前言
在并发编程中我们为啥一般选用创建多个线程去处理任务而不是创建多个进程呢?这是因为线程之间切换的开销小,适用于一些要求同时进行并且又要共享某些变量的并发操作。而进程则具有独立的虚拟地址空间,每个进程都有自己独立的代码和数据空间,程序之间的切换会有较大的开销。下面介绍几种创建线程的方法,在这之前我们还是要先了解一下什么是进程什么是线程。
一、什么是进程和线程
线程是进程中的一个实体,它本身是不会独立存在的。进程是系统进行资源分配和调度的基本单位,线程则是进程的一个执行路径,一个进程中至少有一个线程,进程中的多个线程共享进程的资源。
进程和线程的关系图如下:
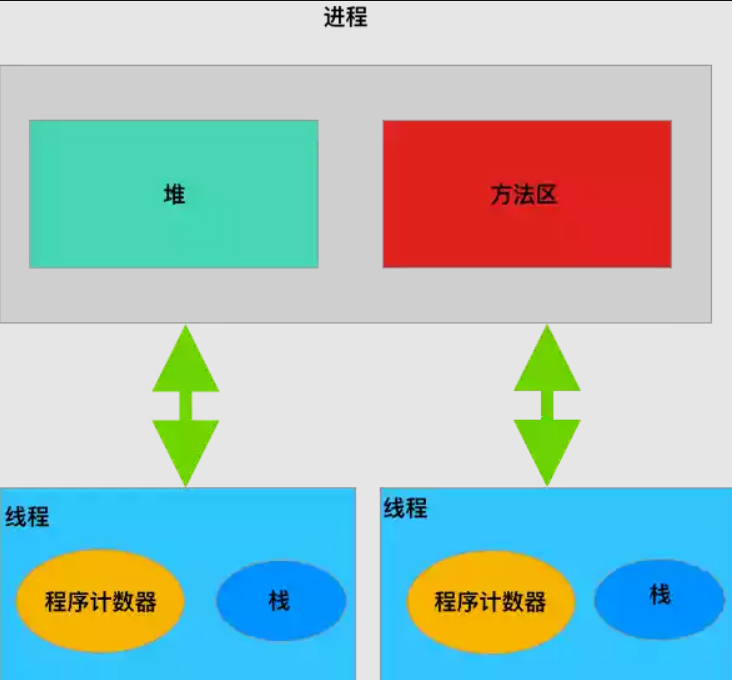
从上面的图中,我们可以知道一个进程中有多个线程,多个线程共享进程的堆和方法区资源,但是每个线程都有自己的程序计数器和栈区域。堆是一个进程中最大的一块内存,堆是被进程中的所有线程共享的,是进程创建时分配的,堆里面主要存放使用new操作创建的对象实例。方法区则用来存放 JVM 加载的类、常量及静态变量等信息,也是线程共享的。
二、线程的创建
Java 中有几种线程创建的方式:
1.实现 Runnable 接口的 run 方法
2.继承 Thread 类并重写 run 的方法
3.使用 FutureTask 方式
4.使用线程池创建
2.1、实现 Runnable 接口的 run 方法
public static void main(String[] args) {
RunableTask task = new RunableTask();
new Thread(task).start();
new Thread(task).start();
}
public static class RunableTask implements Runnable {
@Override
public void run() {
System.out.println("I am a child thread");
}
}
// 输出
I am a child thread
I am a child thread
这段代码创建了一个RunableTask类,该类实现了Runnable接口,并重写了run()方法。在run()方法中,它打印了一条消息:"I am a child thread"。
接下来是main()方法,它是Java程序的入口点。在main()方法中,首先创建了一个RunableTask对象,然后通过调用Thread类的构造函数将该对象作为参数传递给Thread类的构造函数,创建了两个新的线程对象。这两个线程对象分别使用start()方法启动,从而使得每个线程都能够并发地执行。
当程序运行时,会创建两个子线程,它们将并发地执行RunableTask对象的run()方法。由于两个线程是同时运行的,因此它们可能会交替执行run()方法中的代码。在这种情况下,由于线程调度的不确定性,可能会出现以下情况之一:
第一个线程先执行run()方法,打印出"I am a child thread"。
第二个线程先执行run()方法,打印出"I am a child thread"。
需要注意的是,由于线程的执行顺序是不确定的,所以每次运行程序时,输出的结果可能会有所不同。
2.2、继承 Thread 类方式的实现
public static void main(String[] args) {
MyThread thread = new MyThread();
thread.start();
}
//继承Thread类并重写run方法
public static class MyThread extends Thread {
@Override
public void run() {
System.out.println("I am a child thread");
}
}
创建一个名为MyThread的类,该类继承了Thread类,并重写了run()方法。
2.3、用 FutureTask 的方式
public static void main(String[] args) throws InterruptedException {
// 创建异步任务
FutureTask<String> futureTask = new FutureTask<>(new CallerTask());
//启动线程
new Thread(futureTask).start();
try {
//等待任务执行完毕,并返回结果
String result = futureTask.get();
System.out.println(result);
} catch (ExecutionException e) {
e.printStackTrace();
}
}
//堆代码 duidaima.com
//创建任务类,类似Runable
public static class CallerTask implements Callable<String> {
@Override
public String call() throws Exception {
return "hello emanjusaka";
}
}
