我们都知道,在Mysql 中,如果数据量过大的话,就有可能在查询过程中会出现各种超时的情况,毕竟如果一个表的数据量过大的时候,一个简单的单表查询都会有点慢,所以,就有了各种中间件的存在,比如说 MyCat,ShardingJDBC 等分库工具,但是今天了不起不说这个,我们来说说这个Mysql自己的分区,我们不做分库操作。
Mysql数据分区
MySQL 的数据分区(Partitioning)是一个数据库功能,允许将一个表物理地分成多个独立的、更小的、更易于管理的片段,这些片段被称为分区。每个分区在逻辑上都是表的一部分,但在物理存储上,每个分区可以有自己的存储引擎、文件、索引等。
为什么要使用分区?
性能:对于某些查询,尤其是范围查询,分区可以显著提高性能,因为 MySQL 可以仅扫描需要的数据分区,而不是整个表。
管理:可以对单独的分区进行备份、删除或检查,这使得管理大型表变得更加容易。
归档:可以将旧数据移动到单独的分区,并轻松地从主表中删除这些分区,从而实现数据的归档。
如何进行分区?
MySQL 支持多种分区方法,包括:
RANGE 分区:基于列值的范围进行分区。
LIST 分区:基于列值的列表进行分区。
HASH 分区:基于用户定义的表达式的返回值的哈希值进行分区。
KEY 分区:类似于 HASH 分区,但 MySQL 服务器提供哈希函数。
COLUMNS 分区:是 RANGE 和 LIST 分区的扩展,允许基于多个列的值进行分区。
我们来详细说说这个分区的区别
RANGE分区
定义:基于属于一个给定连续区间的列值,把多行分配给分区。
用途:非常适合于基于时间范围的数据,如日志、交易记录等。
特点:
1.分区键必须是整数、日期或日期时间类型。
2.分区表必须至少包含一个RANGE分区。
3.每个RANGE分区都定义了一个值的范围,如 PARTITION p0 VALUES LESS THAN (100)。
限制:不支持外键和全文索引。
LIST分区
定义:类似于RANGE分区,但它是基于列值匹配一个离散值集合中的某个值来进行选择。
用途:当数据可以按照某个离散值列表进行分组时,如地域、类别等。
特点:分区键可以是整数或枚举类型。定义时指定一个值列表,如 PARTITION p1 VALUES IN (1, 3, 5)。
限制:与RANGE分区类似,不支持外键和全文索引。
HASH分区
定义:基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。
用途:当数据分布需要均匀或随机时,HASH分区可以确保数据在预先确定数目的分区中平均分布。
特点:
1.分区键可以是任何MySQL中的有效表达式,只要它返回非负整数值。
2.可以通过指定分区数量来控制数据的分布。
限制:不支持外键和全文索引。
KEY分区
定义:类似于HASH分区,但KEY分区的哈希函数是由MySQL服务器提供。
用途:与HASH分区类似,但使用MySQL内部的哈希函数。
特点:
1.分区键可以是一列或多列,但所有列都必须是整数类型。
2.MySQL服务器会处理列的哈希值,并将数据分配到不同的分区。
限制:与HASH分区相同,不支持外键和全文索引。
COLUMNS分区
定义:MySQL 5.5及以上版本支持基于多个列的分区,这被称为COLUMNS分区。
用途:允许根据多列的值进行分区,提供了更大的灵活性。
特点:
1.可以使用多个列作为分区键。
