一.现象
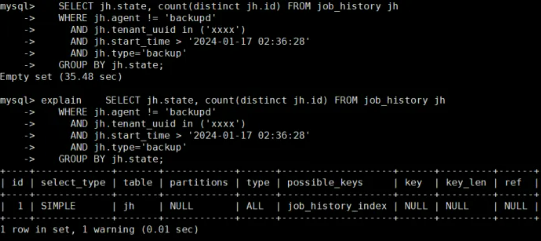
客户抱怨一个SQL执行时间很慢,测试了一下,这个SQL的执行时间为35秒,查询执行计划,没有用到索引。
 二.分析
二.分析
对这个SQL的where子句中的字段的选择性进行分析,发现除了start_time字段外,其他的字段选择性都不高。数据量比较大,近500万条记录,存储空间近2GB。
mysql> select min(start_time),max(start_time) from job_history;
+---------------------+---------------------+
| min(start_time) | max(start_time) |
+---------------------+---------------------+
| 2023-12-29 02:36:28 | 2024-01-19 06:44:01 |
+---------------------+---------------------+
1 row in set (0.02 sec)
mysql> show table status like 'job_history'\G
*************************** 1. row ***************************
Name: job_history
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 4819722
Avg_row_length: 376
Data_length: 1816133632
Max_data_length: 0
Index_length: 1232748544
Data_free: 108003328
Auto_increment: 4961289
Create_time: 2024-01-23 17:20:22
Update_time: NULL
Check_time: NULL
Collation: utf8mb4_bin
Checksum: NULL
Create_options:
Comment:
1 row in set (0.00 sec)
显然优化器没有使用索引的原因是索引的选择性不高,而走全表扫描更快。
三.优化
这个表的数据随着时间的推移递增插入的,因此id字段和start_time字段都是递增的,因此可以把大于start_time的条件转换成大于主键id的条件,让优化器通过主键对数据进行访问,也就是下面这个条件
start_time > '2024-01-17 02:36:28'
改写成一个等价的条件:
id>=(select max(id) from job_history where start_time < '2024-01-17 02:36:28')
测试一下改写后的SQL的运行效率:

可以看到执行时间减少到2.55秒,因为MySQL的所有表在底层存储时都是索引组织表,通过主键访问数据会比通过二级索引访问快很多。
总结
实际上,在能获得足够准确的信息的情况下,数据库的优化器通常会选择正确的执行路径,这时我们人为的干预(例如通过hint)改变SQL的访问路径通常会降低SQL的执行效率,也就是说这时人类是不可能战胜优化器的。所以,我们有时看到的人为改成SQL执行计划可以造成SQL执行效率大幅提升,这时的底层原因是因为优化器的获得的信息不准。因为数据库的优化器并不是面向一个特定的应用进行设计的,这样我们就有可能利用我们了解的特定应用的特点选择一个更优的访问路径,这个例子就是我们利用了id主键和start_time字段都是顺序增长的特点把对二级索引的访问变成对主键的访问,这样执行的效率就大幅提高了。


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






