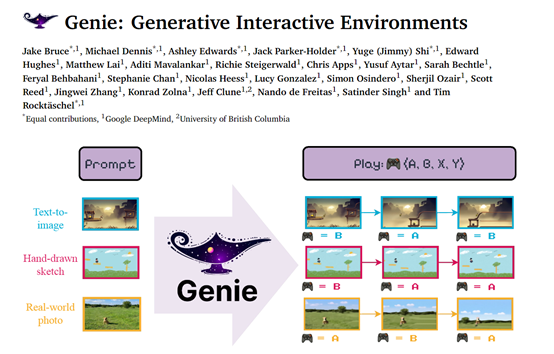
谷歌DeepMind的研究人员推出了,首个无需数据标记、无监督训练的生成交互模型——Generative Interactive Environments,简称“Genie”。Genie有110亿参数,可以根据图像、真实照片甚至草图,就能生成各种可控制动作的视频游戏。Genie之所以有如此神奇功能,主要使用了3万小时,6800万段的游戏视频进行了大规模训练。
并且在训练过程中没有使用任何真实动作标签或其他特定提示,但Genie可以基于帧级别的,使用户在生成的环境中进行各种动作控制非常强!值得一提的是,Genie是一个通用基础模型,也就是说其学到的潜在动作关系、序列、空间可以应用在其他领域中。
论文地址:https://arxiv.org/abs/2402.15391
项目地址:https://sites.google.com/view/genie-2024/home
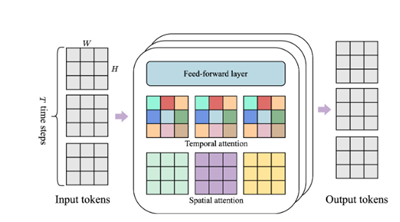
Genie的核心架构用了ST-Transformer(时空变换器)。这是一种结合了Transformer模型的自注意力机制与时空数据的特性,以有效处理视频、多传感器时间序列、交通流量等时空数据。
ST-Transformer主要通过捕捉数据在时间和空间上的复杂依赖关系,提高了对时空序列的理解和预测能力,主要有3大模块组成。

图2.将一张草图,直接生成可控的小游戏
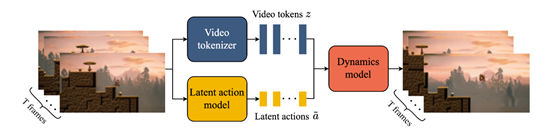
视频分词器
这是一个基于VQ-VAE的模块,可将原始视频帧压缩成离散的记号表示,以降低维度并提高后续模块的视频生成质量。

这个过程类似自然语言处理中的分词,将连续的视频帧序列分解为离散的视频片段。视频分词器使用了ST-transformer来对视频进行编码,并生成对应的视频标记。这些标记将作为后续动力学模型的输入,用于预测下一帧视频。
潜在动作模型
这是一个无监督学习模块,可从原始视频中推断出观察到的状态变化对应的潜在动作。并根据这些潜在动作实现对每一帧的控制。潜在动作模型通过对视频标记序列进行建模,学习到了不同帧之间的动作关系。
具体来说,潜在动作模型可以将一个视频标记序列作为输入,并生成对应的潜在动作序列。这些潜在动作序列可以用于控制生成环境中的每一帧,使用户能够在生成的交互环境中进行精确的操作。
动力学模型
主要基于潜在动作模型学习到的动作关系,根据潜在动作和过去的帧标记预测下一帧的视频。可以把该模块看作是一个预测模型,通过学习视频序列的动态变化模式,能够生成逼真的连续视频。
动力学模型的输入包括前一帧的图像表示和当前帧的动作表示。为了将图像表示和动作表示进行融合,Genie采用了一个基于Transformer架构的编码器来对它们进行编码。
在编码器中,首先对前一帧的图像进行编码,并采用了一种视频标记器的方法,将图像分割成若干个离散的标记,每个标记代表图像中的一个局部区域。这种分割可以帮助模型捕捉到图像中的空间信息。

当前帧的动作表示也通过编码器进行编码。动作表示可以是离散的动作类别或连续的动作向量,具体的形式取决于具体的应用场景。编码器将动作表示转换为一个固定长度的向量,以便与图像表示进行融合。在获得图像表示和动作表示的编码后,它们被输入到动力学模型中进行预测。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






