故事
会议室里,小猫挠着头,心里暗暗叫苦着“哎,这代码都撸完了呀,改起来成本也太大了。”原来就在刚才,组长找到了小猫,说代码review过程中发现有些数据表模型设计得不合理,要求小猫改掉。小猫大概是设计了一个配置表,为了省事儿,小猫直接把相关的配置设计成了text类型的存储形式。
关于这种业务场景下使用text文本类型存储,组长指出了以下缺点:
1.在内存中处理Text字段时,由于需要处理大量数据,可能会导致内存使用过度,影响数据库性能。
2.Text字段无法创建索引,这会导致数据库在执行查询时无法利用索引来加速搜索。虽然可以通过全文索引来改善搜索性能,但是却会有诸多限制,例如只能用于InnoDB引擎,并且索引只能建立在不超过1000字节的前缀上。
3.目前刚设计的时候就用text类型,后期随着数据量的增长以及业务需求的变化,可能就意味着要将text类型继续扩大变成,LongText或MediumText类型,这样的转换既费时又可能需要额外的存储空间。
“组长说的也有道理,但是为什么现在才指出来,当时方案模型评审的时候咋提呢,哎,醉了醉了,现在业务逻辑都按照现有方案开发完了,才提出来.....”
“改?要重写逻辑,不改?万一今后真的出现上面组长说的这些问题,不得被喷死......”
彷徨过后,小猫终于下定了决心,改了吧,长痛不如短痛...反正如果不改的话,受罪的还是自己。于是加班是少不了了......
数据库设计
在需求评审完毕之后,一般就是我们的技术方案的设计,在技术方案设计过程中,数据库模型设计是一个非常重要的环节。数据库模型的设计往往会影响后续业务逻辑的拓展或者直接影响着研发实际写代码的工作量。甚至会影响几代研发的维护成本。因此物理数据库的设计应该是一个非常谨慎以及严苛的过程,我们需要步步为营。
那么我们又当如何去进行数据库的设计呢?接下来,老猫从我们日常开发中用到比较多的mysql数据库的设计规范说起。如下。
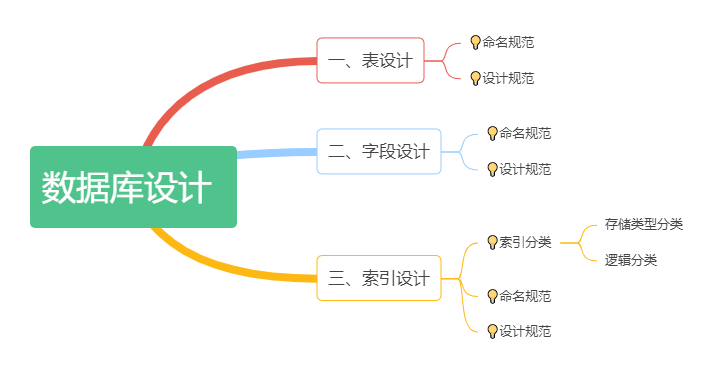 概要
表设计
概要
表设计
关于表设计,咱们从以下几个方面来看。
1、 表的命名:表命名非常重要,我们要尽量去做到见名知意。
2、 根据实际场景确定引擎,咱们一般业务都会涉及到事务、行级锁等功能,所以日常开发中包括设计中咱们还是以InnoDB引擎为准。
表设计-命名规范
1、在给相关的表进行命名的时候,表名建议还是以小写英文字母和0-9数字组成(如果不涉及分表等业务场景,其实很少表名中会带有数字)以及下划线组成。虽然mysql在windows下表名不区分大小写,但是在linux下是区分大小写的,因此表名最好为小写。
2、命名需要分类区分对待,当然英文单词的命名建议使用名词而不是动词,另外的话词义应该要与业务、产品线想关联。例如我们命名一些配置类表的时候习惯以config打头,例如config_XXX。当命名临时表的时候一般tmp打头,一般为tmp_XXX,当备份表的时候那么就是bak_XXX。
3、 表命名咱们要用英文,而不是拼音或者是拼音和英文混合。记得大学刚出来的时候,那时候老猫也用拼音命名过一些表,例如设计图书管理系统的时候居然用上了shu_jia(书架)。现在想想好搓。虽然用到英文,上面提到用名词,那咱们在用名词的时候其实最好也是使用单数形式而非复数。例如员工表设计的时候,我们设计成employee而不是employees。
