今年早些时候,外媒曝光了微软与OpenAI的一项“疯狂计划”:斥资千亿美金,定制一个史无前例的数据中心。然而,面对这一重大利好,英伟达却心情复杂:爆料显示,OpenAI拒绝使用英伟达的InfiniBand网络设备,转而投奔以太网的阵营。众所周知,一个数据中心往往有数千甚至上万台服务器;而连通这些服务器的,正是以InfiniBand和以太网为代表的网络互联技术。
英伟达是InfiniBand路线的主要玩家,独家提供了相关的交换机、电缆等硬件设备;其余的科技公司,则扎堆在以太网赛道。OpenAI的“反水”,对英伟达而言是个巨大噩耗。要知道,InfiniBand与以太网,彼此已互相竞争多年。InfiniBand曾一度遥遥领先:2015年时,超级计算机Top500榜单中,超半数的上榜者都在使用InfiniBand。但在当下,随着大客户陆续倒戈,InfiniBand正在输掉比赛。
去年7月,AMD、微软等9家硅谷大厂联手成立了超以太网联盟(UEC),准备彻底击溃InfiniBand。今年一季度,英伟达的InfiniBand网络设备收入,出现了环比下降。与数据中心等一路狂飙的业务相比,显得格外突出。
那么问题来了:
1.英伟达的“亲儿子”InfiniBand,为何会处于劣势?
2.对于英伟达而言,互联为何是场不能失败的竞赛?
派别之争
InfiniBand的初衷,是为了解决当前算力最大的瓶颈——传输速度。两台服务器连接在一起,“1+1”所实现的算力必定会“小于2”,因为数据传输速度远远小于服务器的算力。可以把每台服务器,想象成一座拥有一万辆卡车的小城镇;受制于客观环境,每天只能往隔壁城镇运输200卡车的货物。数据中心则是由上千个小镇构成的王国。小镇与小镇之间的运输问题,会严重拖累整个王国的发展。
而限制传输速度的罪魁祸首,是落后的网络协议。所谓网络协议,可以简单理解为一种“交通规则”。计算机之间的信息传输,都沿着这一“交通规则”有序进行。最初的交通规则 ,是一种名为TCP/IP的网络协议。这项交通规则,有个明显缺陷:数据在传输时,需要经过CPU,极度占用CPU资源,导致延迟特别高。
相当于卡车运货的公路上,设有大批人工收费站。车子每开一段路,都要停下来掏出钱包缴费,造成了严重拥堵,运行效率可想而知。在这一大背景下,全新的RDMA网络协议(远程直接内存访问)应运而生。顾名思义,它可以绕过CPU,直接访问另一台服务器的内存。换句话说,新的交通规则,将高速公路上的人工收费站全撤走了,改设成ETC。
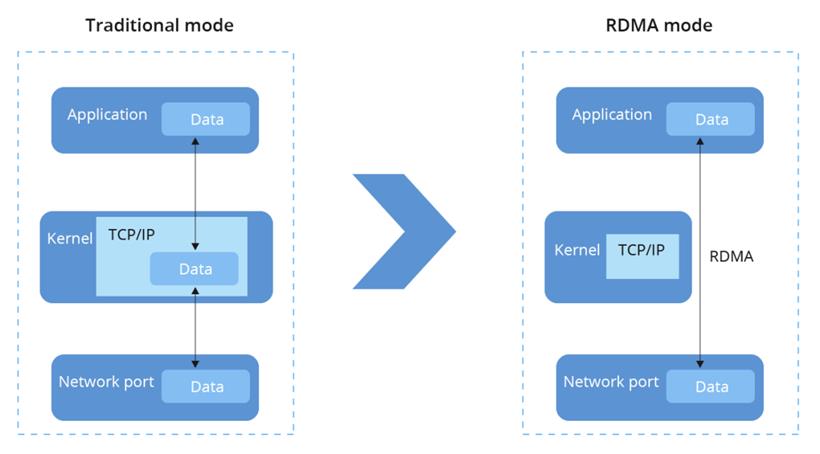
但基于RDMA网络协议,业界却衍生出了两个不同的实现方向:
一是“外部革新派”
基于RDMA全部推翻重来,重新构建一套网络协议,以实现极致的性能。其成果,正是英伟达的InfiniBand。全新的交通规则,使得数据传输可以同时绕过CPU与内存,相当于把ETC也撤了,直接通过GPU进行数据交互。InfiniBand(无限带宽)这个名字,正是其极致理念的一种体现。
二是“内部改良派”
一个热知识,以太网是最普及的局域网技术,几乎所有计算机系统都支持以太网设备。改良派的做法,正是利用RDMA网络协议,去改造以太网。由此可见,InfiniBand与以太网的竞争,本质是同一技术路线的派别之争。在算力供应严重不足的当下,大刀阔斧革新的InfiniBand,本应更加受到市场青睐。然而,各大硅谷巨头却“十动然拒”。不光是微软,Meta也选择全面拥抱以太网。InfiniBand之所以如此不受待见,问题恰恰出在革新过于激进了。
激进的代价
2019年,围绕以色列公司Mellanox,微软、英特尔、英伟达三家巨头展开了激烈的竞购。Mellanox是InfiniBand方案的唯一提供商,市值为22亿美金。为此,英特尔专门预留了60亿美金的现金流,本以为胜券在握;没想到英伟达更狠,以69亿美金的高价将Mellanox收入囊中。这是英伟达有史以来最贵的一笔收购。然而,老黄的梭哈,给英伟达带来了不菲的经济回报。
前文曾提到,InfiniBand只是一种“交通规则”;想要使用这项技术,还得搭配硬件。然而,由于InfiniBand的革新过于激进,重新设计了物理链路层、网络层、传输层,并不适配传统的硬件,需要更换整套基础设施,包括专门的交换机、网卡、电缆。这些配套网络设备,全部由英伟达独家提供。
相当于InfiniBand重新定义了一套更高效的交通规则,但并不适用于小镇原本的燃油卡车;为了提升送货效率,小镇还得向英伟达采购一批新能源卡车。由此可见,InfiniBand其实是一套“专用”方案。通过推广这一方案,英伟达可以大搞捆绑销售,向客户兜售专用的配套网络设施。因此,InfiniBand的使用成本一直很高。科技公司在建设数据中心时,需要掏出20%的开支用于InfiniBand;如果改成通用的以太网方案,只需要一半甚至更少的费用。
