

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

前段时间,斯坦福大学人工智能研究院(Stanford HAI)发布了一份报告,表示美国在大模型领域遥遥领先。报告指出,2023 年 61 个著名的人工智能模型来自美国的机构,远远超过欧盟的 21 个和中国的 15 个。OpenAI 早期投资人 Vinod Khosla 去年还曾在 X 发文称,美国的开源模型都会被中国抄袭。然而,一直被认为在「追赶美国」的国产大模型现在却成了被抄袭的对象,而这个抄袭的 AI 团队,正是来自发布上述报告的斯坦福大学。
在实锤之下,斯坦福团队也不得不紧急道歉。正如面壁智能 CEO 李大海调侃式的回应,这是一种「受到国际团队认可的方式」。无论我们距离最顶尖的大模型还有多少差距,但国产大模型已经到了不能再被忽视的阶段。
5.Llama3-V 作者正式道歉,网友各持己见

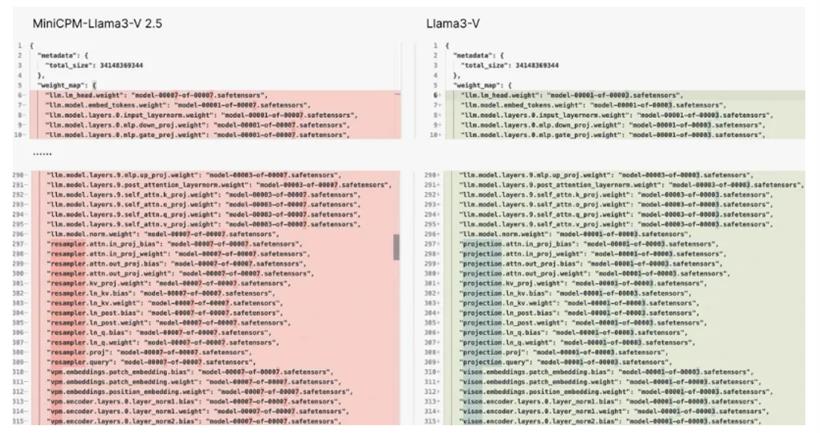
但有媒体向面壁智能官方求证,在 HuggingFace 中,MiniCPM-V2 与 MiniCPM-Llama3-V 2.5 分词器分别是两个文件,文件大小也完全不同。更何况,MiniCPM-Llama3-V 2.5 的分词器是用 Llama3 分词器加上 MiniCPM-V 系列模型的特殊 token 组成。考虑到 MiniCPM-V2 的发布时间早于 Llama3,理论上它不可能包含尚未公开的 Llama3 分词器技术。
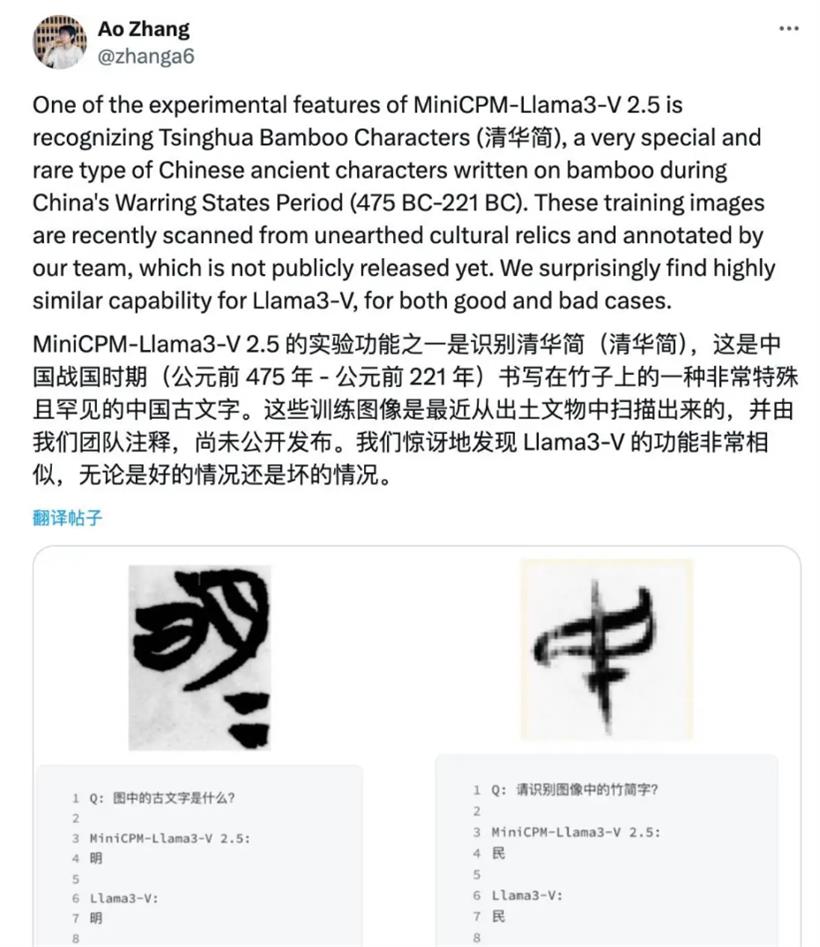
要知道这一古文字数据,是面壁智能和清华大学自然语言处理实验室团队花费数月时间,从清华大学收藏的清华简上逐字扫描并人工标注得来,从未对外公开过。那斯坦福 AI 团队是如何凭空获得呢?可以说,面壁智能的连番声明算是彻底实锤了斯坦福 AI 研究团队的抄袭。直到今天凌晨,斯坦福 Llama3-V 团队的两位作者 Siddharth Sharma 和 Aksh Garg 在社交平台 X 上就这一学术不端行为向面壁 MiniCPM 团队正式道歉, 表示 Llama3-V 模型将悉数撤下。
此事之所以在网络上激起千层浪,一个重要的原因在于抄袭作者的背景实在光鲜。公开信息显示,Siddharth Sharma 与 Aksh Garg 均是斯坦福大学计算机系的本科生,曾发表过机器学习领域的相关论文。其中,Siddharth Sharma 曾在亚马逊实习过一段时间,目前主要从事于 AI 和数据相关工作。而 Aksh Garg 的实习履历,那叫一个丰富,涵盖 SpaceX、斯坦福大学和加州理工学校等知名企业机构。

