

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

elseif (UserConstants.NOT_UNIQUE.equals(userService.checkUserNameUnique(username))
||"匿名用户".equals(username)){
// 注册用户已存在
msg = "注册用户'" + username + "'失败";
}
如上所示: checkUserNameUnique(username)用来验证数据库是否存在用户名:<selectid="checkUserNameUnique"parameterType="String"resultType="int">
select count(1) from sys_user where user_name = #{userName} limit 1
</select>
正常来说,是不会有问题的,那么原因我们后面讲,接着看下一个问题。查询全部分类的下拉列表只能查出5条数据?
如我上面提到的用户可以重复注册,却没有报错,实际在代码当中是有报错的,但是当前方法对异常进行了throw,最终被全局异常捕获了。不分页的sql被拼接了limit,导致没有报错,但是数据返回量错误。异常不是每次出现,是有一定纪律的,但是触发几率较高,原因在后面会逐渐脱出。PageHelper是怎么做到上面的问题的?
@GetMapping("/cms/cmsEssayList")
public TableDataInfo cmsEssayList(CmsBlog cmsBlog){
//状态为发布
cmsBlog.setStatus("1");
startPage();
List<CmsBlog> list = cmsBlogService.selectCmsBlogList(cmsBlog);
return getDataTable(list);
}
使用起来还是很简单的,通过 startPage()指定分页参数,通过getDataTable(list)对结果数据封装成分页的格式。有些同学会问,这也没没传分页参数啊,并且实体类当中也没有,这就是比较有意思的点,下一小结就来聊聊源码。protectedvoidstartPage(){
// 通过request去获取前端传递的分页参数,不需控制器要显示接收
PageDomain pageDomain = TableSupport.buildPageRequest();
Integer pageNum = pageDomain.getPageNum();
Integer pageSize = pageDomain.getPageSize();
if (StringUtils.isNotNull(pageNum) && StringUtils.isNotNull(pageSize))
{
String orderBy = SqlUtil.escapeOrderBySql(pageDomain.getOrderBy());
Boolean reasonable = pageDomain.getReasonable();
// 真正使用pageHelper进行分页的位置
PageHelper.startPage(pageNum, pageSize, orderBy).setReasonable(reasonable);
}
}
PageHelper.startPage(pageNum, pageSize, orderBy).setReasonable(reasonable)的参数分别是:reasonable:分页合理化,对于不合理的分页参数自动处理,比如传递pageNum是小于0,会默认设置为1.
/**
* 开始分页
* 堆代码 duidaima.com
* @param pageNum 页码
* @param pageSize 每页显示数量
* @param count 是否进行count查询
* @param reasonable 分页合理化,null时用默认配置
* @param pageSizeZero true且pageSize=0时返回全部结果,false时分页,null时用默认配置
*/
publicstatic <E> Page<E> startPage(int pageNum, int pageSize, boolean count, Boolean reasonable, Boolean pageSizeZero){
Page<E> page = new Page<E>(pageNum, pageSize, count);
page.setReasonable(reasonable);
page.setPageSizeZero(pageSizeZero);
// 1、获取本地分页
Page<E> oldPage = getLocalPage();
if (oldPage != null && oldPage.isOrderByOnly()) {
page.setOrderBy(oldPage.getOrderBy());
}
// 2、设置本地分页
setLocalPage(page);
return page;
}
到达终点位置了,分别是:getLocalPage()和setLocalPage(page),分别来看下:/**
* 获取 Page 参数
*
* @return
*/
publicstatic <T> Page<T> getLocalPage(){
return LOCAL_PAGE.get();
}
看看常量LOCAL_PAGE是个什么路数?protectedstaticfinal ThreadLocal<Page> LOCAL_PAGE = new ThreadLocal<Page>();好家伙,是ThreadLocal,学过java基础的都知道吧,独属于每个线程的本地缓存对象。当一个请求来的时候,会获取持有当前请求的线程的ThreadLocal,调用LOCAL_PAGE.get(),查看当前线程是否有未执行的分页配置。
protectedstaticvoidsetLocalPage(Page page){
LOCAL_PAGE.set(page);
}
小结@Override