4、 上述还提及表名中包含数字,其实很多时候在我们分库分表的时候会用到。这里提及几个散表命名方式。首先是hash取模散表,咱们表名后缀使用16进制数,下标从0开始,或者咱们用md5进行散表那么基友user_0,user_ff等等。当然如果用到时间散表,咱们按照年月分表的时候,咱们会命名成user_202404等诸如此类。
表设计-设计规范
1、表设计的时候一般使用Innodb引擎。当然Mysql存在两种可选引擎还有一种是MyISAM。MyISAM速度快,但是不支持事务、外键以及行级锁。反观Innodb速度稍逊一筹,但是可以支持事务、外键(虽然微服务的场景下,外键很少用了)、行级锁等高级功能。
2、必须定义主键。说到主键,咱一般都是Id自增主键。有的时候咱们可能也会用到uuid或者Md5或者hash等字符串作为主键,但是这些列并不能保证数据的顺序增长。这里还是要和大家聊聊这两种主键的优缺点。方便大家后续在做表设计的时候进行取舍。老猫总结了一下,如下图:

3、表设计必须包含创建时间以及修改时间,用于记录创建时间和修改时间。
4、表设计的时候不要使用外键,外键影响高并发下的性能,另外的目前我们的大型项目中会涉及到分库分表,如果遇到外键的话,咱们的分库分表将会难以实施。
5、慎用触发器和存储过程。当然现在咱们应该很少会用到了,老猫只有当年在学习的时候用到了存储过程,后面实际工作的时候好像就再也没有接触过了。触发器和存储过程虽然可以减少开发量,另外封装性也好,比较安全并且不存在SQL注入问题。但是其本身可移植性是非常差的,另外的话占用服务器的资源也比较多,一旦发生错误,咱们排查问题也比较困难。互联网领域,我们现在更愿意把业务逻辑放到代码侧,变更会容易一些。
6、不要在建表的时候进行预留字段,预留字段命名很难做到见名知意,另外的话及时今后用到,在数据量大的情况下,如果类型不满足需求,我们去变更类型的时候会导致锁表。
7、单条记录的大小不要超过8kb。那么这又是为什么呢?首先,咱们从索引角度来看,innodb的页块大小默认为16kb,由于innodb采用聚簇索引(B+树结构)存放数据,每个页块中至少有两行数据,否则就失去了B+树的意义(如果每个页中只有一条数据,整个树就成了一条双向链表)。由于每个页块中至少有两行数据,可以得出一行数据的大小限制为8kb。其次,从硬盘扇区大小的角度来看,单条记录的大小一般不应该超过硬盘的扇区大小,目前硬盘的扇区大小多为4kb(只有少数是16kb),如果单条记录过大的话,查找的时候就会跨越多个扇区,增加寻道时间,可能导致性能下降。
8、单表在设计过程中,咱们最好不要超过50个int字段、20个char字段、2个text字段,另外的话单表列数也要尽量少于50,单表数量咱们也要尽量控制在500w一下,2Gb以内。如果过大的情况下,修改表结构、备份、恢复就有影响,所以当出现太大表的时候,咱们还是尽量要去分库分表。
字段设计
字段设计主要涵盖两个方面,一个是字段的命名,另外一个是字段的数据类型。咱们接下来详细看一下。
字段设计-命名规范
1、和表设计的时候一样,咱们在字段命名的过程中也尽量不要使用拼音。
