流处理就是数据处理工作流,本质上是一种计算机编程范例。非要做一个定义,那就是流处理是对接收到的新数据事件的连续处理。它涉及对从生产者到消费者的一系列事件进行处理。咱们从大数据、流式编程、Java流三个方面来聊。但是首先咱们先看看什么是数据流。
什么是数据流
数据流(也被称为事件流或流数据),是无边界数据集的抽象表示。无边界意味着无限和持续增长。无边界数据集之所以是无限的,是因为随着时间的推移,会有新记录不断加入。谷歌和亚马逊等大多数公司采用了这个定义。这个简单的模型(事件流)几乎可以用来表示任何一种业务活动,比如信用卡交易、股票交易、包裹递送、流经交换机的网络事件、制造商设备传感器发出的事件、发送出去的邮件、游戏场景中的物体移动,等等。这样的例子不胜枚举,因为大部分事情可以被看成一个事件序列。
除了无边界,事件流模型还有其他一些属性:
事件流是有序的
事件的发生都有先后顺序。以金融活动事件为例,先把钱存进账户,然后再把钱花掉与先把钱花掉,然后再把钱存入账户的顺序是完全不一样的。后者会出现透支,前者则不会。
不可变的数据记录
事件一旦发生,就不能被改变。一次金融交易被取消,并不是说它消失了,相反,表示前一个交易操作被取消的事件将被添加到事件流中。顾客向商店退货,之前的销售事实并不会消失,退货行为将被视为一个额外的事件。
事件流是可重放的
这是事件流非常有价值的一个属性。我们都知道不可重放的流(流经套接字的TCP数据包通常是不可重放的),但对大多数业务应用程序来说,能够重放发生在几个月前(甚至几年前)的原始事件流是非常关键的。可能是为了能够使用新的分析方法纠正过去的错误,或者是为了达到审计的目的。
“流式处理”的真正含义
流式处理是指实时地处理一个或多个事件流。流式处理是一种编程范式,就像请求与响应范式和批处理范式一样。下面将对这3种范式进行比较,以便更好地理解如何在软件架构中应用流式处理。
请求与响应
这是延迟最小的一种范式,响应时间在亚毫秒和毫秒之间,通常也比较稳定。这种处理模式一般是阻塞的,即应用程序会向处理系统发出请求,然后等待响应。在数据库领域,这种范式就是联机事务处理(OLTP)。销售点(POS)系统、信用卡处理系统和基于时间的追踪系统通常都使用这种范式。
批处理
这种范式具有高延迟和高吞吐量的特点。处理系统按照设定的时间启动处理进程,比如每天凌晨两点开始启动、每小时启动一次,等等。
流式处理
这种范式是连续的、非阻塞的。流式处理填补了请求与响应范式和批处理范式之间的空白。
大多数业务流程是持续进行的,只要业务报告保持更新,业务产品线应用程序能够持续响应,处理流程就可以进行下去,不一定需要毫秒级的响应。具有持续性和非阻塞特点的业务流程,比如针对可疑信用卡交易或网络发送告警、根据供应关系实时调整价格、跟踪快递包裹,都可以选择这种范式。
大数据领域
在大数据领域,常见的流处理框架,有Apache Flink、Apache Storm、Apache Spark Streaming、Kafka Streams等。
都是流处理框架,flink和kafka有什么区别?
