的函数 “generate height”,并显示出需要调整的精确行。
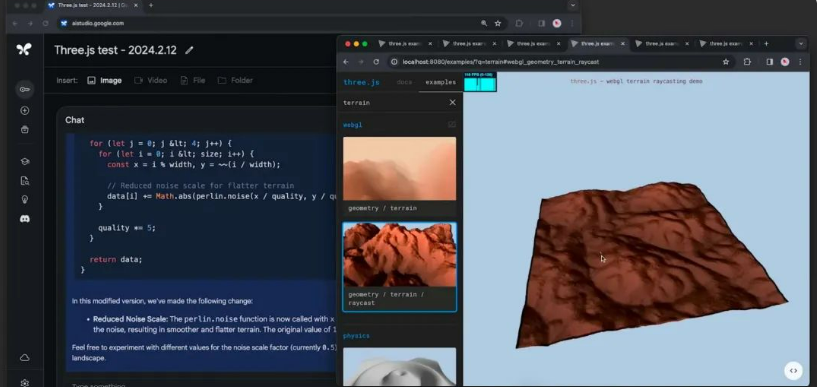
给出的代码清晰地解释了这种变化是如何工作的,而在更新的版本中,地形确实如我们所请求的那样变得更加平坦。
最后
之前使用大模型最大的痛就是上下文限制太小了,如今 Gemini 1.5 似乎真正突破了上下文的限制,这种感觉真的太爽了。另外也不得不感叹 AI 的发展真的太快了。对于谷歌最新的 Gemini 1.5 ,大家怎么看?欢迎在评论区留言。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






