关于 BeanPostProcessor 我之前已经写过好几篇文章和大家聊过了,不过之前聊的都是常规的 BeanPostProcessor 玩法,还有一个特殊的 BeanPostProcessor,今天我来和大家梳理一下。
一. BeanPostProcessor
先来回顾一下 BeanPostProcessor 接口的定义:
public interface BeanPostProcessor {
@Nullable
default Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
return bean;
}
@Nullable
default Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
return bean;
}
}
这里就是两个方法,理解这两个方法有一个大的前提,就是此时 Spring 容器已经通过 Java 反射创建出来 Bean 对象了,只不过在初始化这个 Bean 对象的时候,又提供了一些配置接口:
postProcessBeforeInitialization:这个是在 Bean 初始化之前触发,此时我们已经有一个 Bean 对象了,但是 Bean 中一些生命周期方法如 InitializingBean 接口的 afterPropertiesSet 方法、自定义的 init-method 方法等都尚未执行,在这些方法执行之前触发 postProcessBeforeInitialization 方法。
postProcessAfterInitialization:类似于上面,在 afterPropertiesSet 和自定义的 init-method 之后触发该方法。
BeanPostProcessor 的应用非常广泛,在整个 Spring 体系中,也扮演了非常重要的角色,如 @Bean 注解的解析、AOP 动态代理的生成等等许多我们日常使用的功能,都是通过 BeanPostProcessor 来实现的。
二. MergedBeanDefinitionPostProcessor
MergedBeanDefinitionPostProcessor 算是整个 BeanPostProcessor 家族中比较另类的一个接口了,它虽然是 BeanPostProcessor,但是却可以处理 BeanDefinition。MergedBeanDefinitionPostProcessor 介入的时机就是 Bean 创建成功之后,Bean 中各个属性填充之前。
MergedBeanDefinitionPostProcessor 用于在 Bean 定义合并之后对合并后的 Bean 进行后置处理。它的作用是允许开发者在 Bean 定义合并完成后,对合并后的 Bean 进行自定义的修改或扩展操作。通常情况下,这个接口用于处理带有注解的 Bean 定义,例如 @Autowired 或 @Value 等注解的处理。通过实现 MergedBeanDefinitionPostProcessor 接口,开发者可以在 Bean 定义合并后,对这些注解进行解析和处理,以实现自定义的逻辑。
来看下 MergedBeanDefinitionPostProcessor 接口:
public interface MergedBeanDefinitionPostProcessor extends BeanPostProcessor {
void postProcessMergedBeanDefinition(RootBeanDefinition beanDefinition, Class<?> beanType, String beanName);
default void resetBeanDefinition(String beanName) {
}
}
这里就两个方法,一个是处理合并后的 BeanDefinition,还有一个是重置 Bean 的。
关于 MergedBeanDefinitionPostProcessor 接口有一个误区,有的小伙伴看到 merge 这个单词,又联想到我之前讲的给 bean 设置 parent(Spring BeanDefinition 也分父子?),会误以为合并 parent 属性是在这里完成的,其实这两个东西八杆子打不着。这里的单词也不是 merge,而是 merged,意思是处理合并之后的 BeanDefinition,而不是去进行 BeanDefinition 的合并。所以 MergedBeanDefinitionPostProcessor 并非进行 BeanDefinition 的合并处理,而是在 BeanDefinition 合并完成之后,Bean 创建完毕之后,Bean 属性填充之前,做一些事情。
三. 场景分析
MergedBeanDefinitionPostProcessor 最为经典的使用场景是对于 @Autowired 注解的处理。要理解这一点,小伙伴们先来看一下我画的这个 Spring 中 Bean 的创建流程图:
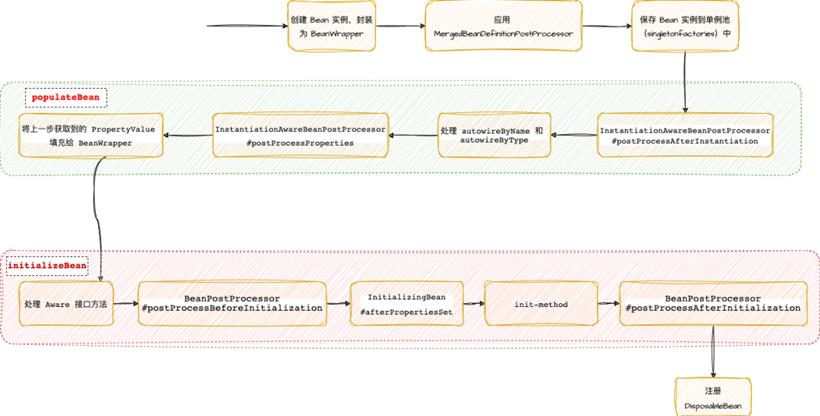
上图基本上涵盖了整个 Bean 的创建流程了,在 Bean 的创建流程中,有一个步骤是 populateBean,这个就是去填充 Bean 的,本质上就是给 Bean 的属性填充值。
小伙伴要问了,即然 populateBean 方法是给 Bean 的属性填充值的,那么通过 @Autowired 注解给 Bean 的属性注入值按理说也应该是在这个方法中完成的吧?为什么又要去到 MergedBeanDefinitionPostProcessor 中去完成呢?其实这两个并不冲突。
在具体执行过程中,MergedBeanDefinitionPostProcessor 首先负责去将类中的各种被注解标记的方法和属性都找出来,然后进行处理,将处理结果封装为一个 InjectionMetadata 对象,然后缓存起来。然后在 populateBean 为 Bean 填充属性的时候,直接去处理这些封装好的 InjectionMetadata。
以上就是大致逻辑。我们再从源码角度来验证一下。
首先 Bean 的创建是在 AbstractAutowireCapableBeanFactory#doCreateBean 方法中进行的,我们来看下这个方法中几个关键步骤:
protected Object doCreateBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)
throws BeanCreationException {
//...