public Object intercept(Invocation invocation)throws Throwable {
try {
Object[] args = invocation.getArgs();
MappedStatement ms = (MappedStatement) args[0];
Object parameter = args[1];
RowBounds rowBounds = (RowBounds) args[2];
ResultHandler resultHandler = (ResultHandler) args[3];
Executor executor = (Executor) invocation.getTarget();
CacheKey cacheKey;
BoundSql boundSql;
// 由于逻辑关系,只会进入一次
if (args.length == 4) {
//4 个参数时
boundSql = ms.getBoundSql(parameter);
cacheKey = executor.createCacheKey(ms, parameter, rowBounds, boundSql);
} else {
//6 个参数时
cacheKey = (CacheKey) args[4];
boundSql = (BoundSql) args[5];
}
checkDialectExists();
//对 boundSql 的拦截处理
if (dialect instanceof BoundSqlInterceptor.Chain) {
boundSql = ((BoundSqlInterceptor.Chain) dialect).doBoundSql(BoundSqlInterceptor.Type.ORIGINAL, boundSql, cacheKey);
}
List resultList;
//调用方法判断是否需要进行分页,如果不需要,直接返回结果
if (!dialect.skip(ms, parameter, rowBounds)) {
//判断是否需要进行 count 查询
if (dialect.beforeCount(ms, parameter, rowBounds)) {
//查询总数
Long count = count(executor, ms, parameter, rowBounds, null, boundSql);
//处理查询总数,返回 true 时继续分页查询,false 时直接返回
if (!dialect.afterCount(count, parameter, rowBounds)) {
//当查询总数为 0 时,直接返回空的结果
return dialect.afterPage(new ArrayList(), parameter, rowBounds);
}
}
resultList = ExecutorUtil.pageQuery(dialect, executor,
ms, parameter, rowBounds, resultHandler, boundSql, cacheKey);
} else {
//rowBounds用参数值,不使用分页插件处理时,仍然支持默认的内存分页
resultList = executor.query(ms, parameter, rowBounds, resultHandler, cacheKey, boundSql);
}
return dialect.afterPage(resultList, parameter, rowBounds);
} finally {
if(dialect != null){
dialect.afterAll();
}
}
}
如上所示是intecept的全部代码,我们下面只关注几个终点位置://处理查询总数,返回 true 时继续分页查询,false 时直接返回
if (!dialect.afterCount(count, parameter, rowBounds)) {
//当查询总数为 0 时,直接返回空的结果
return dialect.afterPage(new ArrayList(), parameter, rowBounds);
}
afterPage其实是对分页结果的封装方法,即使不分页,也会执行,只不过返回空列表。resultList = ExecutorUtil.pageQuery(dialect, executor,
ms, parameter, rowBounds, resultHandler, boundSql, cacheKey);
此方法在执行分页之前,会判断是否执行分页,依据就是前面我们通过ThreadLocal的获取的page。当然,不分页的查询,以及新增和更新不会走到这个方法当中。resultList = executor.query(ms, parameter, rowBounds, resultHandler, cacheKey, boundSql);我们可以思考一下,如果ThreadLoad在使用后没有被清除,当执行非分页的方法时,那么就会将Limit拼接到sql后面。为什么不分也得也会拼接?我们回头看下前面提到的dialect.skip(ms, parameter, rowBounds):
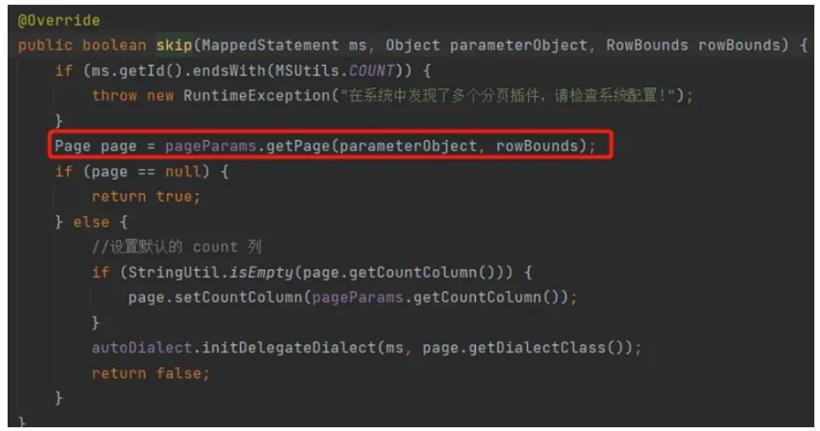
finally {
if(dialect != null){
dialect.afterAll();
}
}
看看这个afterAll()方法:@Override
publicvoidafterAll(){
//这个方法即使不分页也会被执行,所以要判断 null
AbstractHelperDialect delegate = autoDialect.getDelegate();
if (delegate != null) {
delegate.afterAll();
autoDialect.clearDelegate();
}
clearPage();
}
只关注 clearPage():/**
* 移除本地变量
*/
publicstaticvoidclearPage(){
LOCAL_PAGE.remove();
}
小结



