

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

public class HashMapIteratorDemo {
String[] arr = {
"aa",
"bb",
"cc"
};
public void test1() {
for (String str: arr) {}
}
}
将上面的例子转为字节码反编译一下(主函数部分):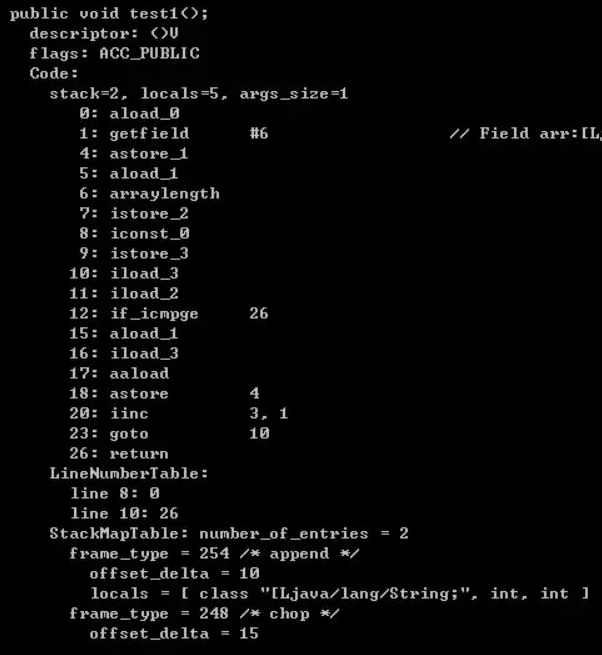
public class HashMapIteratorDemo2 {
String[] arr = {
"aa",
"bb",
"cc"
};
public void test1() {
for (int i = 0; i < arr.length; i++) {
String str = arr[i];
}
}
}
public class HashMapIteratorDemo3 {
List < Integer > list = new ArrayList < > ();
public void test1() {
list.add(1);
list.add(2);
list.add(3);
for (Integer
var: list) {}
}
}
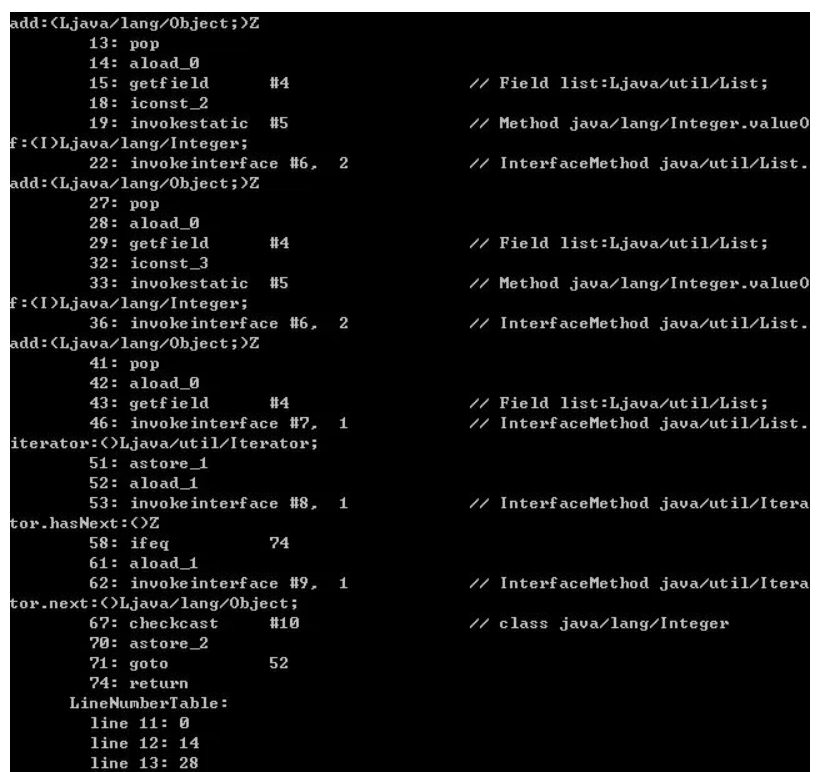
通过 Iterator 遍历集合:public class HashMapIteratorDemo4 {
List < Integer > list = new ArrayList < > ();
public void test1() {
list.add(1);
list.add(2);
list.add(3);
Iterator < Integer > it = list.iterator();
while (it.hasNext()) {
Integer
var = it.next();
}
}
}
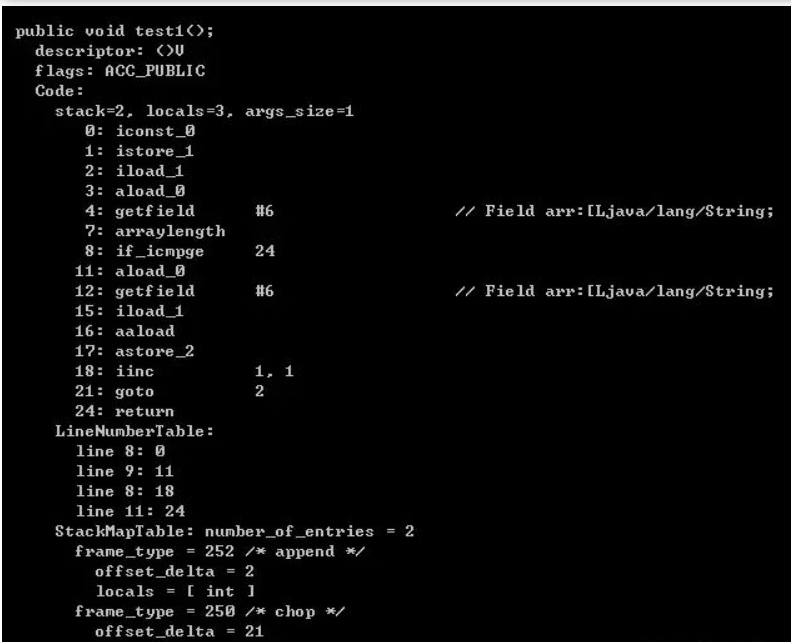
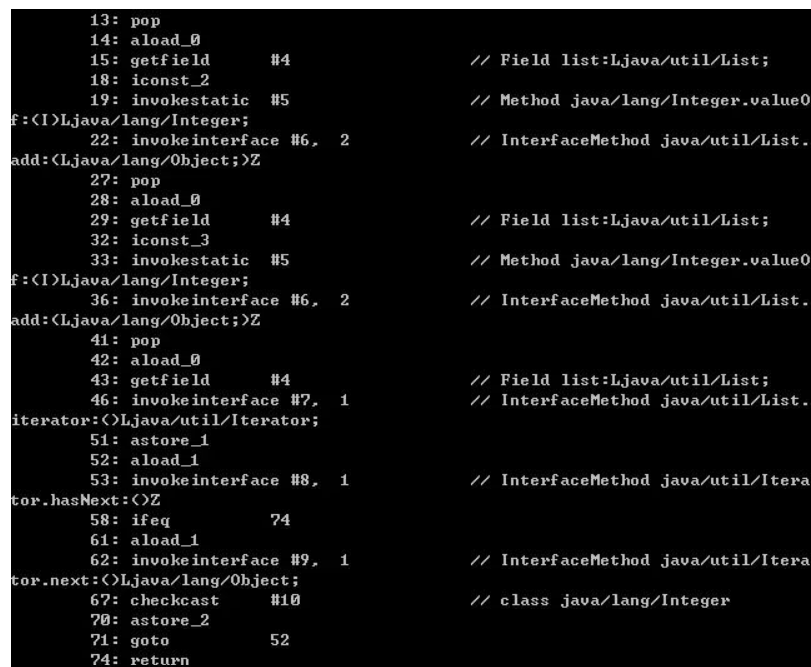
将两个方法的字节码对比如下:
public class HashMapIteratorDemo5 {
public static void main(String[] args) {
Map < Integer, String > map = new HashMap < > ();
map.put(1, "aa");
map.put(2, "bb");
map.put(3, "cc");
for (Map.Entry < Integer, String > entry: map.entrySet()) {
int k = entry.getKey();
String v = entry.getValue();
System.out.println(k + " = " + v);
}
}
}
输出: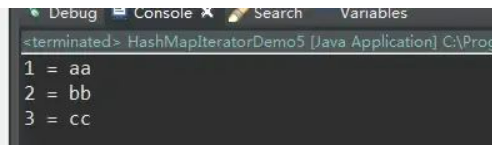
public class HashMapIteratorDemo5 {
public static void main(String[] args) {
Map < Integer, String > map = new HashMap < > ();
map.put(1, "aa");
map.put(2, "bb");
