

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

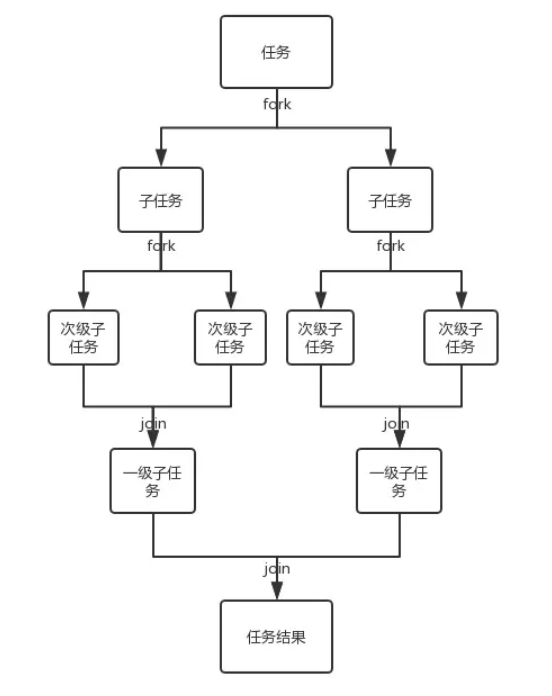
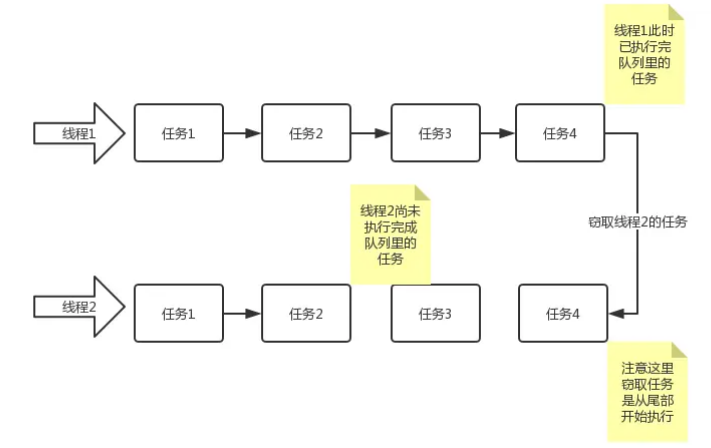
值得注意的是,当一个线程窃取另一个线程的时候,为了减少两个任务线程之间的竞争,我们通常使用双端队列来存储任务。被窃取的任务线程都从双端队列的头部拿任务执行,而窃取其他任务的线程从双端队列的尾部执行任务。另外,当一个线程在窃取任务时要是没有其他可用的任务了,这个线程会进入阻塞状态以等待再次“工作”。
public final ForkJoinTask<V> fork() {
Thread t;
// ForkJoinWorkerThread是执行ForkJoinTask的专有线程,由ForkJoinPool管理
// 先判断当前线程是否是ForkJoin专有线程,如果是,则将任务push到当前线程所负责的队列里去
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)
((ForkJoinWorkerThread)t).workQueue.push(this);
else
// 如果不是则将线程加入队列
// 没有显式创建ForkJoinPool的时候走这里,提交任务到默认的common线程池中
ForkJoinPool.common.externalPush(this);
return this;
}
其实fork()只做了一件事,那就是把任务推入当前工作线程的工作队列里。public final V join() {
int s;
// doJoin()方法来获取当前任务的执行状态
if ((s = doJoin() & DONE_MASK) != NORMAL)
// 任务异常,抛出异常
reportException(s);
// 任务正常完成,获取返回值
return getRawResult();
}
/**
* doJoin()方法用来返回当前任务的执行状态
**/
private int doJoin() {
int s; Thread t; ForkJoinWorkerThread wt; ForkJoinPool.WorkQueue w;
// 先判断任务是否执行完毕,执行完毕直接返回结果(执行状态)
return (s = status) < 0 ? s :
// 如果没有执行完毕,先判断是否是ForkJoinWorkThread线程
((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) ?
// 如果是,先判断任务是否处于工作队列顶端(意味着下一个就执行它)
// tryUnpush()方法判断任务是否处于当前工作队列顶端,是返回true
// doExec()方法执行任务
(w = (wt = (ForkJoinWorkerThread)t).workQueue).
