

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

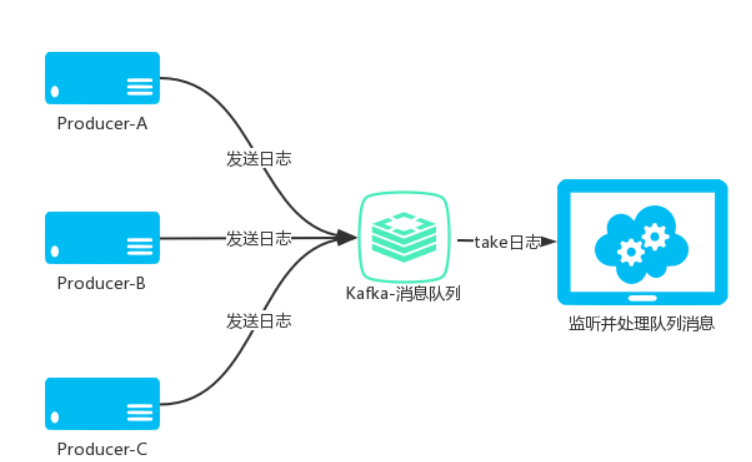
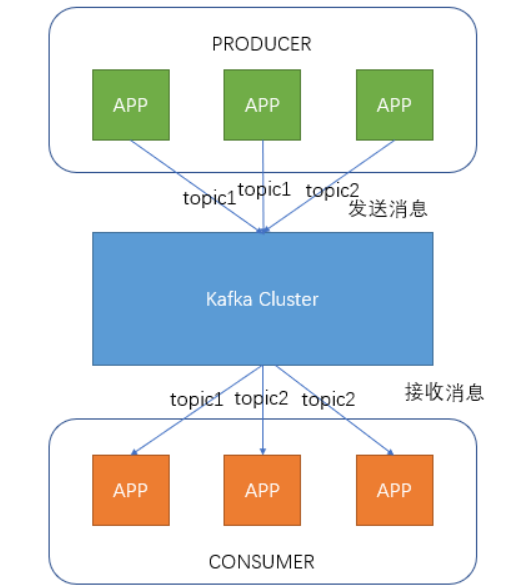
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)
wget https://archive.apache.org/dist/kafka/0.10.0.1/kafka_2.11-0.10.0.1.tgz安装
tar -zxvf kafka_2.11-0.10.0.1.tgz cd kafka_2.11-0.10.0.1目录说明
bin 启动,停止等命令 config 配置文件 libs 类库参数说明
#########################参数解释############################## # 堆代码 duidaima.com broker.id=0 #当前机器在集群中的唯一标识,和zookeeper的myid性质一样 port=9092 #当前kafka对外提供服务的端口默认是9092 host.name=192.168.1.170 #这个参数默认是关闭的 num.network.threads=3 #这个是borker进行网络处理的线程数 num.io.threads=8 #这个是borker进行I/O处理的线程数 log.dirs=/opt/kafka/kafkalogs/ #消息存放的目录,这个目录可以配置为“,”逗号分割的表达式,上面的num.io.threads要大于这个目录的个数这个目录,如果配置多个目录,新创建的topic他把消息持久化的地方是,当前以逗号分割的目录中,那个分区数最少就放那一个 socket.send.buffer.bytes=102400 #发送缓冲区buffer大小,数据不是一下子就发送的,先回存储到缓冲区了到达一定的大小后在发送,能提高性能 socket.receive.buffer.bytes=102400 #kafka接收缓冲区大小,当数据到达一定大小后在序列化到磁盘 socket.request.max.bytes=104857600 #这个参数是向kafka请求消息或者向kafka发送消息的请请求的最大数,这个值不能超过java的堆栈大小 num.partitions=1 #默认的分区数,一个topic默认1个分区数 log.retention.hours=168 #默认消息的最大持久化时间,168小时,7天 message.max.byte=5242880 #消息保存的最大值5M default.replication.factor=2 #kafka保存消息的副本数,如果一个副本失效了,另一个还可以继续提供服务 replica.fetch.max.bytes=5242880 #取消息的最大直接数 log.segment.bytes=1073741824 #这个参数是:因为kafka的消息是以追加的形式落地到文件,当超过这个值的时候,kafka会新起一个文件 log.retention.check.interval.ms=300000 #每隔300000毫秒去检查上面配置的log失效时间(log.retention.hours=168 ),到目录查看是否有过期的消息如果有,删除 log.cleaner.enable=false #是否启用log压缩,一般不用启用,启用的话可以提高性能 zookeeper.connect=192.168.1.180:12181,192.168.1.181:12181,192.168.1.182:1218 #设置zookeeper的连接端口、如果非集群配置一个地址即可 #########################参数解释##############################
#进入到kafka的bin目录 ./kafka-server-start.sh -daemon ../config/server.propertiesKafka集成
spring-boot、elasticsearch、kafkapom.xml引入:
<!-- kafka 消息队列 -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>1.1.1.RELEASE</version>
</dependency>
生产者import java.util.HashMap;
import java.util.Map;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
/**
* 生产者
* 堆代码 duidaima.com
* 创建时间 2023年7月14日
*/
@Configuration
@EnableKafka
public class KafkaProducerConfig {
@Value("${kafka.producer.servers}")
private String servers;
@Value("${kafka.producer.retries}")
private int retries;
@Value("${kafka.producer.batch.size}")
private int batchSize;
@Value("${kafka.producer.linger}")
private int linger;
@Value("${kafka.producer.buffer.memory}")
private int bufferMemory;
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, servers);
props.put(ProducerConfig.RETRIES_CONFIG, retries);
props.put(ProducerConfig.BATCH_SIZE_CONFIG, batchSize);
props.put(ProducerConfig.LINGER_MS_CONFIG, linger);
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, bufferMemory);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return props;
}
public ProducerFactory<String, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<String, String>(producerFactory());
}
}
消费者mport java.util.HashMap;
import java.util.Map;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.config.KafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import org.springframework.kafka.listener.ConcurrentMessageListenerContainer;
/**
* 消费者
* 堆代码 duidaima.com
* 创建时间 2023年7月14日
*/
@Configuration
