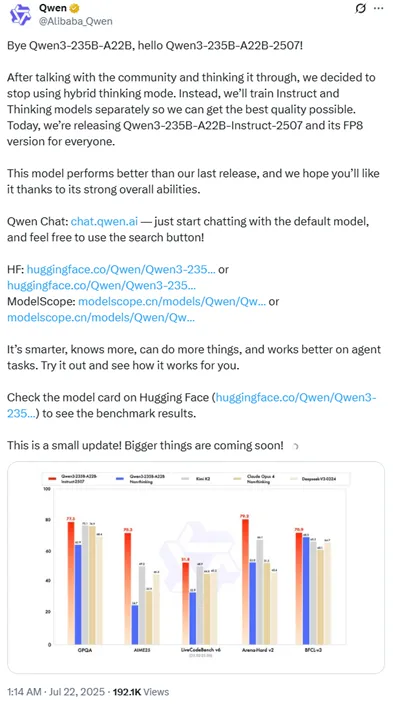
今天凌晨1点,阿里巴巴开源了Qwen3系列新版本Qwen3-235B-A22B-2507。比较意外的是,阿里已经停用了混合思考模型,新版Qwen3是一个非思维推理,又回到了指令微调模型,但性能非常强劲。根据阿里公布的数据显示,新版Qwen3在知识、推理、代码、对齐、智能体、多语言测试6大类几十种测试基准中,全部大幅度超过了DeepSeek开源的新版V3-0324模型。
例如,SimpleQA测试中,DeepSeekV3得27.2分,新版Qwen3为54.3分;CSimpleQA测试中,DeepSeekV3得71.1分,新版Qwen3为84.3分;
ZebraLogic测试中,DeepSeekV3 83.4分,新版Qwen3为95分;WritingBench测试,DeepSeekV3 74.5分,新版Qwen3为85.2分;TAU-Airline测试中,DeepSeekV3为32.0分,新版Qwen344.0分;PolyMATH测试,DeepSeekV3为32.2分,新版Qwen350.2分。
同样新版Qwen3也超过了月之暗面最新开源的kimi-k2。
开源地址:
https://huggingface.co/Qwen/Qwen3-235B-A22B-Instruct-2507
https://modelscope.cn/models/Qwen/Qwen3-235B-A22B-Instruct-2507
新版Qwen3总共有2350亿个参数,其中220亿个是激活的。非嵌入参数数量为2340亿,共有94层,采用64个查询头和4个键值头的分组查询注意力机制。它有128个专家,其中8个是激活的。其上下文长度原生支持262144。
新版Qwen3是在指令遵循、逻辑推理、文本理解、数学、科学、编程和工具使用等通用能力进行了大量优化。还在多种语言的长尾知识覆盖方面取得了显著进步,并且在主观和开放性任务中与用户偏好的对齐度更高,能够生成更有帮助且质量更高的文本,同时增强了对256K长文本上下文的理解能力。
在性能方面,Qwen3-235B-A22B-Instruct-2507在多个基准测试中表现优异。例如,在知识类的MMLU-Pro测试中得分为83.0,在MMLU-Redux中得分为93.1,在GPQA中得分为77.5。在推理能力方面,它在AIME25测试中得分为70.3,在HMMT25中得分为55.4。

在编程能力方面,它在LiveCodeBenchv6测试中得分为51.8,在MultiPL-E中得分为87.9。在对齐能力方面,它在IFEval测试中得分为88.7,在Arena-Hardv2测试中得分为79.2。此外,它在多语言能力方面也有出色的表现,例如在MultiIF测试中得分为77.5,在MMLU-ProX测试中得分为79.4。
此外,Qwen3 在工具调用能力方面表现出色,建议使用 Qwen-Agent 来充分发挥其智能体能力。Qwen-Agent 内部封装了工具调用模板和工具调用解析器,大大降低了编码复杂性。可以通过MCP配置文件、Qwen-Agent 的集成工具或自行集成其他工具来定义可用工具。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






