

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

// 堆代码 duidaima.com
// 错误示例:逐行读取+逐条插入
public void importExcel(File file) {
List<Product> list = ExcelUtils.readAll(file); // 一次加载到内存
for (Product product : list) {
productMapper.insert(product); // 逐行插入
}
}
这种写法会引发三大致命问题:幕后黑手:每次insert都涉及事务提交、索引维护、日志写入
// 正确写法:分段读取(以HSSF为例)
OPCPackage pkg = OPCPackage.open(file);
XSSFReader reader = new XSSFReader(pkg);
SheetIterator sheets = (SheetIterator) reader.getSheetsData();
while (sheets.hasNext()) {
try (InputStream stream = sheets.next()) {
Sheet sheet = new XSSFSheet(); // 流式解析
RowHandler rowHandler = new RowHandler();
sheet.onRow(row -> rowHandler.process(row));
sheet.process(stream); // 不加载全量数据
}
}
⚠️ 避坑指南:// 分页批量插入(每1000条提交一次)
public void batchInsert(List<Product> list) {
SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH);
ProductMapper mapper = sqlSession.getMapper(ProductMapper.class);
int pageSize = 1000;
for (int i = 0; i < list.size(); i += pageSize) {
List<Product> subList = list.subList(i, Math.min(i + pageSize, list.size()));
mapper.batchInsert(subList);
sqlSession.commit();
sqlSession.clearCache(); // 清理缓存
}
}
关键参数调优:# MyBatis配置 mybatis.executor.batch.size=1000 # 连接池(Druid) spring.datasource.druid.maxActive=50 spring.datasource.druid.initialSize=10第三招:异步化处理
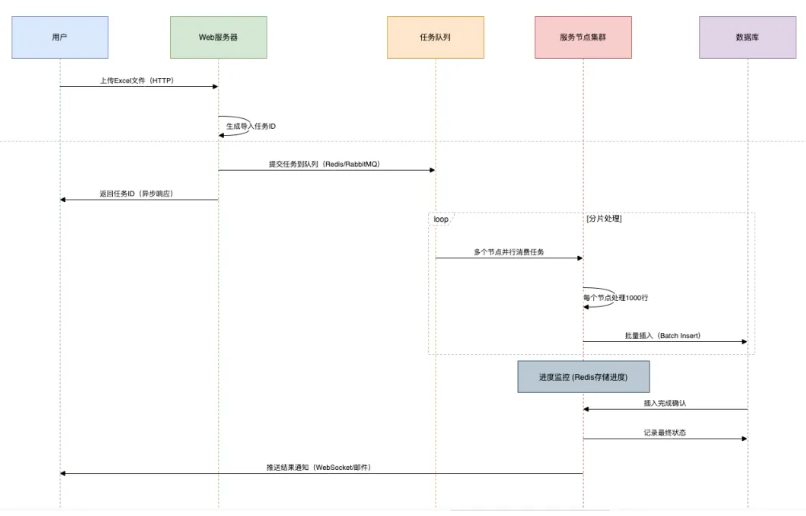
| 阶段 | 操作 | 耗时对比 |
|---|---|---|
| 单线程 | 逐条读取+逐条插入 | 基准值100% |
| 批处理 | 分页读取+批量插入 | 时间降至5% |
| 多线程分片 | 按Sheet分片,并行处理 | 时间降至1% |
| 分布式分片 | 多节点协同处理(如Spring Batch集群) | 时间降至0.5% |
// 错误:边插入边校验,可能污染数据库
public void validateAndInsert(Product product) {
if (product.getPrice() < 0) {
throw new Exception("价格不能为负");
}
productMapper.insert(product);
}
✅ 正确实践:// Spring Boot配置Prometheus指标
@Bean
public MeterRegistryCustomizer<PrometheusMeterRegistry> metrics() {
return registry -> registry.config().meterFilter(
new MeterFilter() {
@Override
public DistributionStatisticConfig configure(Meter.Id id, DistributionStatisticConfig config) {
return DistributionStatisticConfig.builder()
.percentiles(0.5, 0.95) // 统计中位数和95分位
.build().merge(config);
}
}
);
}
四、百万级导入性能实测对比| 方案 | 内存峰值 | 耗时 | 吞吐量 |
|---|---|---|---|
| 传统逐条插入 | 2.5GB | 96分钟 | 173条/秒 |
| 分页读取+批量插入 | 500MB | 7分钟 | 2381条/秒 |
| 多线程分片+异步批量 | 800MB | 86秒 | 11627条/秒 |
| 分布式分片(3节点) | 300MB/节点 | 29秒 | 34482条/秒 |