// 如果是处于顶端并且任务执行完毕,返回结果
tryUnpush(this) && (s = doExec()) < 0 ? s :
// 如果不在顶端或者在顶端却没未执行完毕,那就调用awitJoin()执行任务
// awaitJoin():使用自旋使任务执行完成,返回结果
wt.pool.awaitJoin(w, this, 0L) :
// 如果不是ForkJoinWorkThread线程,执行externalAwaitDone()返回任务结果
externalAwaitDone();
}
我们在之前介绍过说Thread.join()会使线程阻塞,而ForkJoinPool.join()会使线程免于阻塞,下面是ForkJoinPool.join()的流程图: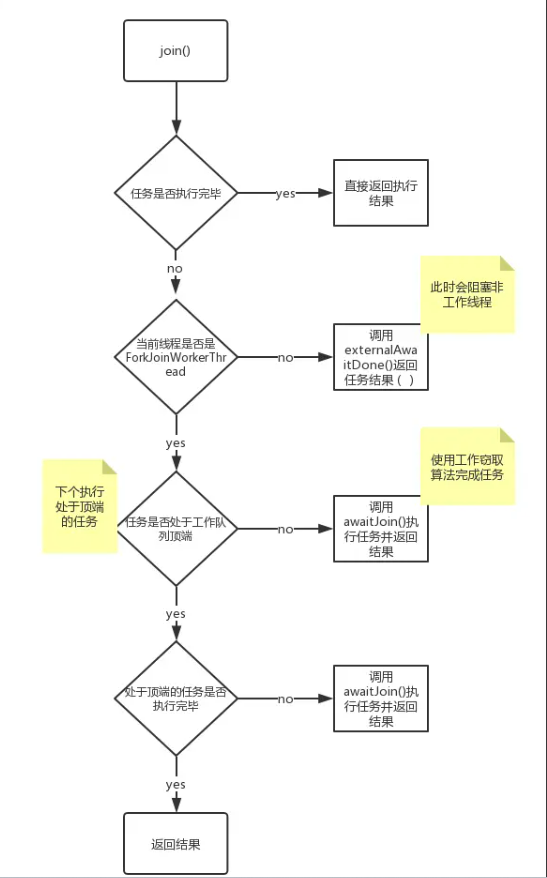
通常情况下,在创建任务的时候我们一般不直接继承ForkJoinTask,而是继承它的子类RecursiveAction和RecursiveTask。两个都是ForkJoinTask的子类,RecursiveAction可以看做是无返回值的ForkJoinTask,RecursiveTask是有返回值的ForkJoinTask。此外,两个子类都有执行主要计算的方法compute(),当然,RecursiveAction的compute()返回void,RecursiveTask的compute()有具体的返回值。
@sun.misc.Contended
public class ForkJoinPool extends AbstractExecutorService {
// 堆代码 duidaima.com
// 任务队列
volatile WorkQueue[] workQueues;
// 线程的运行状态
volatile int runState;
// 创建ForkJoinWorkerThread的默认工厂,可以通过构造函数重写
public static final ForkJoinWorkerThreadFactory defaultForkJoinWorkerThreadFactory;
// 公用的线程池,其运行状态不受shutdown()和shutdownNow()的影响
static final ForkJoinPool common;
// 私有构造方法,没有任何安全检查和参数校验,由makeCommonPool直接调用
// 其他构造方法都是源自于此方法
// parallelism: 并行度,
// 默认调用java.lang.Runtime.availableProcessors() 方法返回可用处理器的数量
private ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory, // 工作线程工厂
UncaughtExceptionHandler handler, // 拒绝任务的handler
int mode, // 同步模式
String workerNamePrefix) { // 线程名prefix
this.workerNamePrefix = workerNamePrefix;
this.factory = factory;
this.ueh = handler;
this.config = (parallelism & SMASK) | mode;
long np = (long)(-parallelism); // offset ctl counts
this.ctl = ((np << AC_SHIFT) & AC_MASK) | ((np << TC_SHIFT) & TC_MASK);
}
}
WorkQueue:双端队列,ForkJoinTask存放在这里。当工作线程在处理自己的工作队列时,会从队列首取任务来执行(FIFO);如果是窃取其他队列的任务时,窃取的任务位于所属任务队列的队尾(LIFO)。ForkJoinPool与传统线程池最显著的区别就是它维护了一个工作队列数组(volatile WorkQueue[] workQueues,ForkJoinPool中的每个工作线程都维护着一个工作队列)。
public class FibonacciTest {
class Fibonacci extends RecursiveTask<Integer> {
int n;
public Fibonacci(int n) {
this.n = n;
}
// 主要的实现逻辑都在compute()里
@Override
protected Integer compute() {
// 这里先假设 n >= 0
if (n <= 1) {
return n;
} else {
// f(n-1)
Fibonacci f1 = new Fibonacci(n - 1);
f1.fork();
// f(n-2)
Fibonacci f2 = new Fibonacci(n - 2);
f2.fork();
// f(n) = f(n-1) + f(n-2)
return f1.join() + f2.join();
}
}
}
@Test
public void testFib() throws ExecutionException, InterruptedException {
ForkJoinPool forkJoinPool = new ForkJoinPool();
System.out.println("CPU核数:" + Runtime.getRuntime().availableProcessors());
long start = System.currentTimeMillis();
Fibonacci fibonacci = new Fibonacci(40);
Future<Integer> future = forkJoinPool.submit(fibonacci);
System.out.println(future.get());
long end = System.currentTimeMillis();
System.out.println(String.format("耗时:%d millis", end - start));
}
}
上面例子的输出:CPU核数:4 计算结果:102334155 耗时:9490 ms需要注意的是,上述计算时间复杂度为O(2^n),随着n的增长计算效率会越来越低,这也是上面的例子中n不敢取太大的原因。




