

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

Java Random 随机数生成不安全,如果同时泄漏第一个和第二个随机数,那么后面的随机数序列可以被破解。Java Random类使用线性同余生成器(Linear Congruential Generator)算法来生成伪随机数。所谓伪随机数是指,如果我们使用相同的种子(seed)来生成随机数序列,那么得到的结果将是一样的。
Random random = new Random(0);
int cnt = 10;
for (int i = 0; i < cnt; i++) {
System.out.println(random.nextLong());
}
这意味着,当我们设置种子为 0 时,每次运行代码得到的随机数序列将是相同的。无论是在任何时间,还是在任何设备上,以下代码生成的随机数始终保持一致。这也意味着一旦黑客获得了你的种子“seed”,他们可以预测出你所生成的所有随机数。要想生成不同的随机数序列,我们需要使用不同的种子。

private static final AtomicLong seedUniquifier
= new AtomicLong(8682522807148012L);
private static long seedUniquifier() {
// L'Ecuyer, "Tables of Linear Congruential Generators of
// Different Sizes and Good Lattice Structure", 1999
for (;;) {
long current = seedUniquifier.get();
long next = current * 181783497276652981L;
if (seedUniquifier.compareAndSet(current, next))
return next;
}
}
这段代码使用AtomicLong 计算种子,很明显是为了保证多线程场景下创建多个Random对象时,产生不同的种子值。在seedUniquifier方法中,使用了AtomicLong.compareAndSet方法来保证每次执行该方法时生成不同的初始种子值。通过这种方法,我们可以确保在多线程应用中,当出现种子冲突时,我们可以通过CAS操作(Compare and Swap)进行重试,以确保每个线程创建的Random对象的初始种子值是不同的。
在代码中,通过将不同的初始种子值与当前系统时间的纳秒进行异或运算,可以保证每次Random执行都会得到不同的种子。那么,这是否能保证种子不会被黑客猜到呢?
private static final long multiplier = 0x5DEECE66DL;
private static final long addend = 0xBL;
private static final long mask = (1L << 48) - 1;
// 堆代码 duidaima.com
@Test
public void test6() {
int a = -117510532;
int b = -1347210525;
int c = 2076362838;//待预测值
long oldseed = ((long) a << 16);
for (int i = 0; i <= 0xffff; i++) {//暴力破解种子
long nextseed = (oldseed * multiplier + addend) & mask;
if ((int) (nextseed >>> 16) == b) {
oldseed = nextseed;
break;
}
oldseed += 1;
}
int next_int = (int) (((oldseed * multiplier + addend) & mask) >>> 16);
System.out.println(next_int == c);
}
对于nextLong和nextDouble方法,只需要知道任意一个随机数即可预测后续随机数;而对于nextInt和nextFloat,如果同时泄漏第一个和第二个随机数,那么后面的随机数也都是可预测的。Random 生成的随机数只有48位,这意味着在随机情况下,通过有限次数的尝试,使用当今先进的CPU,就可能在有限时间内破解。对于一些服务来说,如果很长时间不重新启动,也就意味着种子值(seed)很长时间不更新,这样预测种子值将变得更加容易。
