

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

SELECT
name,
salary
FROM
People
WHERE
NAME IN ( SELECT DISTINCT NAME FROM population WHERE country = "Canada" AND city = "Toronto" )
AND salary >= (
SELECT
AVG( salary )
FROM
salaries
WHERE
gender = "Female")
这似乎似乎难以理解,但如果在查询中有许多子查询,那么怎么样?这就是CTEs发挥作用的地方。with toronto_ppl as (
SELECT DISTINCT name
FROM population
WHERE country = "Canada"
AND city = "Toronto"
)
, avg_female_salary as (
SELECT AVG(salary) as avgSalary
FROM salaries
WHERE gender = "Female"
)
SELECT name
, salary
FROM People
WHERE name in (SELECT DISTINCT FROM toronto_ppl)
AND salary >= (SELECT avgSalary FROM avg_female_salary)
现在很清楚,Where子句是在多伦多的名称中过滤。如果您注意到,CTE很有用,因为您可以将代码分解为较小的块,但它们也很有用,因为它允许您为每个CTE分配变量名称(即toronto_ppl和avg_female_salary)停止递归构件的终止条件
with org_structure as (
SELECT id
, manager_id
FROM staff_members
WHERE manager_id IS NULL
UNION ALL
SELECT sm.id
, sm.manager_id
FROM staff_members sm
INNER JOIN org_structure os
ON os.id = sm.manager_id
3.临时函数它可以防止重复,并允许您重用类似于使用Python中的函数的代码。
SELECT name
, CASE WHEN tenure < 1 THEN "analyst"
WHEN tenure BETWEEN 1 and 3 THEN "associate"
WHEN tenure BETWEEN 3 and 5 THEN "senior"
WHEN tenure > 5 THEN "vp"
ELSE "n/a"
END AS seniority
FROM employees
相反,您可以利用临时函数来捕获案例子句。# 堆代码 duidaima.com
CREATE TEMPORARY FUNCTION get_seniority(tenure INT64) AS (
CASE WHEN tenure < 1 THEN "analyst"
WHEN tenure BETWEEN 1 and 3 THEN "associate"
WHEN tenure BETWEEN 3 and 5 THEN "senior"
WHEN tenure > 5 THEN "vp"
ELSE "n/a"
END
);
SELECT name
, get_seniority(tenure) as seniority
FROM employees
通过临时函数,查询本身更简单,更可读,您可以重复使用资历函数!Initial table: +------+---------+-------+ | id | revenue | month | +------+---------+-------+ | 1 | 8000 | Jan | | 2 | 9000 | Jan | | 3 | 10000 | Feb | | 1 | 7000 | Feb | | 1 | 6000 | Mar | +------+---------+-------+ Result table: +------+-------------+-------------+-------------+-----+-----------+ | id | Jan_Revenue | Feb_Revenue | Mar_Revenue | ... | Dec_Revenue | +------+-------------+-------------+-------------+-----+-----------+ | 1 | 8000 | 7000 | 6000 | ... | null | | 2 | 9000 | null | null | ... | null | | 3 | null | 10000 | null | ... | null | +------+-------------+-------------+-------------+-----+-----------+5.EXCEPT vs NOT IN
除了几乎不相同的操作。它们都用来比较两个查询/表之间的行。所说,这两个人之间存在微妙的细微差别。首先,除了过滤删除重复并返回不同的行与不在中的不同行。同样,除了在查询/表中相同数量的列,其中不再与每个查询/表比较单个列。
+----+-------+--------+-----------+
| Id | Name | Salary | ManagerId |
+----+-------+--------+-----------+
| 1 | Joe | 70000 | 3 |
| 2 | Henry | 80000 | 4 |
| 3 | Sam | 60000 | NULL |
| 4 | Max | 90000 | NULL |
+----+-------+--------+-----------+Answer:
SELECT
a.Name as Employee
FROM
Employee as a
JOIN Employee as b on a.ManagerID = b.Id
WHERE a.Salary > b.Salary
7.Rank vs Dense Rank vs Row Number排名在观看的分钟数,不同观众的数量等观看的顶级视频。
SELECT Name
, GPA
, ROW_NUMBER() OVER (ORDER BY GPA desc)
, RANK() OVER (ORDER BY GPA desc)
, DENSE_RANK() OVER (ORDER BY GPA desc)
FROM student_grades
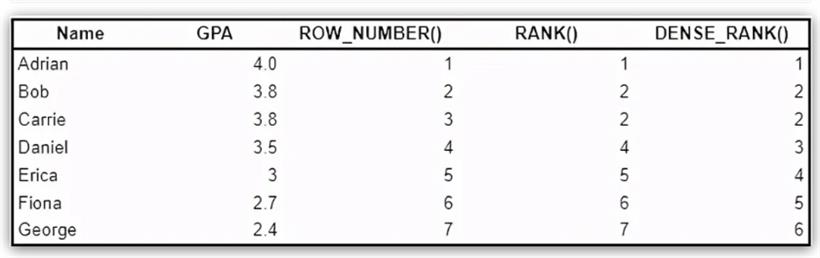
dense_rank()类似于等级(),除了重复等级后没有间隙。请注意,使用dense_rank(),Daniel排名第3,而不是第4位()。
# Comparing each month's sales to last month
SELECT month
, sales
, sales - LAG(sales, 1) OVER (ORDER BY month)
FROM monthly_sales
# Comparing each month's sales to the same month last year
SELECT month
, sales
, sales - LAG(sales, 12) OVER (ORDER BY month)
FROM monthly_sales
9.计算运行总数SELECT Month
, Revenue
, SUM(Revenue) OVER (ORDER BY Month) AS Cumulative
FROM monthly_revenue
10.日期时间操纵+---------+------------------+------------------+
| Id(INT) | RecordDate(DATE) | Temperature(INT) |
+---------+------------------+------------------+
| 1 | 2015-01-01 | 10 |
| 2 | 2015-01-02 | 25 |
| 3 | 2015-01-03 | 20 |
| 4 | 2015-01-04 | 30 |
+---------+------------------+------------------+Answer:
SELECT
a.Id
FROM
Weather a,
Weather b
WHERE
a.Temperature > b.Temperature
AND DATEDIFF(a.RecordDate, b.RecordDate) = 1