2、在设计字段的时候,咱们要避免数据库关键字,比如name、time、datetime、desc等等。如果真要用到name的时候,咱们最好加上其他元素以及下划线进行组成,例如user_name、biz_name等等。
3、字段表示枚举、状态类型表示是或者否的时候,咱们最好用is打头,例如is_member,类型用unsigned tinyint(1-是 0-否) default 0。
字段设计-设计规范
1、当我们预知当前字段比较重要,或者之后查询的时候用到比较多的时候,我们肯定要加上索引,那么这种字段,咱们在进行设计的时候就必须定义成Not null,并且设置default值。例如name为非空的,那么我们的定义可能是name not null default '' comment "命名"。
2、如果字段涉及小数存储的时候,我们的字段类型最好使用bigdecimal类型,而不是float或者是double,float以及double都会存在精度丢失的问题。当然有较真的小伙伴也会说bigdecimal也是有范围的,那么如果超过范围的话,应该怎么办?那么这个时候,其实我们可以将其分开进行存储,整数和小数拆开。
3、避免使用text或者blob类型存储大图片文件等信息,这种信息建议直接存储到文件系统,数据库里面可以直接存储对应的文件系统链接即可。
4、字符串类型的,咱们一般使用varchar类型,如果说存储的字符串差不多都是等长的,那么我们可以将字段设计成char定长字符串类型。另外的,varhcar类型在进行设计的时候咱们要避免设计过长,因为varchar类型在存储层面是根据实际长度存储的,但是内存分配却是根据指定长度进行的。所以如果字段设计不合理会导致内存不合理占用。
5、进行时间设计的时候,如果确定只要年月日,那么咱们就将字段设计成date类型。如果说要用到时间戳的话,那么我们要用到datetime以及timestamp。但是我们要注意这两者的区别。关于这两者的区别,老猫再此不做展开,大家有兴趣的可以自己查一下。
6、当多个表中都关联一个字段的时候,咱们应该要保证这两个字段的类型一致,以免在写代码的时候带来不必要的转换麻烦。例如tenant_id这个字段在A表中我们设计成int类型在另外一个地方又设计成了bigint,那么我们对应的代码中可能一个就是int类型另外一个地方就是Long类型。这样在实际编码的过程中就要去转换。
索引设计
聊到索引相信大家都不陌生,索引一般以索引文件的形式存储在磁盘上。我们一般所说的索引指的就是B+树结构组织的索引。接下来咱们简单聊一下不同层面的索引的划分,然后再来聊索引相关的设计规范。
索引的分类
根据存储类型划分
聚集索引:在数据库表中物理顺序和主键顺序一致,即数据行按照主键的顺序存储。只要找到第一个索引值记录,其余的连续记录在物理层存储层面一样是连续存放。为了使得表记录和索引的排列顺序一致,插入记录会重新排序,因此修改数据比较慢。
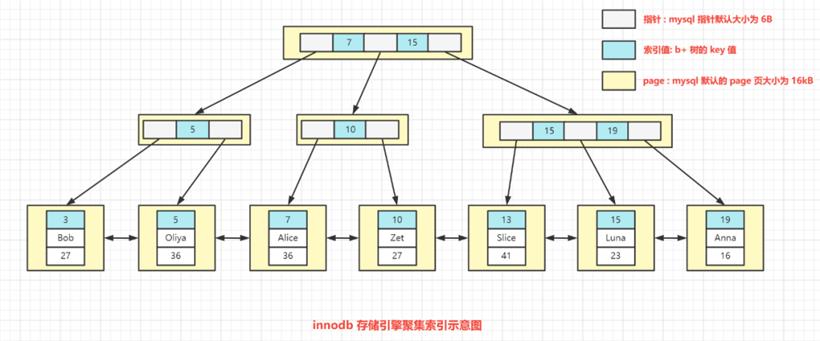
非聚集索引:表记录和索引的排列顺序不一定一致,非聚集索引的叶子层并不和实际数据页相重叠,而是采用叶子层包含一个指向表记录的指针。非聚集索引层次多,不会造成数据重排。
