微软研究院开源了一款AI Agent推理模型rStar2-Agent。该模型使用了创新的智能体强化学习方法,只有140亿参数,但在AIME24数学推理测试中达到了80.6%准确率,超过了拥有6710亿参数的DeepSeek-R1的79.8%。而二者的参数体量却相差了将近48倍。除了在数学推理任务中的出色表现,rStar2-Agent在其他领域展现了强大的泛化能力。例如,在GPQA-Diamond科学推理基准测试中,其准确率达到了60.9%,也超过了DeepSeek-V3的59.1%;在BFCL v3智能体工具使用任务中,其任务完成率达到了60.8%,超过了V3的57.6%,在智能体工具调用方面更出色。

开源地址:
https://github.com/microsoft/rStar
OpenAI的O系列、DeepSeek-R1、V3等领先模型,通过延长推理链,就是让大模型思考时间更长大幅提升了性能。但这种方法在面对一些难题时存在局限性,因为容易在中间步骤出现细微错误,或者需要创造性地转变推理方向。在这种情况下,模型依赖于内部自我反思来检测和纠正错误往往效果不佳。为了解决该难题,微软决定转向智能体强化学习并实现三大技术突破。在这种学习范式下,模型与特定的工具环境进行交互,并根据从环境中获得的反馈来调整推理过程。选择合适的工具和环境至关重要,一个有效的环境必须能够部署,并且提供准确、可验证的信号,引导模型走向更强的推理路径。
训练基础突破
首先是在训练基础设施方面实现了重大突破。智能体强化学习需要高效的工具环境,可传统的本地Python解释器在面对大规模训练时问题重重。例如,模型训练就像是一个繁忙的工厂,需要大量的原材料(代码执行请求)供应。以往的本地Python解释器就如同一个低效的仓库管理员,面对工厂瞬间涌入的数万份原材料需求,不仅处理速度慢,还可能因为各种问题,让整个工厂陷入混乱,甚至威胁到整个生产系统的安全。
微软打造的全新基础设施则截然不同。其中的隔离式高吞吐代码执行服务,就像是一个超级高效的大型物流中心。它部署在由64台AMDMI300XGPU组成的强大硬件基地上,采用“主节点-工作节点”的分布式架构。
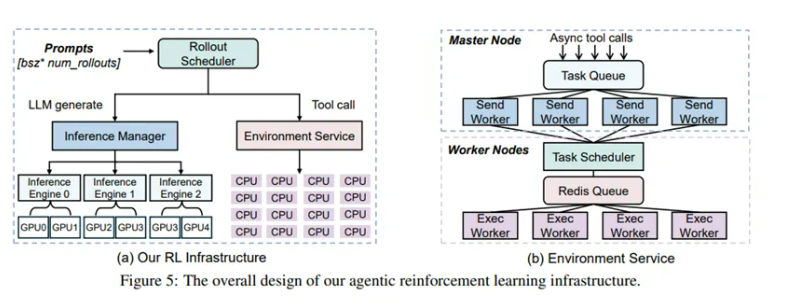
主节点如同物流中心的总调度室,有集中式任务队列和32个发送工作器,负责接收来自工厂的原材料需求,然后将最多64个工具调用打包成一个批次,快速分配任务,就像调度室快速安排货物配送路线一样,利用超时机制保证配送效率。而工作节点就像是一个个忙碌的仓库区域,每个工作节点上运行着轻量级任务调度器与1024个执行工作器,它们能迅速将任务分配到空闲的执行单元,实现负载均衡,就如同仓库工作人员迅速将货物搬运到空闲的存储区域。
