

- 联系我们
- duidaima.com 版权声明
- 闽ICP备2020021581号
-
 闽公网安备 35020302035485号
闽公网安备 35020302035485号
闽公网安备 35020302035485号

SELECT DISTINCT column1, column2 FROM table_name;上面的查询将返回 column1 和 column2 组合的唯一结果。
SELECT column1, COUNT(*) FROM table_name GROUP BY column1;上面的查询将按 column1 分组,并返回每个分组中的行数。
SELECT DISTINCT department FROM employees;结果:

SELECT department FROM employees GROUP BY department;结果:

SELECT department, COUNT(*) FROM employees GROUP BY department;结果:
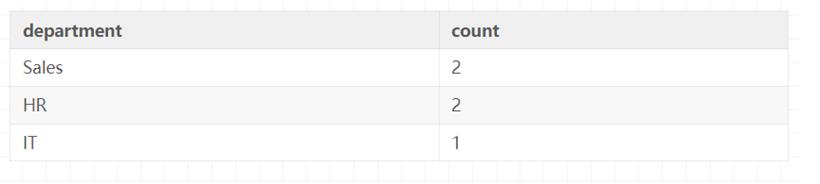
SELECT DISTINCT department FROM employees;当你仅仅需要去除查询结果中的重复行时。
当你不需要对结果进行分组或汇总时。
SELECT department, COUNT(*) FROM employees GROUP BY department;当你需要对结果进行分组,并对每个分组进行聚合操作时。
当你需要生成分组的汇总数据时。
2.如果你需要分组和汇总数据,选择 GROUP BY。
DISTINCT 和 GROUP BY 在 SQL 查询中具有不同的用途和适用场景。DISTINCT 主要用于去除重复行,而 GROUP BY 主要用于分组汇总。在选择使用哪种操作符时,应根据具体的需求进行选择。如果仅需要去重,建议使用 DISTINCT;如果需要进行分组和汇总操作,则应选择 GROUP BY。性能方面,DISTINCT 通常更高效,但在涉及复杂分组和聚合时,GROUP BY 可能更适合。