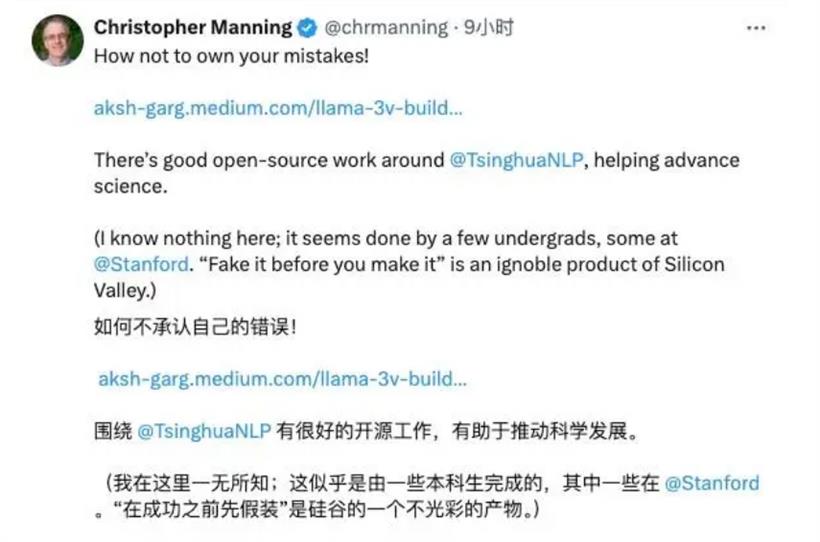
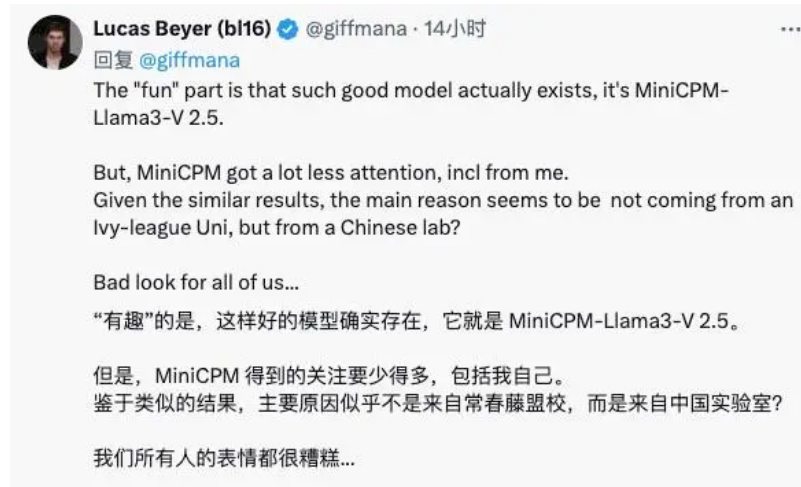

面壁智能首席科学家刘知远也在知乎上发文表示,表示这次事件从另一个角度证明了中国创新成果的国际影响力,强调了开源共享的重要性,以及对原创精神的尊重。
不得不说,这出 AI 圈的抄袭大戏,教科书般地诠释了叫「创新不易,且行且珍惜,学术诚信,人人有责」。要知道,模仿了代码的形,却抄不来那份原创的风姿卓绝。事实上,自去年以来,中国大模型如同雨后春笋般陆续开源,从以往的受益者转变为贡献者,不吝于向世界提供更多开源的优异成果。上至阿里巴巴、腾讯等巨头,下至面壁智能,智谱 AI 、昆仑天工等 AI 初创,也都是开源社区的积极分子,为中国大模型的发展添砖加瓦。