实验数据显示,这个物流中心非常强大,能稳定支撑每训练步骤4.5万次并发工具调用,平均执行延迟仅0.3秒,而且通过巧妙的隔离设计,完全避免了代码执行干扰主训练流程,保障了工厂的稳定生产。还有动态负载均衡滚出调度器,它的出现解决了传统调度方式的一大难题。传统的静态分配方式,就像是不管每个仓库区域(GPU)的实际存储能力,都平均分配货物,这样会导致大量仓库空间闲置。
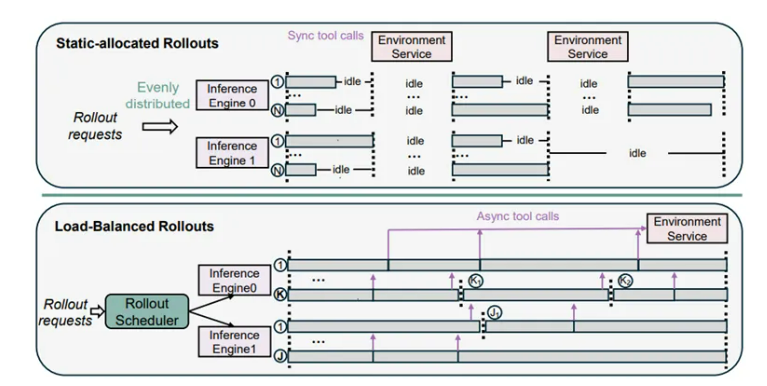
而动态负载均衡滚出调度器,就像是一个智能的仓库空间管理员,它会实时监控每个GPU的KV缓存剩余容量,根据这个来动态分配任务。当有新的任务进来时,它会估算每个仓库区域能安全存放的最大货物量,然后异步分发工具调用,就像及时将货物送到合适的仓库区域。
当某个GPU完成当前任务释放缓存后,它又能马上分配新任务,让仓库的空间利用率大大提高。经过测试,它将GPU空闲时间降低了60%以上,单批次滚出效率提升了45%,大大缩短了整个生产周期。
算法突破
在智能体强化学习中,环境噪声就像学习过程中的“捣乱分子”。例如,老师在教学生做数学题,给了学生一个不太靠谱的计算器。学生不仅要努力解题,还要应对这个捣乱的计算器给出的错误反馈,这就导致学生花费大量时间去修正计算器的错误,而不是真正推进解题思路。并且传统的基于最终结果的奖励机制,就像只要学生最后答案对了,不管中间用计算器过程多混乱,都给满分,这会让学生养成不好的解题习惯,认为错误的中间过程也没关系。
微软在GRPO算法基础上,提出了融合Resample-on-Correct(RoC)滚出策略的GRPO-RoC算法。GRPO原本是适用于推理任务的强化学习算法,rStar2-Agent对它进行了三项关键调整。移除KL散度惩罚项,就像是给学生松绑,让他们能大胆尝试新的解题方法,不再被旧规则束缚,去探索工具辅助的新推理模式;

采用Clip-Higher策略,提升重要性采样比率上界,这就像鼓励学生多去尝试那些虽然不常见但可能很关键的解题思路,例如,在解题时想到用特殊方法去验证答案;取消熵损失项,防止训练像脱缰的野马一样失控,避免了训练过程中可能出现的混乱情况。RoC采用“过采样-筛选-下采样”的不对称采样机制,就像是对学生的解题过程进行严格筛选。为每个问题生成很多解答尝试,然后进行筛选。对于失败的尝试,就像保留一些错误案例给学生看,让他们知道哪些做法是不对的;