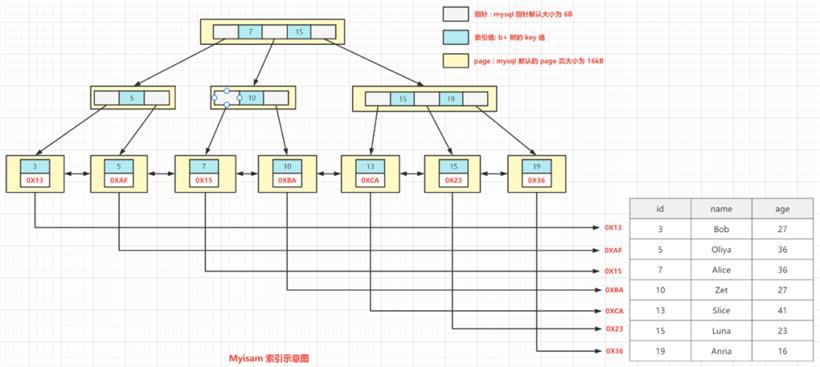
关于数据库的索引的详细介绍,老猫在此不做展开。后续会有专门的文章和大家分享。
根据逻辑划分
这块大家日常应用的过程中应该还是比较常见的。咱们可以分成以下几种类型。
主键索引:特殊的唯一索引,不允许有空值。
联合索引:多个字段上建立的索引,用来提升复合查询的效率。
普通索引:属于基本索引,没有其他限制。
唯一索引:和普通索引相似,但是值必须唯一,可以用空值,常用来做幂等。
索引命名规范
咱们在给索引命名的时候需要均用英文小写字母进行命名。
主键索引:一般命名用pk_字段名称(默认一般都是id索引,在创建表的时候一般就已经指定完成了)
普通索引:咱们命名的时候一般用idx_表名_字段名称或者idx_字段名称。
唯一索引:一般用uk_表名_字段名称或者uk_字段名称。
设计规范
1、不是所有的数据库字段都适合加索引的。我们在建立索引的时候需要评估字段的区分度。应该尽量避免将索引建立在区分度低的字段上。举个例子,例如性别:男女。还有日常业务中用到的状态值、或者status-是否标记等等。
2、应当避免在频繁更新的字段上建立索引。因为每次变更都会导致B+树发生变更,频繁的变更会导致数据库的性能大大降低。
3、我们需要控制一张表中索引的数量,索引数量并不是越多越好,单表建议控制在5个以内,当然这个也要结合表字段的总数来定并非绝对。索引创建过多会增加CPU以及IO的开销。虽然索引可以提高查询效率,但是同样会降低插入以及更新的效率。
4、创建联合索引的时候尽量避免冗余。例如(a,b,c)联合索引即相当于(a)、(a,b)、(a、b、c)。另外这里其实要提到索引的最左匹配原则。当查询的时候为(a)或者(a,b)或者(a,b,c)的时候才能走到索引。如果查询是(a,c)那么其实只能走到(a)索引,这个时候其实需要注意(a)的时候返回的数据量,如果过多的话,其实语句设计就是不合理的。如果查询是(b,c)则不能走索引。(面试官也比较喜欢问这类问题)
5、能使用唯一索引的场景,我们应该尽量去使用唯一索引。
6、如果一个字段的类型是varchar并且此时我们需要去建立相关的索引,我们此时必须要指定相关索引的长度,因为在前文中我们也提到了varchar类型存储的字符串长度往往是不固定的,如果是固定长度的咱们一般用char。我们完全没有必要对全字段建立索引,我们只要根据字段文本的区分度来建立索引即可。如下建立索引语句:
// 堆代码 duidaima.com
ALTER TABLE users ADD INDEX idx_email (email(10));
总结
当我们接到产品提的相关需求之后,我们就会开始进行相关的技术分析和设计,其中在设计阶段就会涉及基本的业务模型的设计。最终就是进行数据模型的设计。此时就会遇到上述的一些数据库设计的问题。
通过上述一些注意点,相信很多小伙伴应该知道数据表设计阶段的一些注意点了。如果小伙伴们还有一些需要补充的,也欢迎大家在评论区留言。分享是一种美德,大家一起进步。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






