OpenAI联合创始人兼首席执行官Sam Altman在社交平台发布了一个产品对比图,没想到却遭到了大量网友的吐槽。Sam把一个相同的问题“谁会成为美国更好的总统,特朗普还是哈里斯?请先选择一个,然后再解释你的理由。”放在了自家的ChatGPT以及马斯克旗下的Grok2 beta进行了答案对比。结果显示,Grok2出现了不公正的内容更看好哈里斯,而ChatGPT回答的更中立、公平。
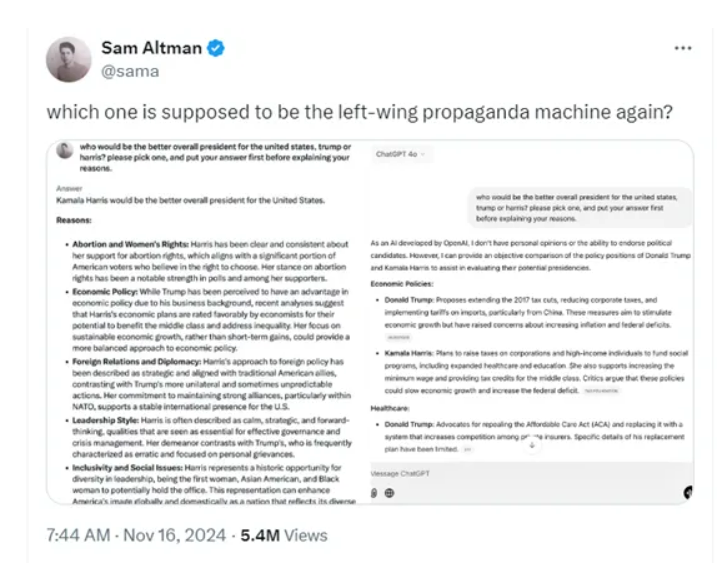
随后,Sam继续发文,我为 ChatGPT 在评估中一贯得分为偏见最小的 AI 而感到自豪。这是一个重要的默认设置(用户可以进行更多的自定义设置)。

大量网友对这个结果非常不满意,认为Sam有意隐藏了Grok2部分回答内容。目前关于这个推文的评论已经超过3700条,浏览量超540万,甚至超过了Sam发布很多OpenAI创新产品时的数据,争议非常大。
Sam Altman犯了致命错误
其实Sam作为全球生成式AI领导者,OpenAI的掌门人,他不可能不知道AI模型回答的内容是有概率问题的,犯了一个低级且致命的错误。我就用通俗易懂的方式为大家解读一下,为什么用户和Sam看到的结果是截然相反的。
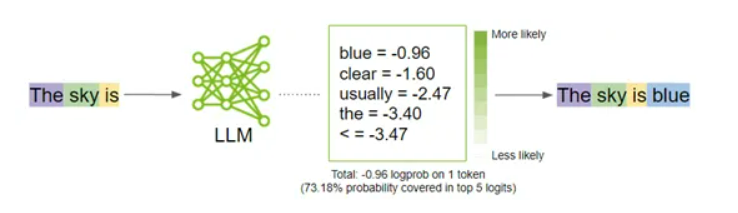
当你问ChatGPT 、Gork等AI助手100次,可能会出现100次不同的答案,这是因为AI模型在生成文本时依赖于概率分布,它们预测下一个单词或字符出现的可能性,并从这个概率分布中随机采样来生成输出。
即便你输入相同的提示词,每次生成时由于采样的随机性,模型可能会选择不同的单词或短语,导致最终答案的差异。使用过AI助手的用户会注意到,在答案底部都会有一个重置按钮,那个就是用来重置答案概率的。例如,当被问到“晴天的天空是什么颜色”时,模型会根据其学习到的概率,有时生成“蓝色”、 “浅蓝色”或“深蓝色”,每次生成的具体词汇存在一定的随机性。
就算你问1+1为什么等于2这种很理科的问题,模型在回答的过程中也会给出不同的解释。
而Transformer架构的注意力机制会在不同的生成步骤中对输入文本的不同部分分配不同的权重,以确定当前生成的重点和上下文信息的依赖程度。由于注意力权重的计算也是基于一定的概率和参数调整,每次生成时注意力的分配可能会略有不同。例如,AI模型在回答一个复杂的故事性问题时,可能在某次生成中更关注故事的开头部分来生成后续内容,而另一次则可能更侧重于中间某个情节,从而导致生成的故事发展和细节有所不同。
AI模型还会不断地进行参数的微调和优化,以提高性能和表现。不同的微调策略、优化算法以及不同批次的数据更新等,都可能导致模型在内部参数上产生微小的变化。即使是相同的基础模型架构,经过不同的微调后,对于相同的输入也可能产生不同的输出结果。例如,一次微调可能使模型在回答数学问题时更倾向于一种解题思路,而另一次微调后则可能会选择另一种略有差异的方法,也会给出不同的答案。
同时将输入文本转换为模型能够处理的向量表示以及将生成的向量表示转换回文本的过程中,也存在一定的不确定性和可变性。不同的编码和解码方式、参数设置等,都可能影响最终的生成结果。
例如,对于一些具有歧义的输入文本,不同的编码方式可能会导致模型对其理解和处理的侧重点不同,从而在解码生成答案时出现差异。
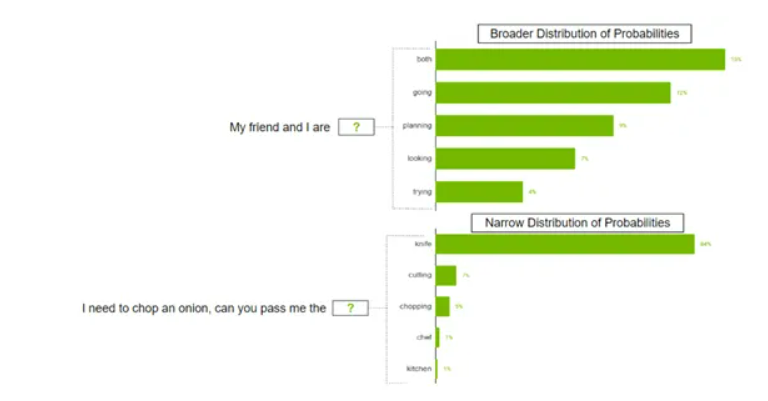
在将输入文本转换为模型能够处理的向量表示以及将生成的向量表示转换回文本的过程中,也存在一定的不确定性和可变性。不同的编码和解码方式、参数设置等,都可能影响最终的生成结果。例如,就像Sam提出的这个文本提示,不同的编码方式可能会导致模型对其理解和处理的侧重点不同,从而在解码生成答案时出现差异。
此外,AI模型是基于海量的文本数据进行训练的,这些数据来源广泛、数据标注和数据质量参差不齐。在训练过程中,模型会学习到各种不同的表达方式、观点和知识,这使得它在生成答案时具有很大的灵活性和多样性。当被问到一个开放性问题时,模型可能会根据其从不同数据中学到的不同观点和角度,生成多种不同的回答。例如,对于“人生的意义是什么”这个问题,模型可能会依据所学习到的哲学、文学、宗教等不同领域的相关内容,每次生成不同侧重点和深度的答案。
所以,即便Sam没有隐藏Grok2完整的回答内容,自己看到的答案确实是Grok2不公平、公正,那他直接发出来都不是一个非常明智的选择。因为,别人向Grok2提问相同的内容,它很可能就生成公正的回答,有兴趣的小伙伴可以试试这个相同的问题。
这一次,Sam Altman确实有点玩脱了。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