synchronized (mbd.postProcessingLock) {
if (!mbd.postProcessed) {
try {
applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);
}
mbd.markAsPostProcessed();
}
}
//...
try {
populateBean(beanName, mbd, instanceWrapper);
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
//...
}
在 applyMergedBeanDefinitionPostProcessors 方法中就会触发 MergedBeanDefinitionPostProcessor#postProcessMergedBeanDefinition 方法的执行。以处理 @Autowired 注解为例,在 AutowiredAnnotationBeanPostProcessor#postProcessMergedBeanDefinition 方法中先进行属性的整理:
@Override
public void postProcessMergedBeanDefinition(RootBeanDefinition beanDefinition, Class<?> beanType, String beanName) {
findInjectionMetadata(beanName, beanType, beanDefinition);
}
private InjectionMetadata findInjectionMetadata(String beanName, Class<?> beanType, RootBeanDefinition beanDefinition) {
InjectionMetadata metadata = findAutowiringMetadata(beanName, beanType, null);
metadata.checkConfigMembers(beanDefinition);
return metadata;
}
private InjectionMetadata findAutowiringMetadata(String beanName, Class<?> clazz, @Nullable PropertyValues pvs) {
// Fall back to class name as cache key, for backwards compatibility with custom callers.
String cacheKey = (StringUtils.hasLength(beanName) ? beanName : clazz.getName());
// Quick check on the concurrent map first, with minimal locking.
InjectionMetadata metadata = this.injectionMetadataCache.get(cacheKey);
if (InjectionMetadata.needsRefresh(metadata, clazz)) {
synchronized (this.injectionMetadataCache) {
metadata = this.injectionMetadataCache.get(cacheKey);
if (InjectionMetadata.needsRefresh(metadata, clazz)) {
if (metadata != null) {
metadata.clear(pvs);
}
metadata = buildAutowiringMetadata(clazz);
this.injectionMetadataCache.put(cacheKey, metadata);
}
}
}
return metadata;
}
可以看到,上面方法在执行的过程中会把查找到封装好的 InjectionMetadata 对象先给缓存起来。接下来在 populateBean 方法中进行 Bean 的属性填充的时候,调用的 AutowiredAnnotationBeanPostProcessor#postProcessProperties 方法:
@Override
public PropertyValues postProcessProperties(PropertyValues pvs, Object bean, String beanName) {
InjectionMetadata metadata = findAutowiringMetadata(beanName, bean.getClass(), pvs);
try {
metadata.inject(bean, beanName, pvs);
}
catch (BeanCreationException ex) {
throw ex;
}
catch (Throwable ex) {
throw new BeanCreationException(beanName, "Injection of autowired dependencies failed", ex);
}
return pvs;
}
此时再去调用 findAutowiringMetadata 方法的时候,就可以直接从缓存中获取 InjectionMetadata 了。
对于 InjectionMetadata#inject 方法以及 findAutowiringMetadata 方法,我在之前的文章中都已经详细介绍过了,这里就不再赘述了,不了解的小伙伴戳这里:@Autowired 到底是怎么把变量注入进来的?。
四. 小结
好了,这就是我和大家分享的 Spring 中一个特殊的 BeanPostProcessor -> MergedBeanDefinitionPostProcessor,特殊之处在于它和普通的 BeanPostProcessor 的执行时机不同。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