为了让科技公司用InfiniBand,老黄可谓用尽套路:例如英伟达同时售卖InfiniBand与以太网的网卡,两者的电路板设计完全相同,但以太网的交货时间明显更长。

英伟达的小算盘在于,虽然咱贵,但性能强啊。InfiniBand方案可以大大改善AI训练,早点把模型做出来投入市场,这钱不就赚回来了吗?然而,令英伟达尴尬的是,随着“内部改良派”阵营不断壮大,InfiniBand与以太网的性能差距被缩小了。2014年时,改良派的最新成果RoCE v2网络协议问世,改变了InfiniBand一枝独秀的局面。去年,英伟达面向InfiniBand与以太网,分别推出了一款交换机。尽管两者定位有所不同,但均能实现800Gb/s的端到端吞吐量。
当通用方案也能做到85分时,专用方案便开始失去魅力。5-10分的领先,很难让科技公司多付一倍的价钱。而去年7月成立的超以太网联盟,则打算在RoCE v2网络协议的基础上,面向大模型这一场景,开发一套新的以太网协议,全面超越InfiniBand。新的“反英伟达联盟”一呼百应。截至今年3月,包括字节跳动、阿里云、百度等国内科技公司,也加入了其中。
面对超以太网联盟的“正义群殴”,英伟达没有再负隅顽抗。过去一年,黄仁勋越来越少在公开场合提及InfiniBand。将来,InfiniBand与以太网之争或将渐渐划上句号。然而,英伟达并没有放弃互联这块蛋糕,转而将筹码押注到自家的Spectrum X以太网平台上。因为,互联正日渐成为大模型时代的兵家必争之地。
下一个战场
今年1月,美国咨询公司Dell'Oro Group发布了一份报告,当中提到:随着人工智能爆发,科技公司对通信互联的需求激增,从而带动交换机市场扩大50%。科技公司之所以对互联这么热情,是因为在过去一年的野蛮扩张中,渐渐触碰到了天花板。而以InfiniBand和以太网为代表的互联技术,正是打破瓶颈的关键。科技公司遇到的第一个问题,是算力开支过于昂贵。
英伟达的AI芯片,一向以昂贵著称:最新的B200芯片,单块起售价达到了3-4万美金。众所周知,大模型是一只喂不饱的“算力吞金兽”。为了满足日常使用,科技公司通常需要采购至少上千块AI芯片,这钱烧得比直接碎钞都快。如果自研芯片,同样也会遇到类似的问题。由于芯片制程迭代放缓,提升芯片算力上限,需要付出更多的成本。
然而,由于传输速度的限制,数据中心并没有发挥出芯片全部的算力。相比于硬着头皮堆芯片,提升数据传输速度,提高算力利用率,相对更具性价比一些。
第二个问题是功耗。随着数据中心越做越大,功耗也在直线上升。扎克伯格曾在采访中提到,近几年新建的数据中心,功耗已经达到了50-100兆瓦,稍大一点的已经达到了150兆瓦。按照这个趋势下去,300、500乃至1000兆瓦,都只是时间问题。然而,根据美国能源信息署的数据,在2022年夏天,硅谷所在的加州,总发电量为85981兆瓦。面对越来越多的“电力怪兽”,电网实在有些满头大汗。
为了训练GPT-6,微软与OpenAI曾搭建了一个由10万张H100组成的服务器集群,测试了一下发现当地电网直接罢工。目前,微软与OpenAI的解决方案,是“跨地区的分布式超大规模集群训练”。翻译成人话就是,将几十甚至上百万块AI芯片,分散在多个城市或者地区,再借助InfiniBand或者以太网,连成一个整体——互联又一次发挥了至关重要的作用。
如果说,大模型世界的准则,是大力出奇迹;那么互联的价值,就在于拔高大力出奇迹的物理上限,让scaling law的飞轮再转得久一些。在人工智能时代,互联注定将会是最重要的议题之一;而对英伟达,以及其他科技公司而言,这都是一场输不起的比赛。
尾声
在硅谷,英伟达越来越像只“恶龙”。在互联的领域,大半科技公司都站在了英伟达的对立面。至于GPU就更不必说,大厂自研芯片摆脱英伟达,早已是个公开的秘密。老黄这么不受待见,很大一个原因,是因为钱基本都被他赚去了。不论是InfiniBand,还是AI芯片,英伟达都几乎做到了垄断,拥有很强的议价权。相比之下,科技公司们扎堆大炼AI,却苦于没有成熟的商业模式。大家回头一看,发现只有一个皮衣男子赚得盆满钵满,难免心有不快。
所以,也不怪硅谷大厂们都开始“自力更生”了。毕竟,“穷”才是推动进步的原动力。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