2.支持RANGE和LIST分区。
限制:与上述分区类型类似的限制。
我们来看一下个示例,假设我们有一个名为 sales 的表,它记录了销售数据,并且我们想要基于 sale_date 列进行 RANGE 分区。
CREATE TABLE sales (
sale_id VARCHAR(100) NOT NULL,
sale_name VARCHAR(100) NOT NULL,
amount DECIMAL(10, 2) NOT NULL,
dsYear VARCHAR(20) NOT NULL
)
PARTITION BY RANGE COLUMNS(dsYear) (
PARTITION p0 VALUES LESS THAN ('2021'),
PARTITION p1 VALUES LESS THAN ('2022'),
PARTITION p2 VALUES LESS THAN ('2023'),
PARTITION p3 VALUES LESS THAN ('2024')
);
在这个例子中,我们根据 dsYear 列的年份值将数据分成多个分区。注意 MAXVALUE 的使用,它表示最大的可能的值。如果我们进行了分区,那么就要在查询中适当的去增加分区查询条件,和分库是一样的,查询的时候需要命中分库规则,这样的话,就不会进行全表的扫描。然后我们创建一大笔数据,这样去查询一下,我们先来造数据,直接用存储过程来造数据,如果你使用的Navicat16,那你可以使用他自带的造数据的功能。
脚本如下:
# 堆代码 duidaima.com
CREATE DEFINER=`root`@`%` PROCEDURE `CreateTestData`()
BEGIN
DECLARE v_counter INT DEFAULT 1;
WHILE v_counter <= 1000000 DO
INSERT INTO sales(sale_id, sale_name, amount,dsYear)
VALUES(UUID_SHORT(), CONCAT('Data', v_counter), v_counter,'2021');
SET v_counter = v_counter + 1;
END WHILE;
END
我们这时候就可以通过查询是否命中分区来看一下查询速度了。不过这种创建数据的方式那可是非常的耗时间的。
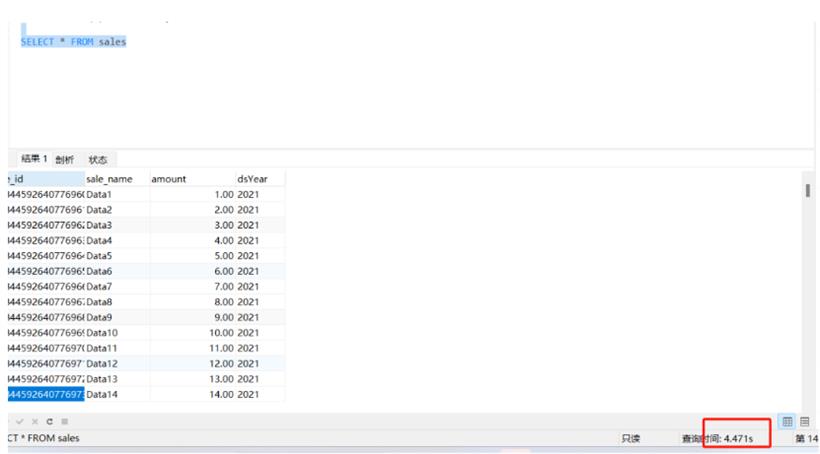
我们来对比一下查询分区和不涉及分区的情况
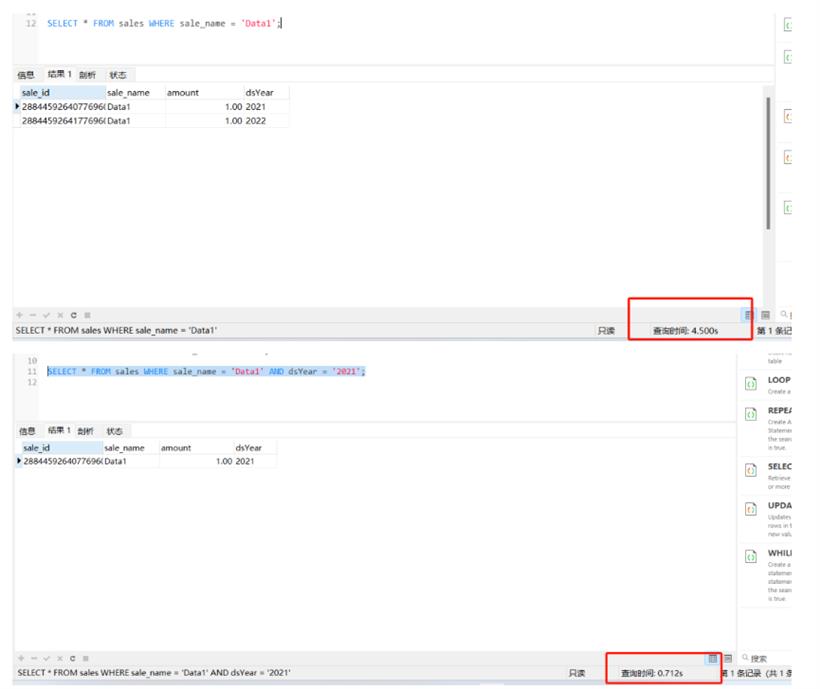
这个速度的差距明显就显现出来了,一共200w的数据,所以,利用好分区是非常有必要的。
注意事项:
1.不是所有的存储引擎都支持分区。例如,MyISAM 和 InnoDB 支持分区,但 MEMORY 存储引擎不支持。
2.分区键必须是表的一个列或表达式的组合,且必须是整数类型、返回整数值的表达式或 DATE/DATETIME 列。
3.分区表可能有一些限制和注意事项,例如,某些类型的索引可能不支持,或者某些查询优化可能不适用于分区表。因此,在决定使用分区之前,最好先详细了解这些限制和注意事项。
所以,你对Mysql 的分区了解了么?


 闽公网安备 35020302035485号
闽公网安备 35020302035485号






