

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

3.提高线程的可管理性
private static final ExecutorService threadPoolExecutor =
new ThreadPoolExecutor(10, 10, 0L, TimeUnit.MILLISECONDS
, taskQueue
, new NamedThreadFactory("project_flow_match_work", Boolean.FALSE));
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
threadFactory, defaultHandler);
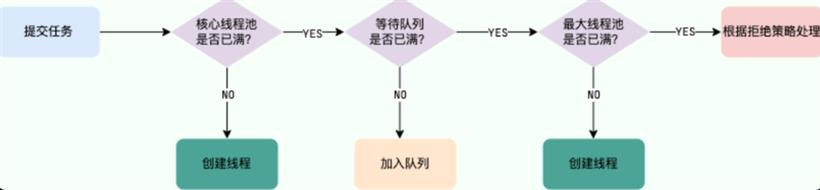
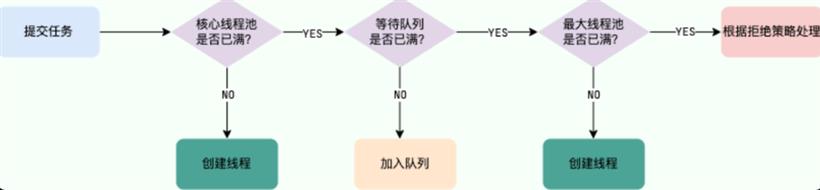
corePoolSize :线程池中的核心线程数,当提交一个任务时,线程池创建一个新线程执行任务,直到当前线程数等于 corePoolSize, 即使有其他空闲线程能够执行新来的任务, 也会继续创建线程;如果当前线程数为 corePoolSize,继续提交的任务被保存到阻塞队列中,等待被执行;如果执行了线程池的 prestartAllCoreThreads() 方法,线程池会提前创建并启动所有核心线程。DiscardPolicy: 直接丢弃任务;
ThreadPoolExecutor.DiscardOldestPolicy:此策略将丢弃最早的未处理的任务请求。
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
我们发现其中核心线程数及最大线程数一样,很容易推理出在达到核心线程数之后线程池并不会扩容,线程池的线程数量达 corePoolSize 后,即使线程池没有可执行任务时,也不会释放线程,我们很容易发现这是一个含有固定线程数的线程池,一般使用在规定最大并发数量的场景。2.由于使用了无界队列, 所以 FixedThreadPool 永远不会拒绝, 即饱和策略失效
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
初始化的线程池中只有一个线程,如果该线程异常结束,会重新创建一个新的线程继续执行任务,唯一的线程可以保证所提交任务的顺序执行.public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
线程池的线程数可达到 Integer.MAX_VALUE,即 2147483647,内部使用 SynchronousQueue 作为阻塞队列;和 newFixedThreadPool 创建的线程池不同,newCachedThreadPool 在没有任务执行时,当线程的空闲时间超过 keepAliveTime,会自动释放线程资源,当提交新任务时,如果没有空闲线程,则创建新线程执行任务,会导致一定的系统开销, 执行过程与前两种稍微不同:.执行完任务的线程倘若在 60s 内仍空闲, 则会被终止. 因此长时间空闲的 CachedThreadPool 不会持有任何线程资源.
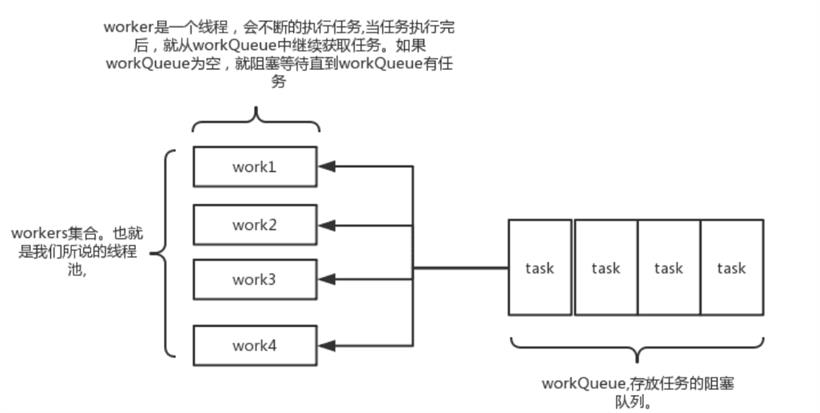
//这个属性是用来存放 当前运行的worker数量以及线程池状态的 //int是32位的,这里把int的高3位拿来充当线程池状态的标志位,后29位拿来充当当前运行worker的数量 private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); //存放任务的阻塞队列 private final BlockingQueue<Runnable> workQueue; //worker的集合,用set来存放 private final HashSet<Worker> workers = new HashSet<Worker>(); //历史达到的worker数最大值 private int largestPoolSize; //当队列满了并且worker的数量达到maxSize的时候,执行具体的拒绝策略 private volatile RejectedExecutionHandler handler; //超出coreSize的worker的生存时间 private volatile long keepAliveTime; //常驻worker的数量 private volatile int corePoolSize; //最大worker的数量,一般当workQueue满了才会用到这个参数 private volatile int maximumPoolSize;
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// runState is stored in the high-order bits
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
// 堆代码 duidaima.com
// Packing and unpacking ctl
private static int runStateOf(int c) { return c & ~CAPACITY; }
private static int workerCountOf(int c) { return c & CAPACITY; }
private static int ctlOf(int rs, int wc) { return rs | wc; }
.混合型: CPU 密集型的任务与 IO 密集型任务的执行时间差别较小,拆分为两个线程池;否则没有必要拆分。
getActiveCount() Returns the approximate number of threads that are actively executing tasks.
public ExportSupport() {
threadPoolExecutor = new ThreadPoolExecutor(10, 10, 10, TimeUnit.SECONDS
, new LinkedBlockingQueue<>(500), runnable ->
new Thread(runnable, "Export_Thread-" + threadNo.getAndIncrement())
);
}
可以发现我采用了前面提到的 newFixedThreadPool 类型,这是考虑到业务的需求需要固定线程数。