上面使用了FutureTask和Callable接口来实现异步任务的执行。首先,在main()方法中创建了一个FutureTask对象,并将一个匿名内部类CallerTask的实例作为参数传递给它。这个匿名内部类实现了Callable接口,并重写了call()方法。在call()方法中,它返回了一个字符串"hello emanjusaka"。接下来,通过调用FutureTask对象的start()方法启动了一个新的线程,该线程会执行CallerTask对象的call()方法。由于start()方法是异步执行的,主线程会继续执行后续的代码。然后,使用futureTask.get()方法来等待异步任务的执行结果。这个方法会阻塞当前线程,直到异步任务执行完毕并返回结果。如果任务执行过程中发生了异常,可以通过捕获ExecutionException来处理异常情况。
需要注意的是,由于异步任务的执行是并发进行的,因此输出的结果可能会有所不同。另外,由于FutureTask和Callable接口提供了更灵活和强大的功能,因此在需要处理返回结果或处理异常的情况下,它们比继承Thread类并重写run()方法的方式更加方便和可靠。
2.4、使用线程池
Executors
package top.emanjusaka;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Main {
public static void main(String[] args) {
// 创建一个固定大小的线程池,大小为5
ExecutorService executor = Executors.newFixedThreadPool(5);
// 提交10个任务到线程池中执行
for (int i = 0; i < 10; i++) {
Runnable worker = new WorkerThread("" + i);
executor.execute(worker);
}
// 关闭线程池
executor.shutdown();
while (!executor.isTerminated()) {
}
System.out.println("所有任务已完成");
}
}
class WorkerThread implements Runnable {
private String command;
public WorkerThread(String s) {
this.command = s;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " 开始处理任务: " + command);
processCommand();
System.out.println(Thread.currentThread().getName() + " 完成任务: " + command);
}
private void processCommand() {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
// 输出
pool-1-thread-1 开始处理任务: 0
pool-1-thread-2 开始处理任务: 1
pool-1-thread-3 开始处理任务: 2
pool-1-thread-4 开始处理任务: 3
pool-1-thread-5 开始处理任务: 4
pool-1-thread-2 完成任务: 1
pool-1-thread-4 完成任务: 3
pool-1-thread-2 开始处理任务: 5
pool-1-thread-4 开始处理任务: 6
pool-1-thread-1 完成任务: 0
pool-1-thread-3 完成任务: 2
pool-1-thread-5 完成任务: 4
pool-1-thread-3 开始处理任务: 8
pool-1-thread-1 开始处理任务: 7
pool-1-thread-5 开始处理任务: 9
pool-1-thread-2 完成任务: 5
pool-1-thread-4 完成任务: 6
pool-1-thread-1 完成任务: 7
pool-1-thread-3 完成任务: 8
pool-1-thread-5 完成任务: 9
所有任务已完成
上面的例子中我们首先创建了一个大小为5的线程池。然后,我们提交了10个任务到线程池中执行。每个任务都是一个实现了Runnable接口的WorkerThread对象。最后,我们关闭线程池并等待所有任务完成。
阿里巴巴开发规范建议使用ThreadPoolExecutor来创建线程池,而不是直接使用Executors。这样做的原因是,Executors创建的线程池可能会存在资源耗尽的风险,而ThreadPoolExecutor则可以更好地控制线程池的运行规则,规避资源耗尽的风险 。
ThreadPoolExecutor
package top.emanjusaka;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class Main {
public static void main(String[] args) {
// 创建一个固定大小的线程池,大小为5
ThreadPoolExecutor executor = new ThreadPoolExecutor(5, 10, 200, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>());
for (int i = 0; i < 10; i++) {