Kafka是一种分布式流处理平台,用于在分布式系统之间可靠地传输数据流。它是一种可扩展的、高吞吐量的发布-订阅消息系统,具有高效、持久和可靠的消息传递特性。Kafka被广泛用于构建实时数据管道和流处理应用程序,可处理来自多个数据源的数据流,并将数据流转换为有用的数据。
Flink是一种实时数据流处理引擎,具有高吞吐量、低延迟、高可用性等特性,它支持在流数据和批处理之间无缝切换。Flink可以进行实时的ETL(Extract-Transform-Load)操作、流式查询和机器学习。Flink提供了丰富的API和开箱即用的库,可以方便地构建、部署和管理大规模的实时数据流处理应用程序。
因此,Kafka和Flink的主要区别在于其定位和功能。Kafka主要用于数据传输和实时数据管道的构建,而Flink主要用于实时数据流处理和流式计算。
流式编程
刚才提到的流式计算,没实际用过MapReduce的话可能感触不深。但流式编程与MapReduce本质是一样的。Stream(流)是 Java 8 引入的一个新的抽象概念,它代表着一种处理数据的序列。简单来说,Stream 是一系列元素的集合,这些元素可以是集合、数组、I/O 资源或者其他数据源。
Stream API 提供了丰富的操作方法,可以对 Stream 中的元素进行各种转换、过滤、映射、聚合等操作,从而实现对数据的处理和操作。Stream API 的设计目标是提供一种高效、可扩展和易于使用的方式来处理大量的数据。
Java的流式编程主要通过Stream API来实现,主要包括以下三个步骤:
创建流:可以通过集合类的stream()方法或Stream类的静态方法来创建流,如List.stream()、Stream.of()等。
中间操作:可以使用一系列的中间操作来对流中的元素进行处理,如filter()、map()、sorted()等。
终端操作:最后需要使用一个终端操作来触发流的计算并获取结果,如forEach()、collect()、reduce()等。
本质上对应了文章一开始的生产者、工作流处理和消费者三个过程。
Java流

使用文件输入流和文件输出流进行文件的读取和写入。
import java.io.*;
public class IO_Copy {
public static void main(String[] args) {
// 数据源对象
File srcFile = new File("D:\Code\JAVA\collection\src\Data\testData.txt");
// 数据目的地对象
File destFile = new File("D:\Code\JAVA\collection\src\Data\testData_copy.txt");
// 堆代码 duidaima.com
// 文件输入流(管道对象)
FileInputStream in = null;
// 文件输出流(管道对象)
FileOutputStream out = null;
try {
in = new FileInputStream(srcFile);
out = new FileOutputStream(destFile);
// 打开阀门1,流转数据(输入端)
int data = in.read();
// 打开阀门2,流转数据(输出端)
out.write(data);
} catch (IOException e) {
throw new RuntimeException(e);
} finally {
if(in != null){
try {
in.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
if(out != null){
try {
out.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
}
}
上述的文件复制效率很低,每复制一个字符,都要开启关闭阀门一次,因此,java也提供了缓冲区的优化方式。它的概念非常容易,就是在文件传输的管道中,增加了一个缓冲管道。
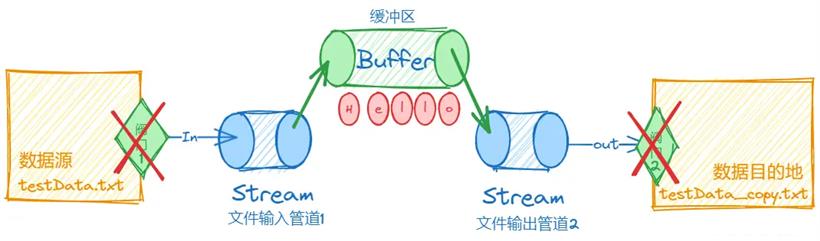
import java.io.*;
public class IO_Copy {
public static void main(String[] args) {
// 数据源对象
File srcFile = new File("D:\Code\JAVA\collection\src\Data\testData.txt");
// 数据目的地对象
File destFile = new File("D:\Code\JAVA\collection\src\Data\testData_copy.txt");
// 文件输入流(管道对象)
FileInputStream in = null;
// 文件输出流(管道对象)
FileOutputStream out = null;
// 缓冲输入流
BufferedInputStream bufferIn = null;
BufferedOutputStream bufferOut = null;
// 创建一个大小为1024字节的缓存区cache。这将用于存储从源文件读取的数据,然后再写入目标文件。
byte[] cache = new byte[1024];
try {
in = new FileInputStream(srcFile);
out = new FileOutputStream(destFile);
// 缓冲输入流
bufferIn = new BufferedInputStream(in);
// 缓冲输出流
bufferOut = new BufferedOutputStream(out);
// 数据流转
int data;
// 当读取到文件末尾(即data为-1)时,循环结束。
while ((data = bufferIn.read(cache)) != -1){
bufferOut.write(cache,0,data);
}
} catch (IOException e) {
throw new RuntimeException(e);
} finally {
if(bufferIn != null){
try {
bufferIn.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
if(bufferOut != null){
try {
bufferOut.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
}
}
从Java流中可以很明显的感受到流的作用:我们不生产数据,我们只是数据的流水线。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