map.put(3, "cc");
for (Map.Entry < Integer, String > entry: map.entrySet()) {
int k = entry.getKey();
if (k == 1) {
map.put(1, "AA");
}
String v = entry.getValue();
System.out.println(k + " = " + v);
}
}
}
执行结果: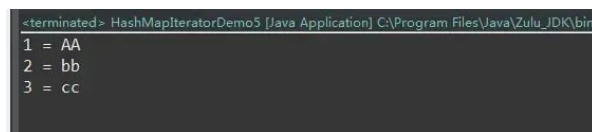
public class HashMapIteratorDemo5 {
public static void main(String[] args) {
Map < Integer, String > map = new HashMap < > ();
map.put(1, "aa");
map.put(2, "bb");
map.put(3, "cc");
for (Map.Entry < Integer, String > entry: map.entrySet()) {
int k = entry.getKey();
if (k == 1) {
map.put(4, "AA");
}
String v = entry.getValue();
System.out.println(k + " = " + v);
}
}
}
执行出现异常: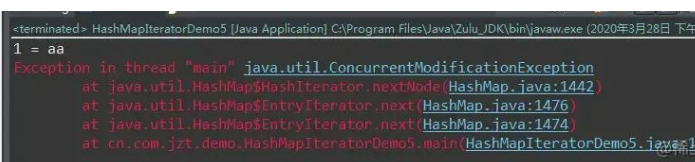
final Node < K, V > nextNode() {
Node < K, V > [] t;
Node < K, V > e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
if ((next = (current = e).next) == null && (t = table) != null) {
do {} while (index < t.length && (next = t[index++]) == null);
}
return e;
}
这里 modCount 是表示 map 中的元素被修改了几次(在移除,新加元素时此值都会自增),而 expectedModCount 是表示期望的修改次数,在迭代器构造的时候这两个值是相等,如果在遍历过程中这两个值出现了不同步就会抛出 ConcurrentModificationException 异常。
public V remove(Object key) {
Node < K, V > e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
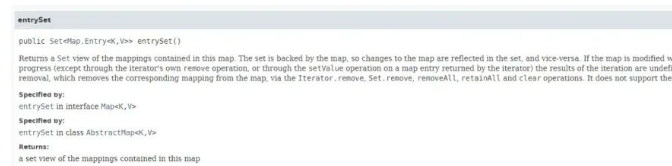
(2)HashMap.KeySet 的 remove 实现public final boolean remove(Object key) {
return removeNode(hash(key), key, null, false, true) != null;
}
(3)HashMap.EntrySet 的 remove 实现public final boolean remove(Object o) {
if (o instanceof Map.Entry) {
Map.Entry << ? , ? > e = (Map.Entry << ? , ? > ) o;