Runnable worker = new WorkerThread("" + i);
executor.execute(worker);
}
// 关闭线程池
executor.shutdown();
try {
executor.awaitTermination(Long.MAX_VALUE, TimeUnit.NANOSECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("所有任务已完成");
}
}
class WorkerThread implements Runnable {
private String command;
public WorkerThread(String s) {
this.command = s;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " 开始处理任务:" + command);
processCommand();
System.out.println(Thread.currentThread().getName() + " 完成任务:" + command);
}
private void processCommand() {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
// 输出
pool-1-thread-1 开始处理任务:0
pool-1-thread-3 开始处理任务:2
pool-1-thread-2 开始处理任务:1
pool-1-thread-4 开始处理任务:3
pool-1-thread-5 开始处理任务:4
pool-1-thread-2 完成任务:1
pool-1-thread-3 完成任务:2
pool-1-thread-5 完成任务:4
pool-1-thread-3 开始处理任务:5
pool-1-thread-4 完成任务:3
pool-1-thread-1 完成任务:0
pool-1-thread-4 开始处理任务:8
pool-1-thread-2 开始处理任务:7
pool-1-thread-5 开始处理任务:6
pool-1-thread-1 开始处理任务:9
pool-1-thread-4 完成任务:8
pool-1-thread-3 完成任务:5
pool-1-thread-2 完成任务:7
pool-1-thread-1 完成任务:9
pool-1-thread-5 完成任务:6
所有任务已完成
在这个例子中,我们首先创建了一个大小为5的线程池,其中核心线程数为5,最大线程数为10,空闲线程存活时间为200毫秒,工作队列为LinkedBlockingQueue。然后,我们提交了10个任务到线程池中执行。最后,我们关闭线程池并等待所有任务完成。
ThreadPoolExecutor的构造函数有以下参数:
corePoolSize:核心线程数,即线程池中始终保持活跃的线程数。
maximumPoolSize:最大线程数,即线程池中允许的最大线程数。当工作队列满了之后,线程池会创建新的线程来处理任务,直到达到最大线程数。
keepAliveTime:空闲线程存活时间,即当线程池中的线程数量超过核心线程数时,多余的空闲线程在等待新任务的最长时间。超过这个时间后,空闲线程将被销毁。
unit:keepAliveTime的时间单位,例如TimeUnit.SECONDS表示秒,TimeUnit.MILLISECONDS表示毫秒。
workQueue:工作队列,用于存放待处理的任务。常用的有ArrayBlockingQueue、LinkedBlockingQueue和SynchronousQueue等。
threadFactory:线程工厂,用于创建新的线程。可以自定义线程的名称、优先级等属性。
handler:拒绝策略,当工作队列满了且线程池已满时,线程池如何处理新提交的任务。常用的有AbortPolicy(抛出异常)、DiscardPolicy(丢弃任务)和DiscardOldestPolicy(丢弃队列中最旧的任务)。
executorListeners:监听器,用于监听线程池的状态变化。常用的有ThreadPoolExecutor.AbortPolicy、ThreadPoolExecutor.CallerRunsPolicy和ThreadPoolExecutor.DiscardPolicy。
三、总结
使用继承方式的好处是方便传参,你可以在子类里面添加成员变量,通过set方法设置参数或者通过构造函数进行传递,而如果使用Runnable方式,则只能使用主线程里面被声明为final的变量。不好的地方是Java不支持多继承,如果继承了Thread类,那么子类不能再继承其他类,而Runable则没有这个限制。前两种方式都没办法拿到任务的返回结果,但是Futuretask方式可以。
使用Callable和Future创建线程。这种方式可以将线程作为任务提交给线程池执行,而且可以获取到线程的执行结果。但是需要注意的是,如果线程抛出了异常,那么在主线程中是无法获取到的。使用线程池。线程池是一种管理线程的机制,可以有效地控制线程的数量和复用线程,避免了频繁地创建和销毁线程带来的性能开销。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号