然而有人可能会质疑,预测种子值和推测随机值有什么问题呢?在大多数情况下,比如随机将请求路由到一台机器或随机选中一个userId等场景,即使种子值被猜测到,也不会有太大的危险。但是在某些场景下,比如使用随机数生成密码、兑换码、推广码、各种Token等,如果这些随机数的应用被攻破,可能会带来难以估量的损失。例如,如果成功推测出兑换码码池中的随机数,那么生成的兑换码就不再安全可靠,比如兑换京东购物卡。
那么有什么方法可以安全地使用随机数呢?
Java提供了 「SecureRandom」 随机数生成类,可以安全的生成随机数。SecureRandom 相比 Random有什么优势呢?
1.Random 最多生成48位随机值,但是SecureRandom最多可生成128位随机值。
对于使用Random的情况,需要约2^48次尝试才能破解它,但是由于今天先进的CPU,实际上可能很快就能破解。而对于SecureRandom,则需要约2^128次尝试才能破解,即使使用今天先进的计算机,也需要花费多年的时间。所以,SecureRandom提供了更高的安全性。
2.SecureRandom 不使用固定种子值。而是从操作系统/dev/random 随机数文件中不断获取新的种子值。
操作系统会收集各种随机数据,例如按键之间的间隔等。这些随机数据会被存储在文件中,对于linux和solaris系统来说,常见的文件路径是/dev/random和/dev/urandom。将这些随机数据作为种子,用于生成随机数或执行其他加密或随机化操作。
SecureRandom 它会从/dev/random文件中获取随机种子值,每次调用nextBytes()都会获取不同的随机种子值。通过这种方式,即使攻击者观察输出也无法推断出任何信息。因为随机种子一直在变化,除非他能够控制/dev/random文件的内容(这是非常不可能的)。
在SHA1PRNG算法中使用的seed是在系统启动时就指定的。
NativePRNGBlocking每次计算随机数需要从/dev/random文件中获取数值。
当/dev/random的随机数不足时,NativePRNGBlocking将会被阻塞。在桌面应用程序中,/dev/random文件很少会受到阻塞,因为它可以收集用户的鼠标、点击等事件。然而,在Web程序中,由于并发度较高,生成/dev/random数据可能会出现不足的情况。例如有人使用 NativePRNGBlocking 算法,在线上环境服务启动时,一直被阻塞。就是因为/dev/random数据较少,NativePRNGBlocking 初始化被阻塞。
NativePRNGNonBlocking
为了避免获取随机数被阻塞,NativePRNGNonBlocking选择从/dev/urandom中获取随机数。在/dev/urandom 和 /dev/random之间有一些区别。/dev/random通过收集系统上的环境噪声(如硬件噪声、磁盘活动等)来生成随机数。它只在系统上具有足够的环境噪声时才能生成高质量的随机数。而/dev/urandom是一个伪随机数生成器设备文件,它使用内部熵池持续生成随机数,不管系统上的环境噪声有多少。因此,/dev/urandom生成随机数的速度比/dev/random快得多。
总结一下,/dev/urandom生成的随机数质量稍差,但是能稳定输出。而/dev/random生成的随机数质量较高,但是在系统噪音较少时生成随机数据较慢,可能会阻塞部分应用。
使用阻塞算法可能导致线上问题。
SecureRandom secureRandom = SecureRandom.getInstance("SHA1PRNG");
SecureRandom secureRandom = SecureRandom.getInstance("NativePRNGBlocking");
SecureRandom secureRandom = SecureRandom.getInstance("NativePRNGNonBlocking");
secureRandom.nextLong();
SecureRandom并不是线程安全的,可以使用synchronized关键字同步,或者 使用ThreadLocal 为每个线程保存一个 SecureRandom实例。

总结
在安全性要求较高的场景中,使用 Random 生成的随机数是不安全的。如果获得了其中两个随机数的情况下,后续的随机序列可以被破解。为了提高安全性,需要在一些场景中使用SecureRandom来生成随机数,例如在生成随机密码、兑换码和推广码等场景中。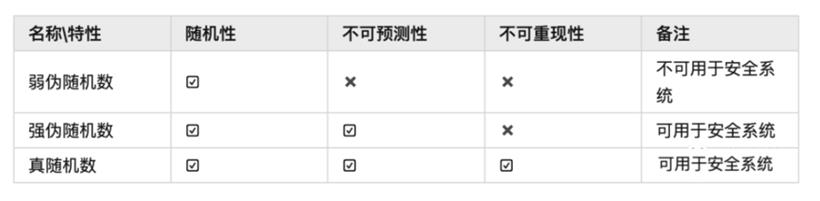
SecureRandom secureRandom = SecureRandom.getInstance("NativePRNGNonBlocking");
secureRandom.nextLong();