Object key = e.getKey();
Object value = e.getValue();
return removeNode(hash(key), key, value, true, true) != null;
}
return false;
}
(4)HashMap.HashIterator 的 remove 方法实现public final void remove() {
Node < K, V > p = current;
if (p == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
current = null;
K key = p.key;
removeNode(hash(key), key, null, false, false);
expectedModCount = modCount; //--这里将expectedModCount 与modCount进行同步
}
以上四种方式都通过调用 HashMap.removeNode 方法来实现删除key的操作。在 removeNode 方法内只要移除了 key, modCount 就会执行一次自增操作,此时 modCount 就与 expectedModCount 不一致了;final Node < K, V > removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node < K, V > [] tab;
Node < K, V > p;
int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
...
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode < K, V > ) node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount; //----这里对modCount进行了自增,可能会导致后面与expectedModCount不一致
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
上面三种 remove 实现中,只有第三种 iterator 的 remove 方法在调用完 removeNode 方法后同步了 expectedModCount 值与 modCount 相同,所以在遍历下个元素调用 nextNode 方法时,iterator 方式不会抛异常。public class HashMapIteratorDemo5 {
public static void main(String[] args) {
Map < Integer, String > map = new HashMap < > ();
map.put(1, "aa");
map.put(2, "bb");
map.put(3, "cc");
Iterator < Map.Entry < Integer, String >> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry < Integer, String > entry = it.next();
int key = entry.getKey();
if (key == 1) {
it.remove();
}
}
}
}





