据《Decrypt》报道,芝加哥大学 SIGMA 实验室推出了一项名为「Prophet Arena」的新基准测试,旨在评估 AI 模型预测现实事件的能力。研究显示,AI 模型在预测未决事件方面已达到与预测市场相当的准确度,甚至在部分场景中表现更佳。
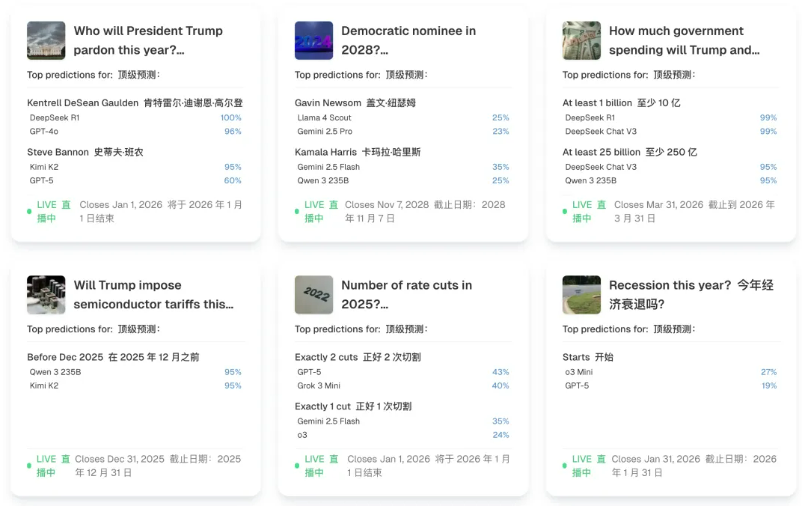
「Prophet Arena」通过测试 AI 对选举结果、体育赛事及经济指标等未决事件的预测能力,与传统基准测试使用历史数据不同,该平台专注于未来事件预测。它主要是从国外 Kalshi 等预测市场中精选任务,涵盖政治、经济、体育等多个领域,来确保任务的多样性和实时性。
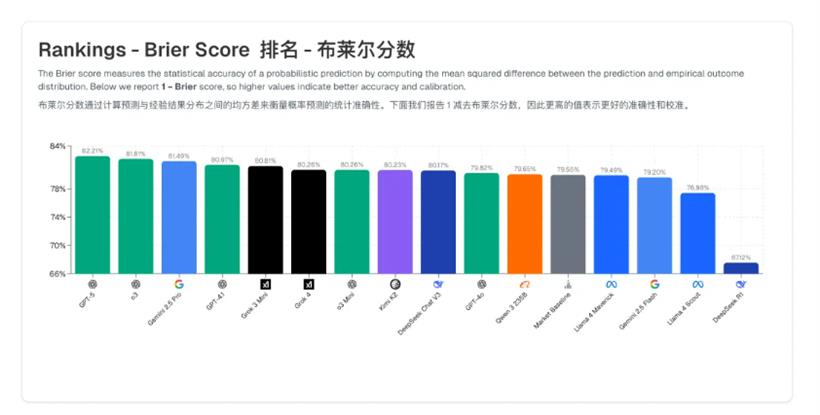
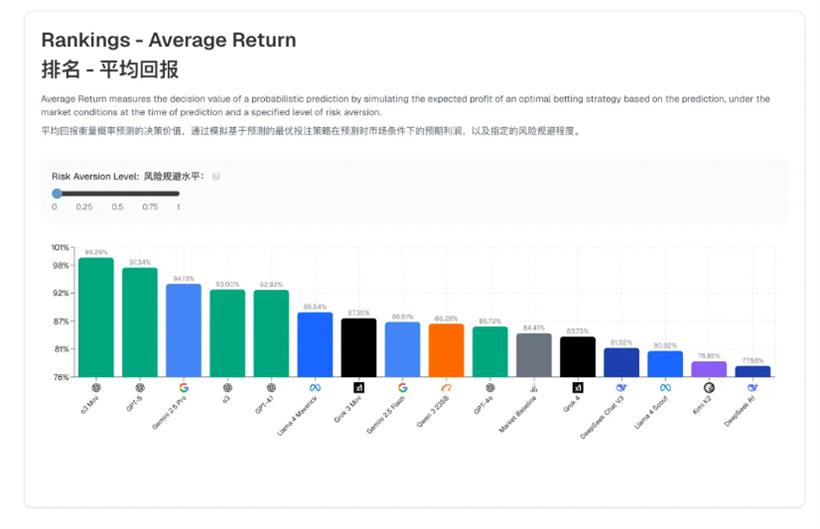
GPT-5 目前在这一榜单中表现领先,Brier 评分(概率类模型评估指标)达到 82.21%。此外,OpenAI 的 o3-mini 模型在模拟投资中创造了最高回报,显示出 AI 预测的潜在商业价值。
研究还揭示了 AI 模型的独特预测「个性」。例如,当预测 AI 监管法律是否将在 2026 年前成为联邦法律时,市场仅给出 25% 的概率,而不同模型预测结果差异巨大:Qwen 3 为 75%,GPT-4.1 为 60%,而 Llama 4 Maverick 则仅为 35%。这种分歧也表明 AI 模型在信息处理与逻辑推理方面的多样性。
不过,目前芝加哥大学提出的 Prophet Arena 预测竞技场还是作为一个实验室项目,测试标准还没有得到行业普遍认可,不同模型因为发布时间导致样本不同,其结果适用性还有待观察。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






