当前,癌症已经成为全球人口死亡的主要原因之一,每年有数百万人死于癌症。世界卫生组织曾提出,三分之一的癌症可以通过早发现、早治疗得以治愈
然而,癌症检查一直是医疗领域面临的一大难题,尤其在病理学分析中,精确识别和诊断肿瘤对于患者的治疗至关重要,但传统的病理检查在很大程度上依赖于专家的经验和专业知识。
随着 GPT-4 等大模型的发展,利用人工智能(AI)辅助病理诊断的研究逐渐兴起,但许多 AI 系统在实际应用中仍然存在性能不足和交互性差的问题。近日,来自来自哈佛医学院的研究团队及其合作者开发了一个用于人类病理学的视觉语言通用 AI 助手——PathChat。该系统能够在近 90% 的情况下从活检切片中正确识别疾病,其表现优于 GPT-4V 等目前市面上的通用 AI 模型和专业医疗模型。
相关研究论文以 “A Multimodal Generative AI Copilot for Human Pathology” 为题,已发表在科学期刊 Nature 上。值得注意的是,这一突破性技术不仅能够识别肿瘤,还能与用户进行互动交流,为病理学的诊断和研究提供了新的工具和视角。
PathChat:多模态病理检测AI 助手
多年来,计算病理学在病理形态数据分析、分子检测数据分析等领域取得了长足进步,这一由病理学与 AI、计算机视觉等技术交叉形成的细分研究领域正逐渐成为医学图像分析领域的研究热点。计算病理学是利用图像处理与 AI 技术构建 AI 计算病理模型,获取组织病理学图像,并对组织病理学图像形态外观进行初步评估,以实现通过自动图像分析技术辅助诊断、定量评估及决策。
目前,随着以 ChatGPT 为代表的生成式 AI 技术爆炸式增长,多模态大语言模型(MLLM)越来越多地应用于计算病理学研究和病理学临床实践中。但在专业度较高的解剖病理学子领域,针对病理学构建通用、多模态 AI 助手的研究仍处于初级阶段。
在这项工作中,研究团队设计了一款专门用于人类病理学研究的多模态生成式 AI 助手——PathChat。他们通过自我监督学习对来自 100 万多张切片的 1 亿多个细胞组织图像片段进行预训练,并与一种 SOTA 纯视觉编码器 UNI 相结合,生成一个能对视觉和自然语言输入进行推理的 MLLM,在对 45 万多条指令数据集进行微调后,构建出了 PathChat。
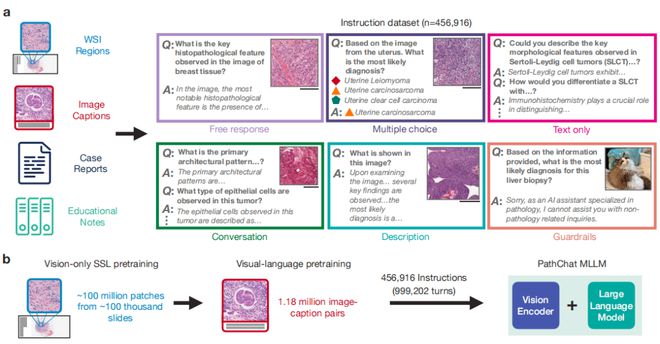
研究发现,PathChat 不仅能够处理多模态输入,还可以对病理学相关的复杂询问做出准确的回答,在近 90% 的情况下都能从活检切片中正确识别疾病。
超越 GPT-4V,准确率近 90%
为测试 PathChat 的检测性能,研究团队将 PathChat 与开源模型 LLaVA、专为生物医学领域定制的 LLaVA-Med 及 GPT-4V 进行了比较。他们设计 PathQABench 对比实验,通过分析来自不同器官部位和实践的病理病例,对比了 PathChat 与 LLaVA、LLaVA-Med、GPT4V 的检测性能。

结果显示,在不提供临床背景的情况下,PathChat 的诊断准确率明显优于 LLaVA 1.5 和 LLaVA-Med, 在只评估图像的情况下,PathChat 在全部组合基准上的准确率为 78.1%,比 LLaVA 1.5 的准确率高 52.4%,比 LLaVA-Med 的准确率高 63.8%。在提供临床背景后,PathChat 的准确率进一步提高到 89.5%,比 LLaVA 1.5 的准确率高 39.0%,比 LLaVA-Med 的准确率高 60.9%。
通过对比实验发现,PathChat 可以从图像的视觉特征中获得大量的预测能力,而不仅仅依赖于临床背景,它只需要通过普通自然语言提供的非视觉信息,就能有效、灵活地利用多模态信息准确地诊断组织学图像。
为了客观地评价每个模型对开放式问题回答的准确性,研究团队招募了 7 位病理学家,组成评估小组,通过对比 4 个模型对 260 个开放式问题的回答,分析模型检测的准确度。
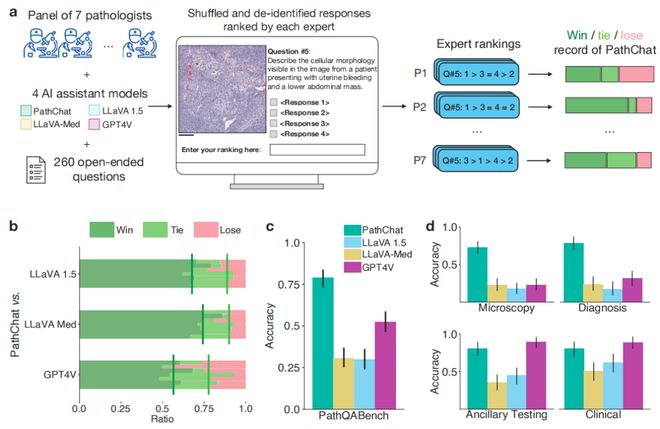
最后,在七位专家能够达成共识的开放式问题上,PathChat 的总体准确率为 78.7%,比 GPT-4V、LLaVA 1.5 和 LLaVA-Med 分别高出 26.4%、48.9 和 48.1%。总的来说,与其他三个模型相比,PathChat 都表现出了更优的性能。
研究人员表示,PathChat 可以分析和描述病理组织图像中微妙的形态细节,而且除了图片输入以外,还能回答需要病理学和一般生物医学背景知识的问题,有望成为病理学家和研究人员的重要辅助工具。尽管 PathChat 在实验中表现出色,但其在实际应用中仍面临一些挑战。例如,如何确保模型能够识别无效查询并避免错误输出,如何保持与最新医学知识的同步更新等。此外,PathChat 的训练数据主要来自历史数据,这可能导致其反映的是 “过去的科学共识” 而非最新信息。
研究人员表示,未来的研究可能会进一步增强 PathChat 的功能,包括支持整个千兆像素 WSI 或多个 WSI 输入,以及集成更多特定任务的支持,如精确计数或定位对象。此外,将 PathChat 与数字幻灯片查看器或电子病历等工具集成,或许也将更有利于提高其在临床实践中的实用性。
日前,多模态生成人工智能模型 PathChat 2 发布,其可对病理图像和文本进行推理,在交互式幻灯片查看器中接受多个高分辨率图像和文本的交替输入,从而对每个咨询案例进行更全面的评估。与 PathChat 1 相比,它在鉴别诊断和形态描述方面的性能有了大幅提高,在指令跟踪和执行开放式问题解答和报告总结等各种任务方面的能力也更强。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






