随着互联网应用的不断发展和用户量的不断增加,传统的数据库在应对高并发和大数据量的场景下面临着巨大的挑战。为了解决这一问题,分库分表成为了一个非常流行的方案。分库分表主流的技术包括MyCat和Sharding JDBC。我们来通过一张图来了解这两者有什么区别:
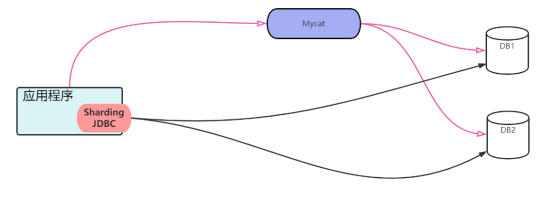
从上图可以看到,MyCat是一个单独的中间件,读者朋友们可以把它理解为一个数据库(不过它不是数据库哦,只是对于应用端来说连接使用MyCat和数据库是一样的,对应用程序来说,不需要关心具体是数据库还是MyCat;而Sharding JDBC则是整合到应用端的,它运行在应用端,和代码的耦合性相对MyCat来说要更高)。本文笔者将深入探索Sharding JDBC,介绍其核心概念、工作原理以及使用方法,并通过一个示例帮助读者更好地理解和应用Sharding JDBC。
一. 什么是Sharding JDBC?
Sharding JDBC是一款基于Java的开源中间件,用于简化分库分表的操作和管理。它提供了一套统一的接口和封装,屏蔽了底层数据库的细节,让开发者可以像使用单一数据库一样操作分布式数据库。
二. Sharding JDBC的核心概念
2.1 数据库切片(Sharding)
数据库切片是指将一个大型数据库按照某种规则拆分成多个较小的数据库实例,每个数据库实例称为一个切片。切片可以根据不同的规则进行拆分,如按照用户ID、地域等进行划分。
2.2 分布式表(Sharding Table)
分布式表是指将一个表按照某种规则拆分成多个子表,每个子表存储了相同表结构的不同数据。通常,分布式表的拆分规则与数据库切片的规则相一致。
2.3 数据库路由(Database Sharding)
数据库路由是指根据某种规则将数据库的操作路由到对应的数据库切片上。Sharding JDBC提供了路由策略的配置,可以根据业务需求进行灵活的配置。
2.4 表路由(Table Sharding)
表路由是指根据某种规则将数据操作路由到对应的分布式表上。Sharding JDBC同样提供了灵活的表路由策略配置,支持多种分表策略。
三. Sharding JDBC的工作原理
简单来说,Sharding JDBC的工作原理可以概括为以下几个步骤:
1.客户端发起数据库操作请求。
2.Sharding JDBC根据路由策略解析请求,确定对应的数据库切片和分布式表。
3.Sharding JDBC将请求转发给对应的数据库切片和分布式表。
4.数据库切片和分布式表执行具体的数据库操作。
5.结果返回给Sharding JDBC,再由Sharding JDBC返回给客户端。
Sharding JDBC通过对数据库操作的解析和转发,实现了透明的分库分表功能,对上层应用透明,使得应用无需关心分布式数据库的复杂性。
四. 如何使用Sharding JDBC?
接下来,我们一起来看下如何使用。使用Sharding JDBC可以分为以下几个步骤:
4.1 引入Sharding JDBC依赖
在项目的pom.xml文件中引入Sharding JDBC的相关依赖,以及对应的数据库驱动依赖。
4.2 配置数据源和数据库规则
在配置文件中配置数据源和数据库规则,包括数据库连接信息、数据库切片和分布式表的规则等。
4.3 编写业务代码
编写业务代码时,使用Sharding JDBC提供的API进行数据库操作,无需关心具体的数据库切片和分布式表。
下面笔者根据上述步骤,以一个例子来详细展示具体的使用方法:
我们以用户表和订单表为例,对其分库分表。
A.引入Sharding JDBC依赖,可以通过Maven来管理项目依赖。
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>xxx</version>
</dependency>
B.配置数据源和数据库规则,在application.yaml中进行配置。
spring:
shardingsphere:
datasource:
# 数据源配置,定义两个数据源
names: ds0, ds1
ds0:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/database0
username: root
password: root
ds1:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/database1
username: root
password: root
sharding:
tables:
# 订单表的配置
order:
actualDataNodes: ds${0..1}.order_${0..3}
# 表路由策略,根据用户ID进行分表
tableStrategy:
standard:
shardingColumn: user_id
preciseAlgorithmClassName: com.example.algorithm.PreciseModuloTableShardingAlgorithm
# 数据库路由策略,根据用户ID进行分库
databaseStrategy:
standard:
shardingColumn: user_id
preciseAlgorithmClassName: com.example.algorithm.PreciseModuloDatabaseShardingAlgorithm
C.编写自定义的分表策略和分库策略。例如,我们自定义了
PreciseModuloTableShardingAlgorithm和PreciseModuloDatabaseShardingAlgorithm两个算法类,根据用户ID进行分表和分库的计算。
public class PreciseModuloTableShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
@Override
public String doSharding(Collection<String> tableNames, PreciseShardingValue<Long> shardingValue) {
for (String tableName : tableNames) {
if (tableName.endsWith(String.valueOf(shardingValue.getValue() % 4))) {
return tableName;
}
}
// 堆代码 duidaima.com
throw new IllegalArgumentException("Unsupported table name: " + shardingValue.getLogicTableName());
}
}
public class PreciseModuloDatabaseShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
@Override
public String doSharding(Collection<String> databaseNames, PreciseShardingValue<Long> shardingValue) {
for (String databaseName : databaseNames) {
if (databaseName.endsWith(String.valueOf(shardingValue.getValue() % 2))) {
return databaseName;
}
}
throw new IllegalArgumentException("Unsupported database name: " + shardingValue.getLogicTableName());
}
}
D. 编写业务代码,使用Sharding JDBC进行数据库操作。
@Repository
public class OrderRepository {
@Autowired
private JdbcTemplate jdbcTemplate;
public List<Order> findOrdersByUserId(Long userId) {
String sql = "SELECT * FROM `order` WHERE user_id = ?";
return jdbcTemplate.query(sql, new Object[]{userId}, new BeanPropertyRowMapper<>(Order.class));
}
public void saveOrder(Order order) {
String sql = "INSERT INTO `order` (id, user_id, amount) VALUES (?, ?, ?)";
jdbcTemplate.update(sql, order.getId(), order.getUserId(), order.getAmount());
}
}
@Service
public class OrderService {
@Autowired
private OrderRepository orderRepository;
public List<Order> getOrdersByUserId(Long userId) {
return orderRepository.findOrdersByUserId(userId);
}
public void saveOrder(Order order) {
orderRepository.saveOrder(order);
}
}
在上述示例中,我们配置了两个数据源(ds0和ds1),每个数据源对应一个数据库实例。订单表根据用户ID进行分表,共分为4张表(order_0、order_1、order_2、order_3),并根据用户ID进行分库,共分为2个数据库实例。在业务代码中,我们通过Sharding JDBC的API来进行数据库操作,无需关心具体的数据库切片和分布式表。
本文深入探索了Sharding JDBC的核心概念、工作原理和使用方法,并通过一个用户订单分库分表的示例加以完善。通过使用Sharding JDBC,开发者可以轻松应对高并发和大数据量的场景,提升系统的性能和可扩展性。希望本文对读者理解和应用Sharding JDBC有所帮助。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号