@EnableKafka
public class KafkaConsumerConfig {
@Value("${kafka.consumer.servers}")
private String servers;
@Value("${kafka.consumer.enable.auto.commit}")
private boolean enableAutoCommit;
@Value("${kafka.consumer.session.timeout}")
private String sessionTimeout;
@Value("${kafka.consumer.auto.commit.interval}")
private String autoCommitInterval;
@Value("${kafka.consumer.group.id}")
private String groupId;
@Value("${kafka.consumer.auto.offset.reset}")
private String autoOffsetReset;
@Value("${kafka.consumer.concurrency}")
private int concurrency;
@Bean
public KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, String>> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setConcurrency(concurrency);
factory.getContainerProperties().setPollTimeout(1500);
return factory;
}
public ConsumerFactory<String, String> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
public Map<String, Object> consumerConfigs() {
Map<String, Object> propsMap = new HashMap<>();
propsMap.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, servers);
propsMap.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, enableAutoCommit);
propsMap.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, autoCommitInterval);
propsMap.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, sessionTimeout);
propsMap.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
propsMap.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
propsMap.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
propsMap.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, autoOffsetReset);
return propsMap;
}
@Bean
public Listener listener() {
return new Listener();
}
}
日志监听import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
import com.itstyle.es.common.utils.JsonMapper;
import com.itstyle.es.log.entity.SysLogs;
import com.itstyle.es.log.repository.ElasticLogRepository;
/**
* 扫描监听
* 堆代码 duidaima.com
* 创建时间 2023年7月14日
*/
@Component
public class Listener {
protected final Logger logger = LoggerFactory.getLogger(this.getClass());
@Autowired
private ElasticLogRepository elasticLogRepository;
@KafkaListener(topics = {"itstyle"})
public void listen(ConsumerRecord<?, ?> record) {
logger.info("kafka的key: " + record.key());
logger.info("kafka的value: " + record.value());
if(record.key().equals("itstyle_log")){
try {
SysLogs log = JsonMapper.fromJsonString(record.value().toString(), SysLogs.class);
logger.info("kafka保存日志: " + log.getUsername());
elasticLogRepository.save(log);
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
测试日志传输 /**
* kafka 日志队列测试接口
*/
@GetMapping(value="kafkaLog")
public @ResponseBody String kafkaLog() {
SysLogs log = new SysLogs();
log.setUsername("红薯");
log.setOperation("开源中国社区");
log.setMethod("com.itstyle.es.log.controller.kafkaLog()");
log.setIp("192.168.1.80");
log.setGmtCreate(new Timestamp(new Date().getTime()));
log.setExceptionDetail("开源中国社区");
log.setParams("{'name':'码云','type':'开源'}");
log.setDeviceType((short)1);
log.setPlatFrom((short)1);
log.setLogType((short)1);
log.setDeviceType((short)1);
log.setId((long)200000);
log.setUserId((long)1);
log.setTime((long)1);
//模拟日志队列实现
String json = JsonMapper.toJsonString(log);
kafkaTemplate.send("itstyle", "itstyle_log",json);
return "success";
}
Kafka与Redis