对于成功的尝试,就像老师严格检查学生的解题过程,只保留那些工具调用错误最少、代码简洁、推理清晰的高质量解答。经过这个策略筛选,正奖励轨迹中的工具错误率从15%降至5%以下,同时推理响应长度缩短了30%,让模型的推理过程更加高效、准确。
训练流程突破
最后是训练流程的创新。在大模型强化学习领域,算力成本一直是个大难题,就像建造一座超级大楼,需要耗费巨额资金。很多模型,比如DeepSeek-R1、MiMo等,它们的训练就像建造非常复杂的大楼,需要数千甚至数万步的漫长过程,而且还依赖大规模推理微调预热。rStar2-Agent则另辟蹊径,设计了“非推理微调+多阶段强化学习”的高效训练流程。在非推理微调阶段,它不像传统模型那样一上来就在强化学习前进行大量“推理导向微调”,而是专注于培养模型的三项基础能力,就像教孩子先学会走路、说话和基本的生活技能。它采用Tulu3数据集的3万条指令示例,教模型学会听从指令,就像教孩子听老师的话;
整合16.5万条函数调用数据,将工具调用格式统一为结构化JSON格式,就像给孩子的玩具都规定好摆放方式;引入LLaMA-Nemontron数据集的2.7万条对话数据,提升模型的对话能力,就像锻炼孩子的交流能力。经过这个阶段微调,模型在MATH-500基准测试中虽然整体得分可能不如基础模型,但工具调用准确率大幅提升,指令遵循达标率也不错,为后续强化学习打下了良好基础。
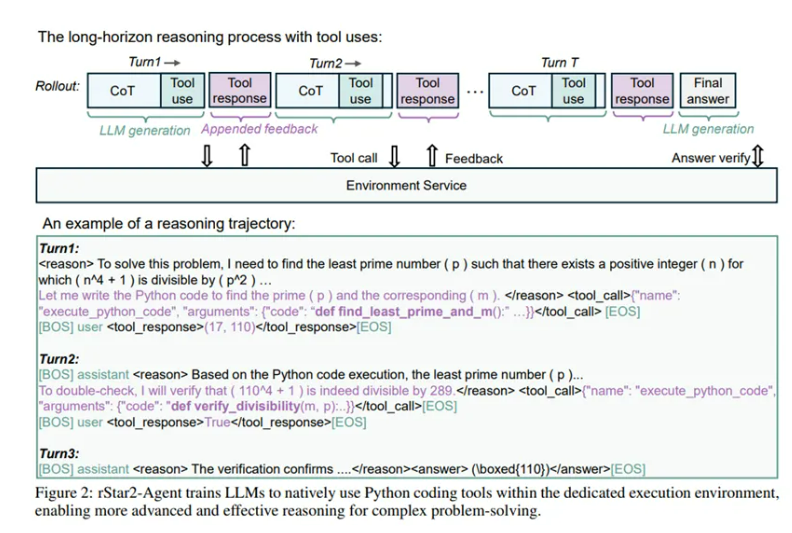
多阶段强化学习分为三个阶段:第一阶段,在8Ktoken长度限制下,使用4.2万条高质量数学问题训练,这就像给孩子一些难度适中的数学题,让他们在有限的条件下锻炼解题能力。模型在这个阶段建立起“工具辅助推理”的基本模式,在AIME24、AIME25等测试中的准确率显著提升。当第一阶段末期,就像孩子在这个难度关卡基本熟练了,滚出截断率稳定在10%,进入第二阶段,将最大响应长度提升至12K token,给孩子更复杂的题目,进一步释放模型的复杂推理能力,相关测试准确率继续上升。
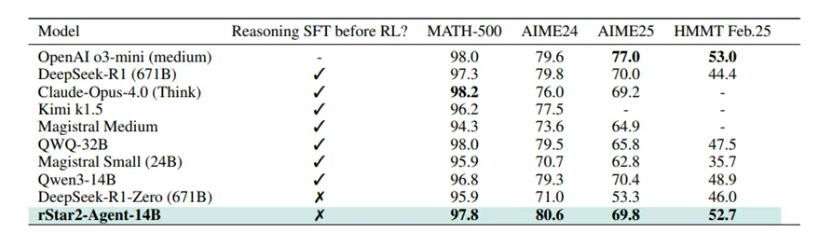
第三阶段,从1.73万条高难度问题中进行训练,就像给孩子最难的奥数题,模型在AIME24准确率突破80%,AIME25达69.8%,完成性能登顶。整个训练流程仅用64台MI300XGPU,在1周内完成510步强化学习迭代就达到性能峰值,大大降低了算力成本。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






